HashMap 源码解析之使用构造以及计算容量
Posted homejim
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap 源码解析之使用构造以及计算容量相关的知识,希望对你有一定的参考价值。
简介
HashMap 是基于哈希表的 Map 接口的实现。 它的使用频率是非常的高。
集合和映射
作为集合框架中的一员,在深入之前, 让我们先来简单了解一下集合框架以及 HashMap 在集合框架中的位置。
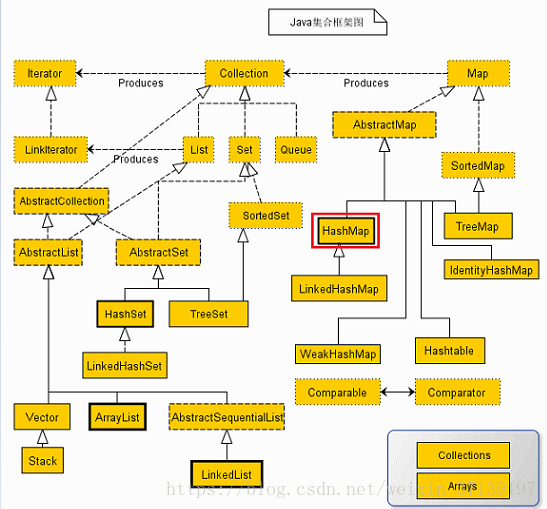
从图中可以看出
- 集合框架分为两种, 即集合(Collections)和映射(Map)
- HashMap 是 AbstractMap 的子类。而 AbstractMap 实现了 Map, 因此它有 Map 的特性。
- 通过Map接口, 可以生成集合(Collections)。
那集合(Collections)和映射(Map)是什么关系呢?
从图中我们可以看出, Map 和 Collection 是一种并行的关系。可以这么理解:
- 集合(Collectin)是一组单独的元素, 通常应用了某种规则。 List 是按特定顺序来存储元素, 而 Set 存储的是不重复的元素。
- 映射(Map)是一系列 “Key-Value” 的集合。
- 在 Map 中可以通过一定的方法产生 Collection。
HashMap 特点
很多时候, 我们都说, HashMap 具有如下的特点:
- 根据键的 HashCode 存储数据, 具有很快的访问速度;
- 此类不保证映射的顺序,特别是它不保证该顺序恒久不变;
- 允许键为 null, 但最多一条记录;
- 允许多条记录的值为 null;
- 线程不安全。
也许你现在对这些特点的印象还不够深刻, 在后续的源码解析过程中, 可以一一的见识庐山真面目。
使用
HashMap 的使用应该算是很简单的。有以下的方法时使用频率相对来说最高的。
| 方法名 | 作用 |
|---|---|
| V put(K key, V value) | 将指定的值与此映射中的指定键关联 |
| V get(Object key) | 返回指定键所映射的值;如果对于该键来说,此映射不包含任何映射关系,则返回 null。 |
| int size() | 返回此映射中的键-值映射关系数。 |
| V remove(Object key) | 从此映射中移除指定键的映射关系(如果存在)。 |
| Set<Map.Entry<K,V>> entrySet() | 返回此映射所包含的映射关系的 Set 视图。 |
| Set | 返回此映射中所包含的键的 Set 视图。 |
以下为一个示例
public void testHashMap() {
HashMap<String, String> animals = new HashMap<String, String>();
animals.put("Tom", "Cat");
animals.put("Tedi", "Dog");
animals.put("Jerry", "Mouse");
animals.put("Don", "Duck");
// 遍历方法1 键值视图
System.out.println("====================KeySet======================");
Set<String> names = animals.keySet();
for (String name:
names) {
System.out.println("KeySet: "+name+" is a " + animals.get(name));
}
// 通过 Entry 进行遍历
System.out.println("==================Entry========================");
Set<Map.Entry<String, String>> entrys= animals.entrySet();
for(Map.Entry<String, String> entry:entrys){
System.out.println("Entry: "+entry.getKey()+" is a " + entry.getValue());
}
animals.remove("Don");
// 通过 KeySet Iterator 进行遍历
System.out.println("======= KeySet Iterator after remove()=============");
Iterator<String > iter = animals.keySet().iterator();
while (iter.hasNext()) {
String name = iter.next();
String pet = animals.get(name);
System.out.println(" KeySet Iterator : "+name+" is a " + pet);
}
animals.clear();
// 通过 Entry Iterator 进行遍历
System.out.println("========== Entry Iterator after clear()==========");
Iterator<Map.Entry<String, String>> entryIter = animals.entrySet().iterator();
while (entryIter.hasNext()) {
Map.Entry<String, String> animal = entryIter.next();
System.out.println(" Entry Iterator : "+animal.getKey()+" is a " + animal.getValue());
}
}
