mybatis二级缓存详解
Posted 51life
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mybatis二级缓存详解相关的知识,希望对你有一定的参考价值。
1 二级缓存简介
二级缓存是在多个SqlSession在同一个Mapper文件中共享的缓存,它是Mapper级别的,其作用域是Mapper文件中的namespace,默认是不开启的。看如下图:
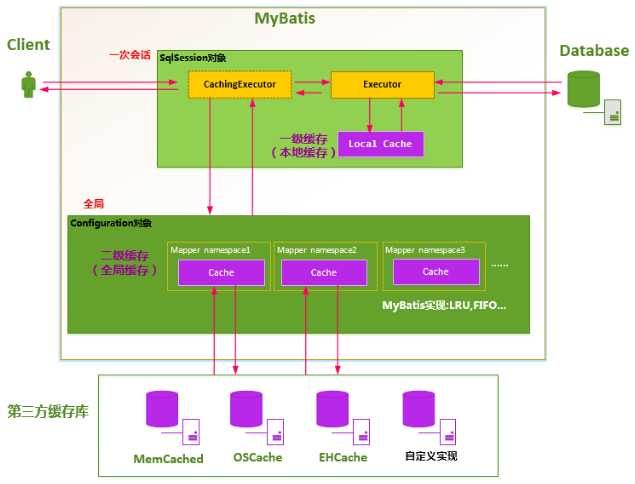
整个流程是这样的(不考虑第三方缓存库):
当开启二级缓存后,在配置文件中配置<setting name="cacheEnabled" value="true"/>这行代码,Mybatis会为SqlSession对象生成Executor对象时,还会生成一个对象:CachingExecutor,我们称之为装饰者,这里用到了装饰器模式。那么CachingExecutor的作用是什么呢?就是当一个查询请求过来时,CachingExecutor会接到请求,先进行二级缓存的查询,如果没命中,就交给真正的Executor来查询,再到一级缓存中查询,如果还没命中,再到数据库中查询。然后把查询到的结果再返回CachingExecutor,它进行二级缓存,最后再返回给请求方。它是executor的装饰者,增强executor的功能,具有查询缓存的作用。当配置<setting name="cacheEnabled" value="false"/>时,请求过来时,BaseExecutor这个抽象类会接到请求,就不进行二级缓存的查询。
如何开启二级缓存,分三步:
一是在配置文件中开启,这是开启二级缓存的总开关,默认是开启状态的:
<setting name="cacheEnabled" value="true"/>
二是在Mapper文件中开启缓存,默认是不开启的,需要手动开启:
<!-- 每个Mapper文件使用一个缓存对象 -->
<cache/>
<!-- 如果是多个Mapper文件共用一个缓存对象 -->
<cache-ref />
三是针对要查询的statement使用缓存,即在<select>节点中配置如下属性:
useCache="true"
对于二级缓存有以下说明:
- 映射语句文件中的所有 select 语句将会被缓存。
- 映射语句文件中的所有 insert,update 和 delete 语句会刷新缓存。
- 缓存会使用 Least Recently Used(LRU,最近最少使用的)算法来收回。
- 根据时间表(比如 no Flush Interval,没有刷新间隔), 缓存不会以任何时间顺序 来刷新。
- 缓存会存储列表集合或对象(无论查询方法返回什么)的 1024 个引用。
- 缓存会被视为是 read/write(可读/可写)的缓存,意味着对象检索不是共享的,而 且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
2 针对二级缓存的几种使用情况进行验证
情况1.update操作会刷新该namespace下的二级缓存
goodsMapper.selectGoodsById("1");
sqlSession.commit();
Goods goods = new Goods();
goods.setName("java");
goodsMapper3.updateGoodsById(goods);
sqlSession.commit();
goodsMapper2.selectGoodsById("1");
结果:
Created connection 1225268416. ==> Preparing: select * from goods where id = ? ==> Parameters: 1(String) <== Columns: id, name, detail, remark <== Row: 1, title1, null, null <== Total: 1 Opening JDBC Connection Created connection 283894520. ==> Preparing: update goods set name = ? where id = ? ==> Parameters: java(String), null <== Updates: 0 Cache Hit Ratio [com.yht.mybatisTest.dao.GoodsDao]: 0.0 Opening JDBC Connection Created connection 293891347. ==> Preparing: select * from goods where id = ? ==> Parameters: 1(String) <== Columns: id, name, detail, remark <== Row: 1, title1, null, null <== Total: 1
总结:第二次查询是从数据库中查询的,所以update操作刷新了缓存信息。但是要记得,sqlSessin.commit()操作,事务的提交。
情况2:如果在Mapper映射文件A.xml中涉及到B表的数据查询,那么当在B.xml中对B表进行更新操作时,此时A.xml中的缓存仍然存在,那么当再次使用A.xml中的SQL查询时,就会出现脏数据。如何解决这个问题呢,就可以使用<cache-ref>,使这两个Mapper映射文件共用一个cache对象。但是这样会引起一个问题:缓存的粒度变粗了,如果很多个Mapper映射文件共用一个Cache对象,那么该二级缓存就没有任何意义了。
