机器学习:Kaggle 项目(房价:先进的回归技术)
Posted volcao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习:Kaggle 项目(房价:先进的回归技术)相关的知识,希望对你有一定的参考价值。
一、项目目录
- (一)数据加载
- 基础统计
- 特征分类
- 基本分布(scatter)
- (二)数据分析
- 正态性检验
- 偏离度分析 (hist | scatter)
- 峰度分析 (hist | scatter)
- 分散度分析 (box)
- 特征本身分散度
- SalePrice 的分散度
- 方差齐次检验
- 方差分析 (bar)
- scipy.stats.f_oneway()
- pandas.Series.corr()
- 协方差分析(-1~+1)
- 协方差热图 (heatmap)
- 协方最大关联图 (pairplot)
- 正态性检验
- (三)数据处理
- 无效数据处理
- 无效特征处理
- 离群点处理
- 缺失值处理
- NaN和NA的处理函数
- 数值量:min,max,mean
- 字符量 -- 仅做类型转换
- 标准化(Normalization)处理
- 离散量编码
- One-Hot Encoding
- 分组-均值-排序数值化
- 以SalePrice为参考的数据
- 没有房价可做基准的数据处理
- 无效数据处理
- (四)机器学习
- 模型
- MXNet
- pytorch
- TensorFlow
- PaddlePaddle
- 训练
- 炼丹
- 预测
- 模型
二、数据加载
1)将 train 数据集和 test 数据集合并
- 主要代码
all_data = pd.concat([train.loc[:,‘first_feature‘ : ‘last_feature‘], test.loc[:,‘first_feature‘ : ‘last_feature‘]])
- ‘first_feature‘:数据集的第一列,也就是第一种特征;
- ‘last_feature‘:数据集的最后一列,也就是最后一种特征;
-
注意:
- 合并数据集时,去掉 test 数据集的 “预测值:y” 对应的那一列;
- 合并目标:合并后的数据集的每一列都是特征,不含其它信息;train 数据集和 test 数据集都是 DataFrame 数据,如果数据集首列的 “Id”,合并后去除 “Id” 这一列;
-
查看合并之后的情况:
print(train.shape, test.shape, all_data.shape)
-
项目代码
- 加载模块
%matplotlib inline import numpy as np import pandas as pd import scipy as sp from scipy import stats from matplotlib import pyplot as plt import seaborn as sns
- 本机的各模块的版本最好与 Kaggle 一致
import sys print(sys.version) print(np.__version__) print(pd.__version__) print(sp.__version__)
- 加载数据
train = pd.read_csv("./kaggle/train.csv") test = pd.read_csv("./kaggle/test.csv") all_data = pd.concat([train.loc[:,‘MSSubClass‘:‘SaleCondition‘], test.loc[:,‘MSSubClass‘:‘SaleCondition‘]]) all_data = all_data.reset_index(drop=True)
# df_allX 少了 Id 和 SalePrice 两列 print(train.shape, test.shape, all_data.shape)

2)read_csv() 中如何处理 NA
- 通常确实的值默认为 NA
pd.read_csv(file,... na_values=None, keep_default_na=True, ...)
