HashMap实现原理和源码分析
Posted shan-kylin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap实现原理和源码分析相关的知识,希望对你有一定的参考价值。
作者: dreamcatcher-cx
出处: <http://www.cnblogs.com/chengxiao/>
原文:https://www.cnblogs.com/chengxiao/p/6059914.html#undefined
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在页面明显位置给出原文链接。
哈希表
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,本文会对java集合框架中的对应实现HashMap的实现原理进行讲解,然后会对JDK7的HashMap源码进行分析。
什么是哈希表?
在介绍哈希表之间,先介绍一些其他常见的数据结构在增加,删除,和查找上的性能。
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)。
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)。
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
存储位置 = f(关键字)
其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:
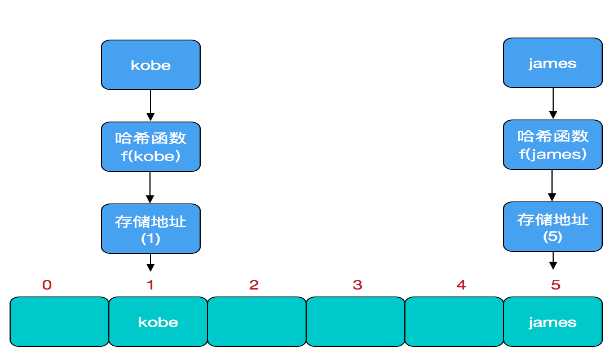
查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。
哈希冲突
然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?
哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式,
HashMap的实现原理
HashMap的主干是一个Entry类型名为table的数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对,Entry是HashMap中的一个静态内部类。
//HashMap的主干数组,可以看到就是一个Entry数组,初始值为空数组{},主干数组的长度一定是2的次幂,至于为什么这么做,后面会有详细分析。 transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
Entry静态内部类部分代码:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构 int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算 /** * Creates new entry. */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; }
HashMap的存储整体应该是这样的:
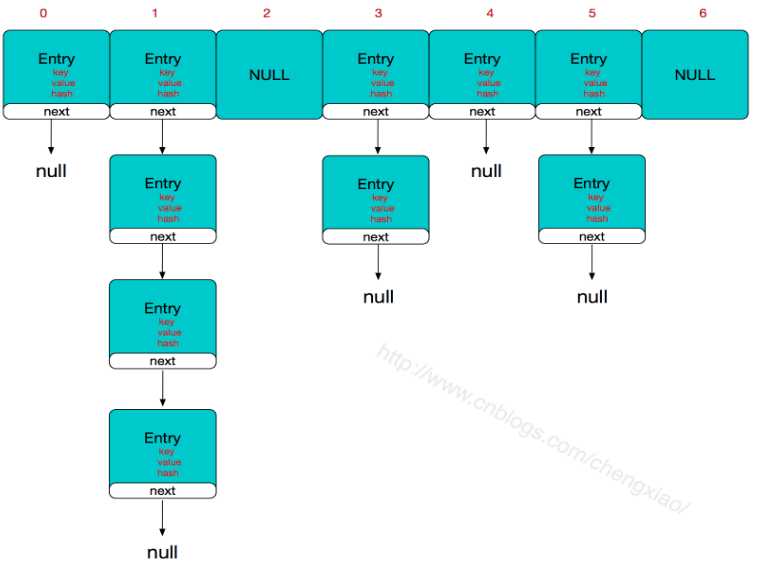
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
HashMap中的put方法:
public V put(K key, V value) { //如果table数组为空数组{},进行数组填充(为table分配实际内存空间),入参为threshold,此时threshold为initialCapacity 默认是1<<4(24=16) if (table == EMPTY_TABLE) { inflateTable(threshold); } //如果key为null,存储位置为table[0]或table[0]的冲突链上 if (key == null) return putForNullKey(value); int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀 int i = indexFor(hash, table.length);//获取在table中的实际位置 for (Entry<K,V> e = table[i]; e != null; e = e.next) { //如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++;//保证并发访问时,若HashMap内部结构发生变化,快速响应失败 addEntry(hash, key, value, i);//新增一个entry return null; }
解释:
第一次put数据的时候,会先创建名为table的entry类型的数组;默认长度是16,负载因子是0.75;
先判断传入的key是不是null,如果是null的话,就插入到索引值index为0的位置上,若已经存在数据,那么就会覆盖原来的数据,并且返回被覆盖数据。
如果key不为null;
1.使用int hash=hash(key.hashCode());获取hash值(ps:这个hash(Object k)是HashMap中的一个神奇的方法;多次使用了位运算以及二进制位的调整,来保证后面获取的index索引值尽可能的均匀分布);