以上的例子对 HashMap 的常用的基本方法进行了使用。
构造
相关属性
/**
* 最大容量, 当传入容量过大时将被这个值替换
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* HashMap的扩容阈值(=负载因子*table的容量),在HashMap中存储的Node键值对超过这个数量时,自动扩容容量为原来的二倍
*/
int threshold;
/**
* 这就是经常提到的负载因子
*/
final float loadFactor; 构造方法
HashMap 的构造方法有四个函数, 第四个暂且先不讲。 前三个基本最后基本都是为了初始化 initialCapacity 和 loadFactor 的。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}该方法是我们最常用的, 将 loadFactor 和 其余参数定义为默认的值。
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}当我们需要明确指出我们的容量和负载因子时, 使用该函数。
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}当我们需要明确指出我们的容量和负载因子时, 使用该函数。
public HashMap(int initialCapacity, float loadFactor) {
// 初始化的容量不能小于0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 初始化容量不大于最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 负载因子不能小于 0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}我们观察以上的三个构造构造函数, 发现在其中并没有对存储的对象 table 的初始化, 源码中也没有代码块进行初始化或者其他的。其实是延迟到第一次使用时进行初始化, 在 resize() 中进行了初始化。
在构造函数中,最值得我们深究的就是 tableSizeFor 函数。在初始化时,将这个函数的返回值赋给了 threshold , 并不是说 threshold 就等于这个值了, 在后续会从新计算 threshold 的
tableSizeFor 函数
该函数是获取大于或等于传入容量 initialCapacity 的2的整数次幂。 试想, 如果我们自己来实现这个函数应该怎么实现呢?
一般的算法(效率低, 不值得借鉴)
我们要计算比一个数距离最近的二次幂, 大多数人的想法,应该是一次取2的 0 次幂到 31 逐个与当前的数字进行比较, 第一个大于或等于的值就是我们想要的了。函数大致如下:
public int getNearestPowerOfTwo(int cap){
int num=0;
for (int i = 0; i < 31; i++) {
if ((num = (1 << i)) >= cap){
break;
}
}
return num;
}这是我随手写的, 还有很大的改进空间, 在这里就不深究了。
tableSizeFor 函数算法
而 HashMap 中的定义如下:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
我们先不说这个算法的原理, 来看和我之前的函数相比效率。
效率比较
public void compare(){
long start = System.currentTimeMillis();
for (int i = 0; i < (1 << 30); i++) {
getNearestPowerOfTwo(i);
}
long end = System.currentTimeMillis();
System.out.println((end-start));
long start2 = System.currentTimeMillis();
for (int i = 0; i < (1 << 30); i++) {
tableSizeFor(i);
}
long end2 = System.currentTimeMillis();
System.out.println((end2-start2));
}结果如下:
8094
2453
也就是时间上相比是 3.3 倍左右。接下来让我们看看其实现原理。
tableSizeFor 函数原理
核心思想
将该数的低位二进制位全部变为1, 并加1返回。
举个例子:
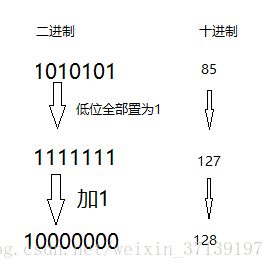
低位二进制全部变为1
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;其原理是:
首先, 我们忽略最高位之外的所有位数, 看图解说:

Step 1. 右移 1 位,并与之前的数做或运算。 则紧邻的后 1 位变成了 1. 而此时已经确定了 2 个 1, 因此下一次可以右移2位。
Step 2. 右移 2 位,并与之前的数做或运算, 则紧邻的后 2 也变成了 1. 而此时已经确定了 4 个 1, 因此下一次可以右移 4 位。
Step 3. 右移 4 位,并与之前的数做或运算, 则紧邻的后 4 位也变成了1. 而此时已经确定了8 个 1, 因此下一次可以右移 8 位。
...
依次类推, 最后右移了 31 位。
1 + 2 + 4 + 8 + 16 = 31;
由于 int 类型去掉符号位之后就只剩下 31 位了,因此, 右移了 31 位之后可以保证最高位后面的数字都为 1。
第一步为什么要 n = cap - 1?
如果不做该操作, 则如传入的 cap 是 2 的整数幂, 则返回值是预想的 2 倍。
以上是关于HashMap 源码解析之使用构造以及计算容量的主要内容,如果未能解决你的问题,请参考以下文章