VGGNet Note2
Posted Chowley
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VGGNet Note2相关的知识,希望对你有一定的参考价值。
小白的第一次英文论文之旅的补充,记录一下吧

Abstract
- 在这项工作中,研究了卷积网络深度对在大规模图像识别设置中准确性的影响。
- 主要贡献是使用具有非常小的 (3 × 3) 卷积滤波器的架构对增加深度的网络进行了全面评估,这表明通过将深度推到 16-19 个权重层,可以实现对先前配置的显着改进.
- 这些发现是作者在 ImageNet Challenge 2014 提交的基础,他们团队分别获得了本地化和分类轨道中的第一个和第二个位置。
- VGG可以很好地推广到其他数据集,取得了最先进的结果。
- 作者主要研究了在大规模图像识别设置中卷积网络深度对其准确性的影响。
Creative point
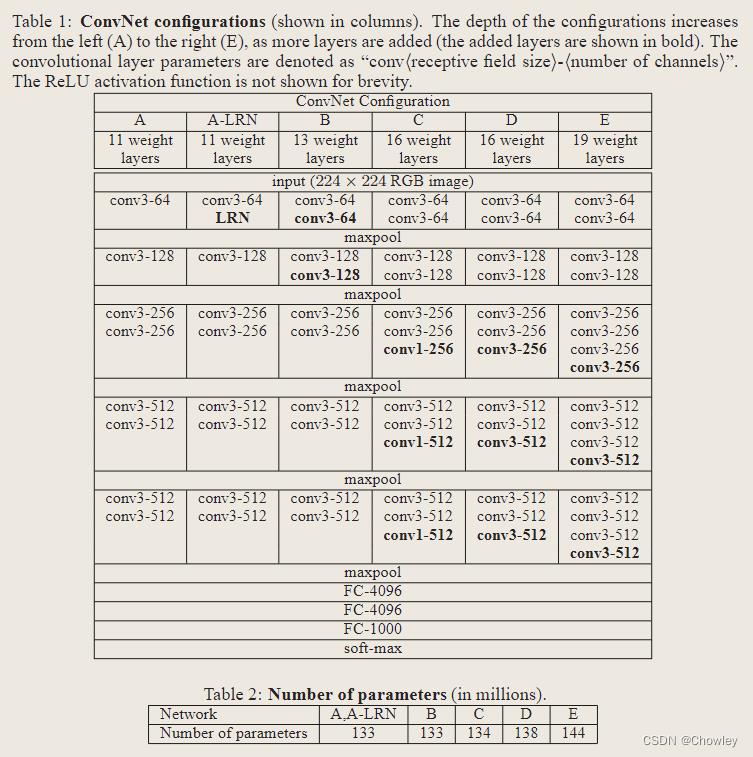
- 在训练过程中,ConvNets的输入是一个固定大小的224 × 224 RGB图像。我们所做的唯一预处理是从每个像素中减去平均RGB值(在训练集上计算) 图像通过一堆卷积(conv.)层,其中我们使用接收域非常小的滤波器:3 × 3
- 在其中一种配置中,他们还使用了1 × 1的卷积滤波器。前两个各有4096个通道,第三个执行1000路ILSVRC分类,因此包含1000个通道(每个类一个)。最后一层是软最大层。
- 批大小设置为256,动量设置为0.9。训练通过权重衰减(L2惩罚乘数设置为5·10e−4)和对前两个全连接层进行dropout正则化(dropout ratio设置为0.5)
- 学习速率最初设置为10e−2,然后当验证集准确性停止提高时,学习率降低10倍。总共降低了3次学习率,经过370K次迭代(74个epoch)后停止学习。
- 设置S的第二种方法是多尺度训练(multi-scale training),每个训练图像都是通过从一定范围[Smin, Smax](我们使用的是Smin = 256和Smax = 512)随机采样S来单独缩放。最后,为了获得固定大小的图像类分数向量,对类分数映射进行空间平均(和池)。
Models
Experiment
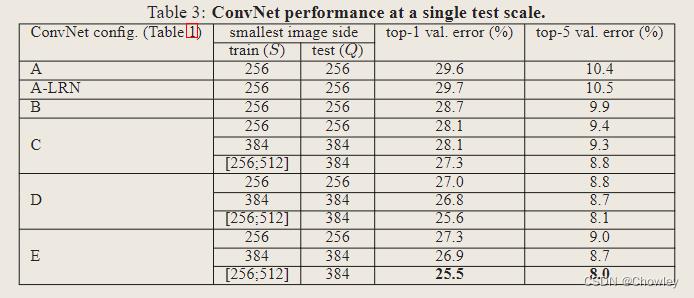
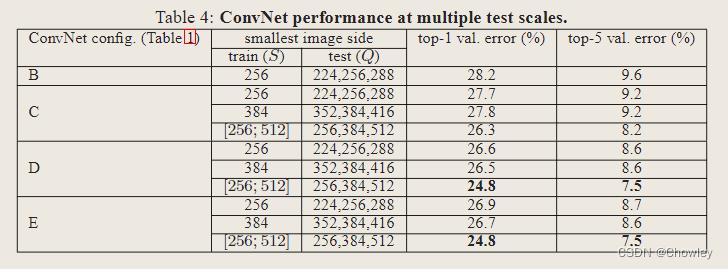
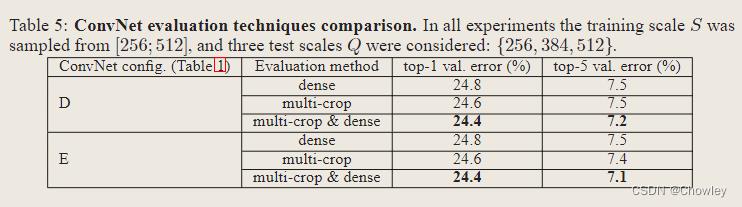

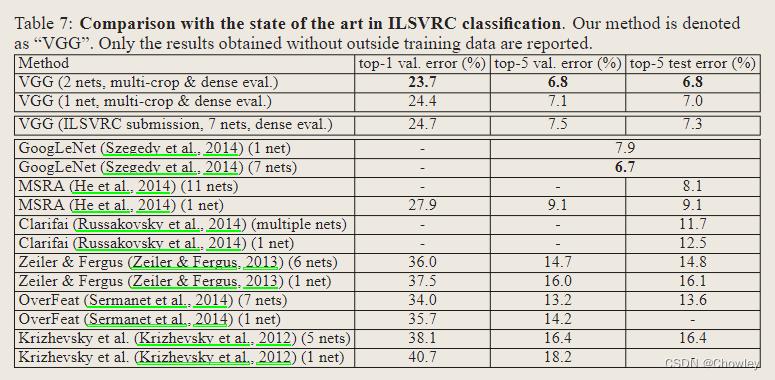
Evaluation and summary
1、结果再次证实了深度在视觉表现中的重要性
2、第一次这么长的英文论文,理解的不是太好
以上是关于VGGNet Note2的主要内容,如果未能解决你的问题,请参考以下文章