世界上第一个时序数据的Middle-Out算法压缩
Posted csdn研发技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了世界上第一个时序数据的Middle-Out算法压缩相关的知识,希望对你有一定的参考价值。
原文:The World’s First Middle-Out Compression for Time-series Data—Part 1
作者:Vaclav Loffelmann
翻译:无阻我飞扬
摘要:文章对缘起于HBO热门喜剧《硅谷》中虚拟的压缩算法给出了现实版,从Middle-Out算法压缩的特点、工作原理、压缩比和压缩性能等方面,讲述了这种算法压缩的优势,以下是译文。
Middle-Out算法压缩不再是HBO的热门喜剧《硅谷》里虚构的发明。在电视节目和新的向量指令集的启发下,我们提出了一种新的时序数据的无损压缩算法。压缩一直是关于速度和压缩比之间的一种折衷,当然也要在压缩和解压之间找到平衡,平衡这些权衡是很不容易的,但整个middle-out算法思想使得我们能够进一步推进Weissman score 这个衡量标准。

Middle-out压缩有什么特别之处?
它仅是打破数据的相关性。对于其它算法,如果需要一个先前的值来计算当前的值,我们需要 所有以前的值。但是Middle-out压缩算法从块的多个位置开始处理,它只依赖于这个片段中的先行值。所以说,这就使得我们能够有效地利用SIMD指令。
它是如何工作的呢?
原理上,该算法计算新值和前值的异或。这样可以获得两个值之间的一种差异,我们可以单独存储这种差异。在时序数据集中,这种差异通常有一些前导零异或以零拖尾。因此,我们需要存储的信息通常是极小的,但是我们也需要存储前导零个数和非零异或片段的长度。
这些思路通常用于当前的压缩算法,例如, Facebook’s Gorilla [1]。为了压缩效率,Gorilla以比特级别操作,但这些操作极具扩展性。我们设计的压缩要尽可能的快,所以变比特为字节颗粒度。因而,人们预期压缩比会更糟糕,但情况并非总是如此。
