scrapy工作流程
Posted sharepy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy工作流程相关的知识,希望对你有一定的参考价值。
一:scrapy 工作原理介绍:
千言万语,不如一张图来的清晰:
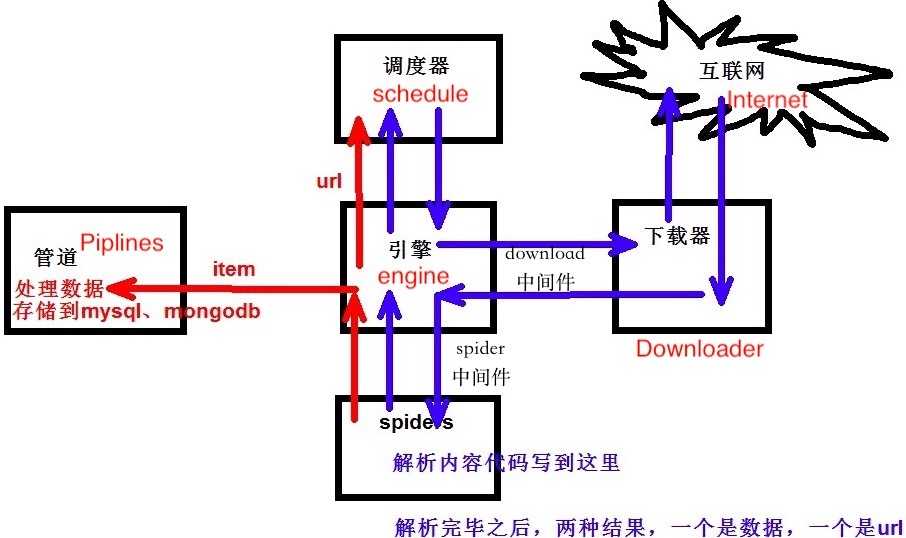
解释说明:
1、从优先级队列中获取request对象,交给engine
2、engine将request对象交给下载器下载,期间会通过downloadmiddleware的process_request方法
3、下载器完成下载,获得response对象,将该对象交给engine,期间会经过downloadmiddleware的process_response( )方法
4、engine将获得的response对象交给spider进行解析,期间会经过spidermiddleware的process_spider_input()的方法
5、spider解析下载器下下来的response,返回item或是links(url)
6、item或者link经过spidermiddleware的process_spider_out( )方法,交给engine
7、engine将item交给item pipeline ,将links交给调度器
8、在调度器中,先将requests对象利用scrapy内置的指纹函数生成一个指纹4
9、如果requests对象中的don‘t filter参数设置为False,并且该requests对象的指纹不在信息指纹的队列中,那么就把该request对象放到优先级队列中
循环以上操作
中间件:
中间件主要存在两个地方,从图片当中我们可以看到:
spider 与 engine 之间:
主要功能是在爬虫运行过程中进行一些处理.
download 与 engine 之间 :
主要功能在请求到网页后,页面被下载时进行一些处理.
作用:
1.Spider Middleware有以下几个函数被管理:
- process_spider_input 接收一个response对象并处理,
位置是Downloader-->process_spider_input-->Spiders(Downloader和Spiders是scrapy官方结构图中的组件)
- process_spider_exception spider出现的异常时被调用
- process_spider_output 当Spider处理response返回result时,该方法被调用
- process_start_requests 当spider发出请求时,被调用
2.Downloader Middleware有以下几个函数被管理
- process_request request通过下载中间件时,该方法被调用
- process_response 下载结果经过中间件时被此方法处理
- process_exception 下载过程中出现异常时被调用
以上是关于scrapy工作流程的主要内容,如果未能解决你的问题,请参考以下文章