2.再使用int index=indexFor(hash,table.length)来获取该key存放再table中的索引值(下标);因为不知道是否存在哈希冲突(也就是不知道该索引值对应的位置是否存在数据),所以遍历该索引值所对应的链表,判断是否存在相同的key(这里的‘相同’指的是:key的hash相同并且equals相同);如果相同则覆盖原来的数据并且返回被覆盖数据的value,如果最后没有发现相同的key,那么就插入数据到最后(哈希冲突的情况下)/直接插入到索引值对应的位置(不存在哈希冲突);并且返回null。
总的流程大概是这样的:

HashMap中的get方法:
public V get(Object key) { //如果key为null,则直接去table[0]处去检索即可。 if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
Entry中的GetEntry方法:
final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } //通过key的hashcode值计算hash值 int hash = (key == null) ? 0 : hash(key); //indexFor (hash&length-1) 获取最终数组索引,然后遍历链表,通过equals方法比对找出对应记录 for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
解析:
get方法是根据key值来获取value;首先判断传入的key是不是null,如果为null,那么就直接返回索引值index为0的值;如果不为空,调用getEntry方法,并且返回entry.getValue()值。
get方法的实现相对简单,key(hashcode)-->hash-->indexFor-->最终索引位置,找到对应位置table[i],再查看是否有链表,遍历链表,通过key的equals方法比对查找对应的记录。要注意的是,有人觉得上面在定位到数组位置之后然后遍历链表的时候,e.hash == hash这个判断没必要,仅通过equals判断就可以。其实不然,试想一下,如果传入的key对象重写了equals方法却没有重写hashCode,而恰巧此对象定位到这个数组位置,如果仅仅用equals判断可能是相等的,但其hashCode和当前对象不一致,这种情况,根据Object的hashCode的约定,不能返回当前对象,而应该返回null,后面的例子会做出进一步解释。
补充2个方法——hash()和indexFor()
hash()
//这是一个神奇的函数,用了很多的异或,移位等运算,对key的hashcode进一步进行计算以及二进制位的调整等来保证最终获取的存储位置尽量分布均匀 final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
indexFor()
/** * 返回数组下标 */ static int indexFor(int h, int length) { return h & (length-1); }
重写equals方法的同时一定要重写hashCode方法
我们再重写equals方法的时候,一定也要同时重写hashCode方法;下面演示只重写equals方法而不重写hashCode方法会出现什么情况。
/** * Created by chengxiao on 2016/11/15. */ public class MyTest { private static class Person{ int idCard; String name; public Person(int idCard, String name) { this.idCard = idCard; this.name = name; } @Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()){ return false; } Person person = (Person) o; //两个对象是否等值,通过idCard来确定 return this.idCard == person.idCard; } } public static void main(String []args){ HashMap<Person,String> map = new HashMap<Person, String>(); Person person = new Person(1234,"乔峰"); //put到hashmap中去 map.put(person,"天龙八部"); //get取出,从逻辑上讲应该能输出“天龙八部” System.out.println("结果:"+map.get(new Person(1234,"萧峰"))); } }
实际输出: null
如果我们已经对HashMap的原理有了一定了解,这个结果就不难理解了。尽管我们在进行get和put操作的时候,使用的key从逻辑上讲是等值的(通过equals比较是相等的),但由于没有重写hashCode方法,所以put操作时,key(hashcode1)-->hash-->indexFor-->最终索引位置 ,而通过key取出value的时候 key(hashcode2)-->hash-->indexFor-->最终索引位置,由于hashcode1不等于hashcode2,导致没有定位到一个数组位置而返回逻辑上错误的值null(也有可能碰巧定位到一个数组位置,但是也会判断其entry的hash值是否相等,上面get方法中有提到。)
所以,在重写equals的方法的时候,必须注意重写hashCode方法,同时还要保证通过equals判断相等的两个对象,调用hashCode方法要返回同样的整数值。而如果equals判断不相等的两个对象,其hashCode可以相同(只不过会发生哈希冲突,应尽量避免)。
以上是关于HashMap实现原理和源码分析的主要内容,如果未能解决你的问题,请参考以下文章