关于middle-out算法,压缩操作以数据块为级别,但这不是问题,因为时序数据库使用块存储。
压缩比如何?
让我们来看看两种不同情况下的压缩比。第一种情况——我们采取一连串的一点一点的增加(即0.1,0.2,0.3,…)并依据重复点的部分来衡量压缩比。为了进行比较,我们使用Facebook’s Gorilla算法压缩。默认情况下,Gorilla对时序数据值和时序数据的时间戳都进行压缩。为了达到我们测试的目的,时间戳压缩被禁用。

毫不奇怪地发现,对于这些类型的数据,Gorilla有更好的压缩比。我们可以看到长整数序列有相同的趋势。
第二种情况——数据集。数据集A和B共享同一分钟的股票数据。就数据集A来说,价格点压缩为浮点数。在数据集B中,这些数字都是先乘以小数点后位数,因此我们可以将这些数字看成长整数而不会失去精度。
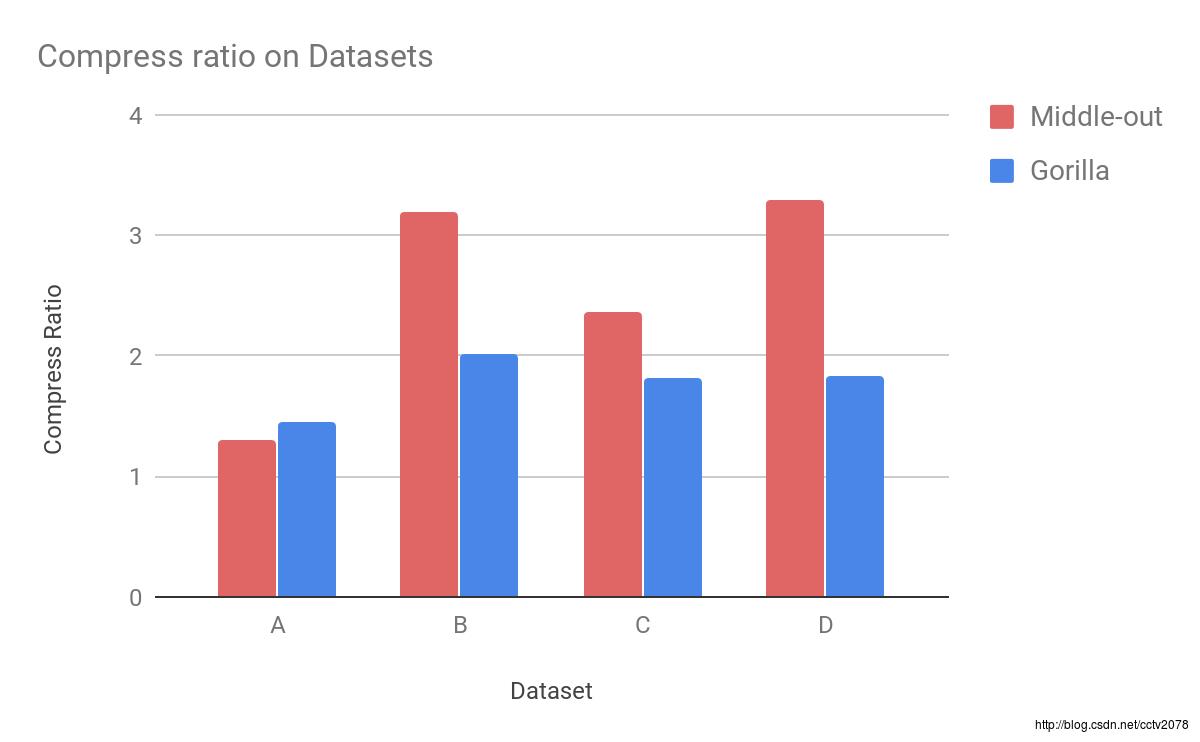
数据集C和D由来自InfluxData [2]的基准工具生成:代表磁盘写入和redis内存使用。就数据集A来说,Gorilla算法压缩数据略好于我们的算法——压缩比分别为1.45和1.3。其它的数据集使用整数,用我们的新算法可以更好的压缩。在数据集D中,可以看到最大的差异,用Middle-out算法的压缩比是3.3。而Gorilla算法压缩这些数据的压缩比仅有1.84。压缩比很大程度上取决于数据的输入,而且有些数据集很明显,其中一种算法要比另外一种算法压缩的更好。但是如果你关心性能——请继续阅读。
压缩性能
目前我们有两个兼容的实现算法。一个是利用在Skylake-X CPU上可用的一种新的avx-512指令集。第二种实现目标是计算机不支持这个指令集。
吞吐量是衡量在一个以2.0G赫兹运行的单核Skylake-X CPU性能的标准。
下面的图表显示了这两种实现方式的压缩和解压速度,与Facebook’s Gorilla算法进行比对。