3 源码分析:
为了说明二级缓存存储取出清除的整个过程,通过下面demo中代码的执行顺序来分析源码:
@Test public void selectGoodsTest(){
// 分三步进行源码分析: SqlSession sqlSession = getSqlSessionFactory().openSession(true); SqlSession sqlSession2 = getSqlSessionFactory().openSession(true); GoodsDao goodsMapper = sqlSession.getMapper(GoodsDao.class); GoodsDao goodsMapper2 = sqlSession2.getMapper(GoodsDao.class);
// 第一步:第一次查询 goodsMapper.selectGoodsById("1");
// 第二步:事务提交 sqlSession.commit(); // 第三步:第二次查询 goodsMapper2.selectGoodsById("1"); }
3.1 第一步:第一次查询
当配置二级缓存时,CachingExecutor会接到请求,调用它的query方法:先进行二级缓存的查询,如果没命中,再由BaseExecutor的query方法查询。看源码:
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 进行二级缓存的查询
// 此处的cache就是当mybatis初始化加载mapper映射文件时,如果配置了<cache/>,就会有该cache对象;下面会对MappedStatement这个类进行分析 Cache cache = ms.getCache(); if (cache != null) {
//是否需要刷新缓存,默认情况下,select不需要刷新缓存,insert,delete,update要刷新缓存 flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, parameterObject, boundSql); @SuppressWarnings("unchecked")
// 查询二级缓存,二级缓存是存放在PerpetualCache类中的HashMap中的,使用到了装饰器模式 List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) {
// 如果二级缓存没命中,则调用这个方法:这方法中是先查询一级缓存,如果还没命中,则会查询数据库 list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 把查询出的数据放到TransactionCache的entriesToAddOnCommit这个HashMap中,要注意,只是暂时存放到这里,只有当事务提交后,这里的数据才会真正的放到二级缓存中,后面会介绍这个 tcm.putObject(cache, key, list); // issue #578. Query must be not synchronized to prevent deadlocks } return list; } }
// 如果不使用缓存,则调用BaseExecutor的方法 return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
看下MappedStatement这个类的属性:
在加载Mapper映射文件中,每个节点信息<select>,<insert>,<delete>,<update>都被解析封装在了对应的一个MappedStatement对象中
private String resource; //就是该Mapper映射文件的全名 如:com/yht/mybatisTest/dao/goods.xml private Configuration configuration; // 全局唯一的配置文件对象,所有的配置文件信息都被封装到了这个对象中 private String id; // 该对象的唯一标识,也就是映射文件中每个方法的唯一标识,如:com.yht.mybatisTest.dao.GoodsDao.selectGoodsById private Integer fetchSize; private Integer timeout; private StatementType statementType; private ResultSetType resultSetType; private SqlSource sqlSource; // SqlSource接口的一个对象,这里也用到了装饰器模式,执行器链:RawSqlSource--》StaticSqlSource,然后StaticSqlSource封装了sql语句和参数信息 private Cache cache; // 如果在映射文件中配置了<cache/>,该对象就存在 private ParameterMap parameterMap; private List<ResultMap> resultMaps; private boolean flushCacheRequired; private boolean useCache;// 是否使用缓存,如果配置了<cache/>,就为true private boolean resultOrdered; private SqlCommandType sqlCommandType; private KeyGenerator keyGenerator; private String[] keyProperties; private String[] keyColumns; private boolean hasNestedResultMaps; private String databaseId; private Log statementLog; private LanguageDriver lang; private String[] resultSets;
