爬虫学习--MOOC爬取豆瓣top250
Posted panpan0o
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习--MOOC爬取豆瓣top250相关的知识,希望对你有一定的参考价值。
scrapy框架
scrapy是一套基于Twisted的异步处理框架,是纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松实现一个爬虫,用来抓取网页内容或者各种图片。
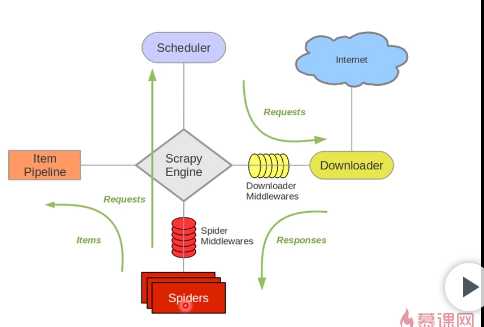
scrapy Engine:scrapy引擎
负责调度器,下载器,管道和爬虫之间的通讯信号和数据的传递,相当于交通站
Scheduler:调度器 简单来说就是一个队列,负责接受引擎发来的request请求,然后将请求排队,当引擎需要请求数据的时候,就将请求队列中的数据交给引擎。
Downloader:下载器
下载引擎发送过来的所有request请求,并将获得的response交还给引擎,再由引擎将response交还给Spider解析。
Item Pipeline:管道
管道组件,封装去重类,存储类的地方,负责处理spider中获取的数据,并进行后期处理。
Spiders:爬虫
spider是爬虫组件,Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。负责处理所有的response。
两个中间件:Downloader Minddlewares 下载中间件
封装代理,或者http头,隐藏我们自己的地方。下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response(也包括引擎传递给下载器的Request)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
一句话总结就是:处理下载请求部分
Spider Middlewares Spider中间件
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
一句话总结就是:处理解析部分
进入代码过程部分:
第一步
使用命令行进入你想要创建爬虫项目的目录键入命令:
scrapy startproject testdada
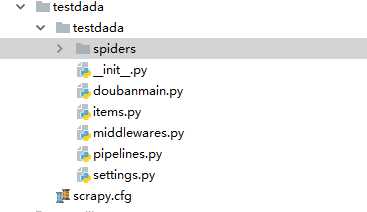

即会出现这样的目录。
第二步
进入spiders的这个目录
scrapy genspiders douban "movie.douban.com"
即创建了spiders下面出现这个douban.py要爬去的一些代码基本就写在里面
第三步
设置settings.py
加入这一句:
USER_AGENT = ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/62.0.3202.62 Safari/537.36‘
为什么要设置user-agent:有些网站不想被爬虫访问,所以会检测连接对象,这个可以模拟浏览器访问,防止被网站发现是爬虫程序。
第四步
编写代码
编写items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TestdadaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序号
serial_number = scrapy.Field()
# 电影的名称
movie_name = scrapy.Field()
# 电影的介绍
introduce = scrapy.Field()
# 星级
star = scrapy.Field()
# 电影的评论数
evaluate = scrapy.Field()
# 电影的描述
describe = scrapy.Field()
就是一些想要查询的一些信息
douban.py的编写
# -*- coding: utf-8 -*-
import scrapy
from ..items import TestdadaItem
class DoubanSpider(scrapy.Spider):
name = ‘douban‘
allowed_domains = [‘movie.douban.com‘]
start_urls = [‘http://movie.douban.com/top250‘]
#默认解析方法
def parse(self, response):
movie_list = response.xpath("//div[@class=‘article‘]//ol[@class=‘grid_view‘]//li")
for item in movie_list:
movieitem = TestdadaItem()
movieitem[‘serial_number‘] = item.xpath(".//div[@class=‘item‘]//div[@class=‘pic‘]//em//text()").extract_first()
movieitem[‘movie_name‘]=item.xpath(".//div[@class=‘info‘]//div[@class=‘hd‘]//a//span[1]//text()").extract_first()
#movieitem[‘introduce‘]=item.xpath(".//div[@class=‘bd‘]//p[1]/text()").extract_first()
content=item.xpath(".//div[@class=‘bd‘]//p[1]/text()").extract()
#遇到多行数据就进行处理
for i_content in content:
content_s="".join(i_content.split())
movieitem[‘introduce‘]=content_s
movieitem[‘star‘]=item.xpath(".//span[@class=‘rating_num‘]/text()").extract_first()
movieitem[‘evaluate‘]=item.xpath(".//div[@class=‘star‘]//span[4]/text()").extract_first()
movieitem[‘describe‘]=item.xpath(".//p[@class=‘quote‘]//span[1]/text()").extract_first()
#yield到管道里面去
#解析下一页,获得下一页的url,xpath获得
yield movieitem
next_link=response.xpath("//span[@class=‘next‘]/link/@href").extract()
if next_link:
next_link=next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
关于这个包的导入当时遇到了一点问题,解决了,参考的是下方网址:
https://blog.csdn.net/Haihao_micro/article/details/78529370
就是from ..items import TestdadaItem 这句
可以在命令行输:
scrapy crawl douban
来查看爬虫的运行,还可以创建一个doubanmain.py来可以直接在pycharm运行,内容如下:
doubanmain.py
from scrapy import cmdline
cmdline.execute(‘scrapy crawl douban‘.split())
于是直接运行doubanmain.py就行了。
于是爬取到了,豆瓣评分前250的电影,这是最后一个,爬取到的都是unicode字符串
运行结果:
https://movie.douban.com/top250?start=225&filter=>
{‘describe‘: u‘u73b0u4ee3u79d1u5e7bu7535u5f71u7684u5f00u5c71u4e4bu4f5cuff0cu6700u4f1fu5927u5bfcu6f14u7684u6700u4f1fu5927u5f71u7247u3002‘,
‘evaluate‘: u‘102672u4ebau8bc4u4ef7‘,
‘introduce‘: u‘1968/u82f1u56fdu7f8eu56fd/u79d1u5e7bu60cau609au5192u9669‘,
‘movie_name‘: u‘2001u592au7a7au6f2bu6e38‘,
‘serial_number‘: u‘250‘,
‘star‘: u‘8.7‘}
第五步
将数据导出为json或者csv
然后可以在命令行将爬取到的数据转换为json或者csv文件。
douban的意思是douban.py这个的文件名
scrapy crawl douban -o test.json
同理,把json换成csv就会导出csv文件了。
我得到的csv文件: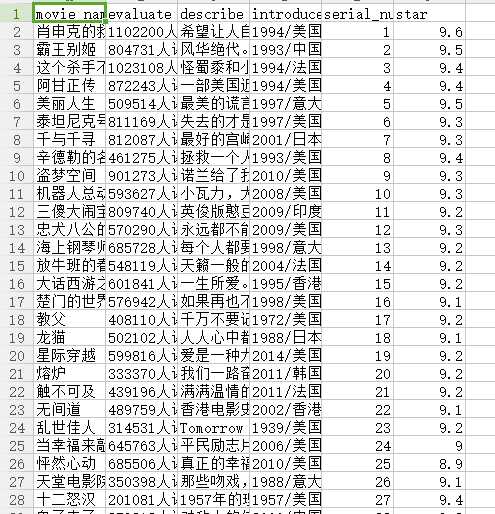
第六步
存到数据库
把csv文件存入mongdb数据库
pipelines.py的编写
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo from .settings import mongo_host,mongo_port,mongo_db_name,mongo_db_collection class TestdadaPipeline(object): def __init__(self): host=mongo_host port=mongo_port dbname=mongo_db_name sheetname=mongo_db_collection client=pymongo.MongoClient(host=host,port=port) mydb=client[dbname]#database self.post=mydb[sheetname]#集合名 def process_item(self, item, spider): data =dict(item) self.post.insert(data) return item
写完代码还不算完,一定一定要在settings.py加入:
ITEM_PIPELINES = { ‘testdada.pipelines.TestdadaPipeline‘: 300, }
否则根本不会运行这一段的代码。不会执行存数据库的操作。
好的,看看我们的mongodb数据库。
其他
ip代理中间件的编写:爬虫的伪装
因为如果不进行伪装的话,很有可能在爬取数据的时候被防火墙或者对方的安全设备发现使我们无法爬取到数据。
两种伪装方式:
1.设置代理ip
2.设置随机user-agent
通过设置request的meta属性来实现代理ip的使用。
class my_proxy(object): def process_request(self,request,spider): request.meta[‘proxy‘] = ‘http://your_proxy_ip:port‘ #加个b,加密,因为base64只能加密base类型的数据 proxy_name_pass = b‘username:password‘ #加密 encode_pass_name=base64.b64encode(proxy_name_pass) #注意这句的空格 request.headers[‘Proxy-Authorization‘]=‘Basic ‘+encode_pass_name.decode() class my_useragent(object): def process_request(self,request,spider): USER_AGENT_LIST = [ ‘MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23‘, ‘Opera/9.20 (Macintosh; Intel Mac OS X; U; en)‘, ‘Opera/9.0 (Macintosh; PPC Mac OS X; U; en)‘, ‘iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)‘, ‘Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)‘, ‘iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)‘, ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0‘, ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0‘, ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0‘, ‘Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)‘, ‘Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)‘ ] agent=random.choice(USER_AGENT_LIST) request.headers[‘User_Agent‘]=agent
别忘记了设置setting:
DOWNLOADER_MIDDLEWARES = { #‘testdada.middlewares.TestdadaDownloaderMiddleware‘: 543, ‘testdada.middlewares.my_proxy‘: 543, ‘testdada.middlewares.my_useragent‘ : 543, }
注意事项:
中间件定义完一定要在settings中启用
爬虫文件名和爬虫名称不能相同,spider目录内不能存爱相同爬虫名称的项目文件。
over!
以上是关于爬虫学习--MOOC爬取豆瓣top250的主要内容,如果未能解决你的问题,请参考以下文章