这张图表显示了上面讨论的四个数据集上测量的压缩率,加上各自重复数据所占的百分比这一系列的吞吐量。
Gorilla压缩的吞吐量从120到440Mb/S不等,平均速度为180MB/S。我们的Scalar实现算法最低的吞吐量压缩速度大约是650MB/S,因为有50%的重复值。
这是由于高分支误预测率引起的。Scalar算法的平均压缩速度为1.27GB/s。因为一个使用向量指令的算法不会受分支误预测的影响,avx-512算法压缩数据速度从2.33 GB/s到 2.59 GB/s不等,平均速度为2.48 GB/s。对于一个单核2G赫兹的芯片来说,这速度不算差。
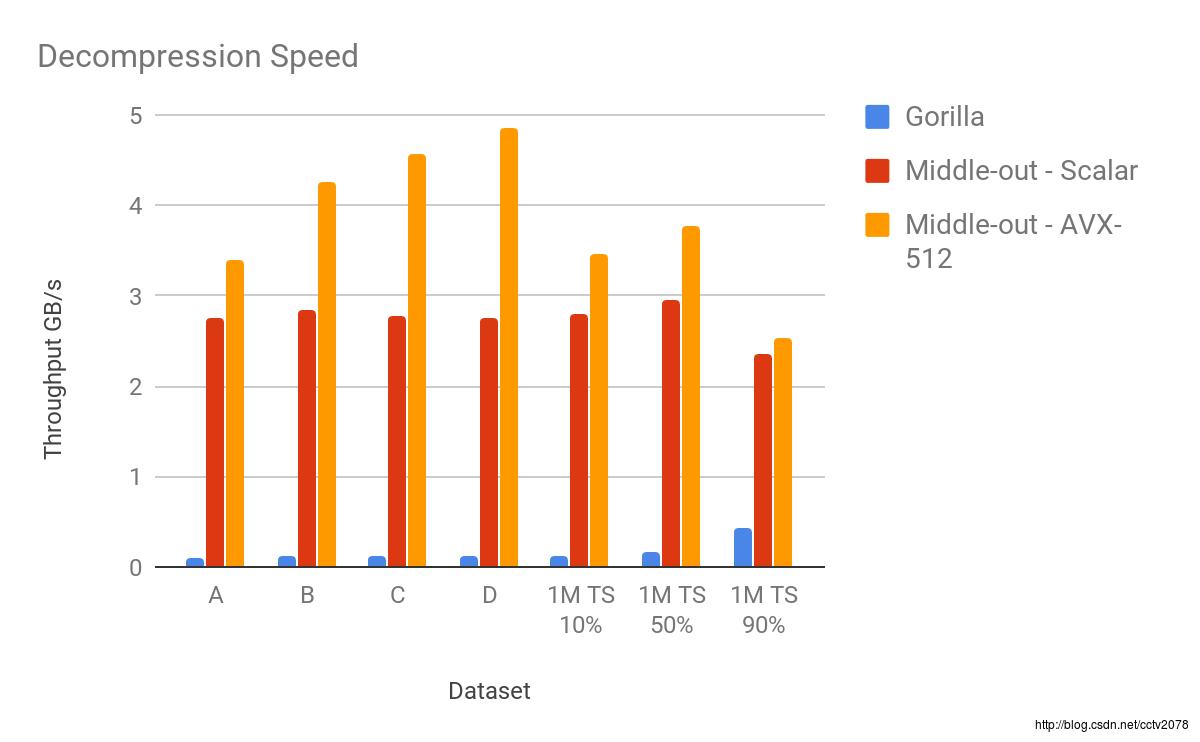
Gorilla算法解压这些数据的速度范围在100 MB/s 到430 MB/s 之间.但正如你所看到的,我们对相同数据的解压甚至比压缩更快。非向量化的解压以最小速度为2.36 Gb /s运行,平均速度为2.7 GB/s。向量化程序[代码]以2.54 GB/s的速度解压数据,在数据集D中,速度甚至高达4.86 GB/s。
压缩的平均整体增速是6.8倍(Scalar执行)和13.4倍(向量化执行)。各自的平均解压增速是16.1倍和22.5倍。
听起来很有趣?
如果想在你的产品中使用这种压缩算法,请给我们发邮件:info@schizofreny.com
或者如果你是开源维护者,那么有一个好消息告诉你:我们正计划我们的压缩算法可用于开源项目。
关于我们
我们Schizofreny致力于提高性能,我们相信极限会被进一步放大。我们喜欢挑战,是来帮助大家做高性能计算问题的。
[1] www.vldb.org/pvldb/vol8/p1816-teller.pdf
[2] https://github.com/influxdata/influxdb-comparisons/
以上是关于世界上第一个时序数据的Middle-Out算法压缩的主要内容,如果未能解决你的问题,请参考以下文章