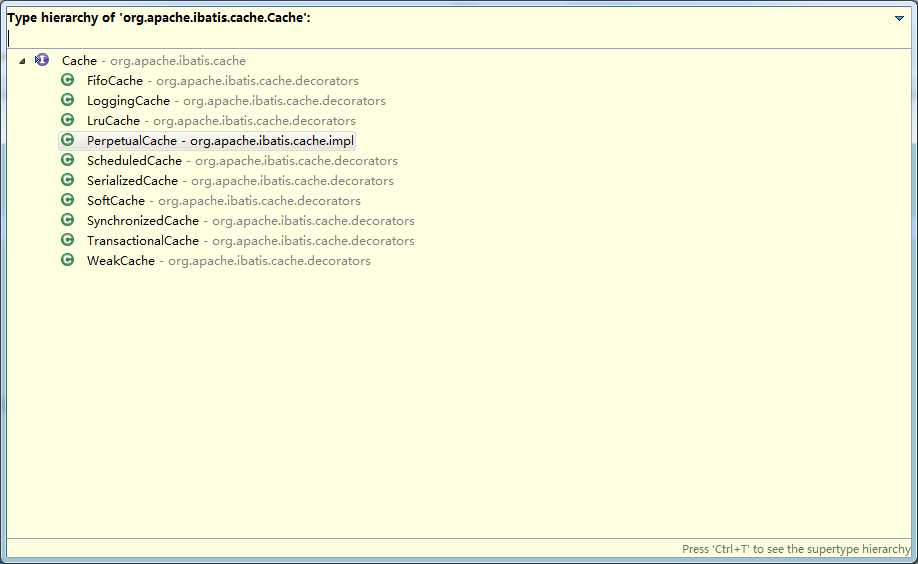
关于Cache接口,它有不同的实现类,各个实现类之间功能独立,互不影响,这里使用到了装饰器模式,它的子类结构图如下,至于各个类的作用在这里不做叙述。
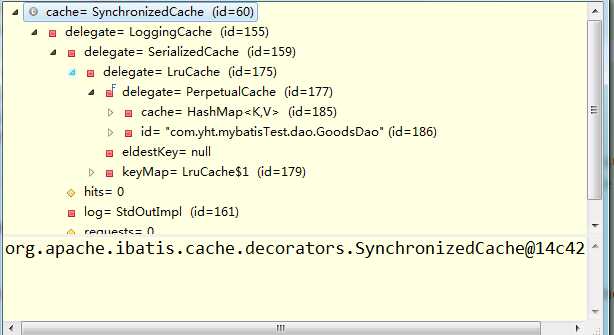
在这里,cache是怎样的结构呢?看下图可知,也是使用了装饰器模式,最终底层是使用了HashMap来维护:
进入flushCacheIfRequired(ms);方法,一探究竟:
private void flushCacheIfRequired(MappedStatement ms) { Cache cache = ms.getCache();
// 如果cache!=null && 需要刷新缓存,那就调用TransactionalCacheManager的clear方法,清空该缓存;对于TransactionalCacheManager类,后面会做介绍 if (cache != null && ms.isFlushCacheRequired()) { tcm.clear(cache); } }
现在就对这个TransactionalCacheManager做讲解,它是CachingExecutor类中的一个属性,CachingExecutor用它来对TransactionCache进行管理。它内部维护着一个transactionalCaches 属性,是一个HashMap,保存的是Cache和TransactionalCache的映射:
private Map<Cache, TransactionalCache> transactionalCaches = new HashMap<Cache, TransactionalCache>();
重点是TransactionalCache类,CachingExecutor使用它来包装刚生成的Cache,查询出的数据就是在这个类中的,但是此时并没有提交到二级缓存中,只是暂时存放到这里。看源码:
public class TransactionalCache implements Cache { private Cache delegate; private boolean clearOnCommit; private Map<Object, AddEntry> entriesToAddOnCommit; private Map<Object, RemoveEntry> entriesToRemoveOnCommit; //查询出来的数据就是放到这个HashMap中的 }
3.2 第二步:事务提交
现在我们知道,在第一次查询的时候,会把从数据库中查询的数据放到TransactionCache中,但这里并不是二级缓存存放数据的地方,那么二级缓存的数据什么时候怎么来的呢?这就要分析sqlSession.commit()这个方法了,这个方法就是把之前存放在TransactionCache中的数据提交到二级缓存中,然后清空该数据,看源码,TransactionalCacheManager类的commit方法:
public void commit() {
// 把涉及到的TransactionCache都进行处理:提交到二级缓存,并清空数据 for (TransactionalCache txCache : transactionalCaches.values()) { txCache.commit(); // 进入该方法 } }
public void commit() { if (clearOnCommit) { delegate.clear(); } else { for (RemoveEntry entry : entriesToRemoveOnCommit.values()) { entry.commit(); } }
// 把之前存放到entiriesToAddOnCommit中的数据提交到二级缓存中,具体的说是存放到PerpetualCache类的一个HashMap中 for (AddEntry entry : entriesToAddOnCommit.values()) {
// 进入该方法 entry.commit(); }
//清空该TransactionCache中的数据 reset(); }
进入entry.commit()方法:
public void commit() { cache.putObject(key, value); //放到PerpetualCache类中的HashMap中 }
到这里二级缓存的原理应该理解个大概了,总结下:当第一次从数据库中查出数据后,会放到TransactionCache类中;当调用sqlSession.commit()方法,进行事务提交后,TransactionCache中的数据会提交到PerpetualCache中,查询二级缓存的数据就是在这个类中,同时,TransactionCache中的数据会清空。
以上是关于mybatis二级缓存详解的主要内容,如果未能解决你的问题,请参考以下文章