hive自定义函数(UDF)
Posted wakerwang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive自定义函数(UDF)相关的知识,希望对你有一定的参考价值。
首先什么是UDF,UDF的全称为user-defined function,用户定义函数,为什么有它的存在呢?有的时候 你要写的查询无法轻松地使用Hive提供的内置函数来表示,通过写UDF,Hive就可以方便地插入用户写的处理代码并在查询中使用它们,相当于在HQL(Hive SQL)中自定义一些函数,首先UDF必须用java语言编写,Hive本身就是用java写的.
编写UDF需要下面两个步骤:
1.继承org.apache.hadoop.hive.ql.UDF
2.实现evaluate函数,这个函数必须要有返回值,不能设置为void。同时建议使用mapreduce编程模型中的数据类型(Text,IntWritable等),因为hive语句会被转换为mapreduce任务。
看代码吧:
package hive;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.io.Text;
/**
* hive自定义函数,取多个字段的最小值;
*/
public class hiveUDF extends UDF {
public Text evaluate(Text string){
Text t ;
String s = "helloworld"+string;
t = new Text(s);
return t;
}
}
使用步骤:
1.首先将写好的UDF函数编译后的Java类打包成为一个JAR文件,并在Hive中注册这个文件
add jar /opt/hadoop/xxx.jar;
2.创建方法(退出hive shell后将失效)
create temporary function jasontest as ‘hive.hiveUDF‘;
然后就可以用这个自定义函数了,下面是查看的结果.
查看所有的函数:show functions like ‘*f*‘;
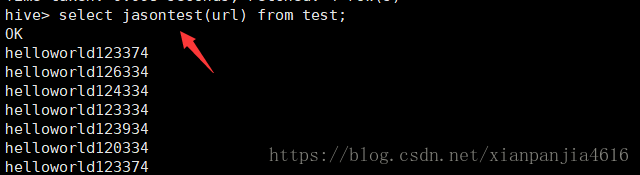
删除某一个函数:drop temporary function jasontest;
删除jar包:delete jar /home/hdfs/structuredstreaming-1.0-SNAPSHOT.jar;
这个方法只是暂时的,在退出hive的时候就不存在了,下次用的时候还需要在添加一遍.
以上是关于hive自定义函数(UDF)的主要内容,如果未能解决你的问题,请参考以下文章