- na_values:遇到该参数指定的字符时,即解析为 np.NaN(float型),无论此列是 numeric 型还是 object 型。
- 默认值:
‘‘、‘#N/A‘、‘#N/A N/A‘、‘#NA‘、‘-1.#IND‘、‘-1.#QNAN‘、‘-NaN‘、‘-nan‘、‘1.#IND‘、‘1.#QNAN‘、‘N/A‘、‘NA‘、‘NULL‘、‘NaN‘、‘nan‘
- keep_default_na
- True:将csv 文件中的数字or字符串与 na_values 的 default 值进行匹配,命中即解析为 np.NaN
- False:
- na_values=[...] :与自定义的 na_values 匹配,命中即解析为 np.NaN
- na_values不赋值:不解析相关字符串,保留为原字符串,副作用:会把数值型的feature错误的认成 object 型 —— so,不可取
3)基础统计
-
train.describe()
-
describe() 方法的用法,参考:Pandas 和 Series 的 describe() 方法
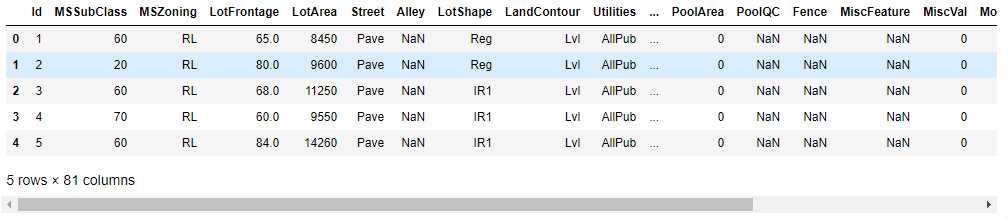
- 查看前五行的信息
train.head()
- 统计数据集
train.describe().T

4)特征分类
- 可以从不同的维度对特征进行分类:

-
非字符量特征(此项目中为 numeric features)、字符量特征(object featrues)
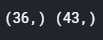
# 数值量特征 feats_numeric = all_data.dtypes[all_data.dtypes != ‘object‘].index.values # feats_numeric = [attr for attr in all_data.columns in all_data.dtypes[attr] != ‘boject‘] # 字符量特征 feats_object = all_data.dtypes[all_data.dtypes == ‘object‘].index.values # feats_object = [attr for attr in all_data.columns if all_data.dtypes[attr] == ‘object‘] # feats_object = train.select_dtypes(include = [‘object‘]).columns print(feats_numeric.shape, feats_object.shape)
-
总共79个特征,pandas自动识别的 36个数值量,43个字符量。 —— 这是上表中第一个维度; -
离散特征、连续特征
# 离散的数值量,需要人工甄别 feats_numeric_discrete = [‘MSSubClass‘, ‘OverallQual‘, ‘OverallCond‘]#户型、整体质量打分、整体条件打分 -- 文档中明确定义的类型量 feats_numeric_discrete += [‘TotRmsAbvGrd‘, ‘KitchenAbvGr‘, ‘BedroomAbvGr‘, ‘GarageCars‘, ‘Fireplaces‘]# 房间数量 feats_numeric_discrete += [‘FullBath‘, ‘HalfBoth‘, ‘BsmtHalfBath‘, ‘BsmtFullBath‘]# 浴室 feats_numeric_discrete += [‘MoSold‘, ‘YrSold‘]# 年份、月份,看成离散型特征 # 连续型特征 feats_continu = feats_numeric.copy() # 离散型特征 feats_discrete = feats_object.copy() for f in feats_numeric_discrete: feats_continu = np.delete(feats_continu, np.where(feats_continu == f)) feats_discrete = np.append(feats_discrete, f) print(feats_continu.shape, feats_discrete.shape)
# (22, ) (57, ):经过处理,得到表中第2个维度: 22个连续型特征,57个离散型特征;
5)基本分布(scatter)
- 绘图函数
def plotfeats(frame,feats,kind,cols=4): """批量绘图函数。 Parameters ---------- frame : pandas.DataFrame 待绘图的数据 feats : list 或 numpy.array 待绘图的列名称 kind : str 绘图格式:‘hist‘-直方图;‘scatter‘-散点图;‘hs‘-直方图和散点图隔行交替;‘box‘-箱线图,每个feat一幅图;‘boxp‘-Price做纵轴,feat做横轴的箱线图。 cols : int 每行绘制几幅图 """ rows = int(np.ceil((len(feats))/cols)) if rows==1 and len(feats)<cols: cols = len(feats) #print("输入%d个特征,分%d行、%d列绘图" % (len(feats), rows, cols)) if kind == ‘hs‘: #hs:hist and scatter fig, axes = plt.subplots(nrows=rows*2,ncols=cols,figsize=(cols*5,rows*10)) else: fig, axes = plt.subplots(nrows=rows,ncols=cols,figsize=(cols*5,rows*5)) if rows==1 and cols==1: axes = np.array([axes]) axes = axes.reshape(rows,cols) # 当 rows=1 时,axes.shape:(cols,),需要reshape一下 i=0 for f in feats: #print(int(i/cols),i%cols) if kind == ‘hist‘: #frame.hist(f,bins=100,ax=axes[int(i/cols),i%cols]) frame.plot.hist(y=f,bins=100,ax=axes[int(i/cols),i%cols]) elif kind == ‘scatter‘: frame.plot.scatter(x=f,y=‘SalePrice‘,ylim=(0,800000), ax=axes[int(i/cols),i%cols]) elif kind == ‘hs‘: frame.plot.hist(y=f,bins=100,ax=axes[int(i/cols)*2,i%cols]) frame.plot.scatter(x=f,y=‘SalePrice‘,ylim=(0,800000), ax=axes[int(i/cols)*2+1,i%cols]) elif kind == ‘box‘: frame.plot.box(y=f,ax=axes[int(i/cols),i%cols]) elif kind == ‘boxp‘: sns.boxplot(x=f,y=‘SalePrice‘, data=frame, ax=axes[int(i/cols),i%cols]) i += 1 plt.show()
-
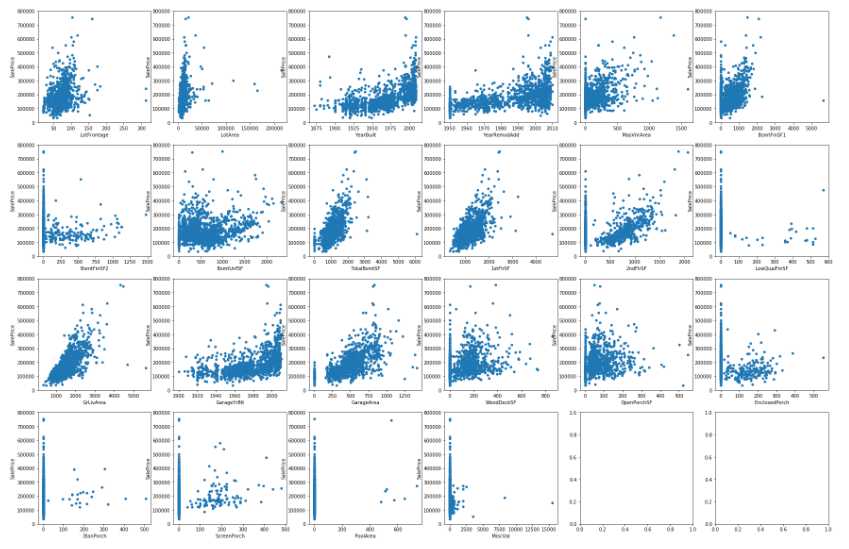
绘图:连续性特征与房价的关系
plotfeats(train, feats_continu, kind=‘scatter‘, cols=6)
-
分析上图
- LotFrontage、LotArea、GrLivArea、1stFlrSF、2stFlrSF、GarageArea、BsmtFinSF1、TotalBsmtSF: 这几个面积和距离和售价呈明显正相关趋势
- LotFrontage:房子到街道的距离,大多在50-100英尺(15-30米),距离远的是不是大多是豪宅?躲在山林深处……
- LotArea:占地面积(包括房屋、花园、前后院……),均值是10516平方英尺(900+平方米),向往啊……
- GrLivArea:地面以上整体面积
- 1stFlrSF、2stFlrSF: 第1、 2层建筑面积
- GarageArea:车库面积
- BsmtFinSF1、BsmtFinSF2、TotalBsmtSF:地下室面积,很多房子还有第2个地下室
- YearBuilt、YearRemodAdd、GarageYrBlt:从图中可以看出,建造年限对售价虽正相关,但坡度较小,关联度没有上面几个因素大,早点、晚点售价差不多
- 绘图:离散特征
以上是关于机器学习:Kaggle 项目(房价:先进的回归技术)的主要内容,如果未能解决你的问题,请参考以下文章