Hadoop配置文件参数详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop配置文件参数详解相关的知识,希望对你有一定的参考价值。
Hadoop运行模式分为安全模式和非安全模式,在这里,我将讲述非安全模式下,主要配置文件的重要参数功能及作用,本文所使用的Hadoop版本为2.6.4。
etc/hadoop/core-site.xml
| 参数 | 属性值 | 解释 |
| fs.defaultFS | NameNode URI | hdfs://host:port/ |
| io.file.buffer.size | 131072 | SequenceFiles文件中.读写缓存size设定 |
范例:

1 <configuration> 2 <property> 3 <name>fs.defaultFS</name> 4 <value>hdfs://192.168.1.100:900</value> 5 <description>192.168.1.100为服务器IP地址,其实也可以使用主机名</description> 6 </property> 7 <property> 8 <name>io.file.buffer.size</name> 9 <value>131072</value> 10 <description>该属性值单位为KB,131072KB即为默认的64M</description> 11 </property> 12 </configuration>
etc/hadoop/hdfs-site.xml
- 配置NameNode
| 参数 | 属性值 | 解释 |
| dfs.namenode.name.dir | 在本地文件系统所在的NameNode的存储空间和持续化处理日志 | 如果这是一个以逗号分隔的目录列表,然 后将名称表被复制的所有目录,以备不时 需。 |
| dfs.namenode.hosts/ dfs.namenode.hosts.exclude |
Datanodes permitted/excluded列表 | 如有必要,可以使用这些文件来控制允许 数据节点的列表 |
| dfs.blocksize | 268435456 | 大型的文件系统HDFS块大小为256MB |
| dfs.namenode.handler.count | 100 | 设置更多的namenode线程,处理从 datanode发出的大量RPC请求 |
1 <configuration> 2 <property> 3 <name>dfs.replication</name> 4 <value>1</value> 5 <description>分片数量,伪分布式将其配置成1即可</description> 6 </property> 7 <property> 8 <name>dfs.namenode.name.dir</name> 9 <value>file:/usr/local/hadoop/tmp/namenode</value> 10 <description>命名空间和事务在本地文件系统永久存储的路径</description> 11 </property> 12 <property> 13 <name>dfs.namenode.hosts</name> 14 <value>datanode1, datanode2</value> 15 <description>datanode1, datanode2分别对应DataNode所在服务器主机名</description> 16 </property> 17 <property> 18 <name>dfs.blocksize</name> 19 <value>268435456</value> 20 <description>大文件系统HDFS块大小为256M,默认值为64M</description> 21 </property> 22 <property> 23 <name>dfs.namenode.handler.count</name> 24 <value>100</value> 25 <description>更多的NameNode服务器线程处理来自DataNodes的RPCS</description> 26 </property> 27 </configuration>
- 配置DataNode
| 参数 | 属性值 | 解释 |
| dfs.datanode.data.dir | 逗号分隔的一个DataNode上,它应该保存它的块的本地文件系统的路径列表 | 如果这是一个以逗号分隔的目录列表,那么数据将被存储在所有命名的目录,通常在不同的设备。 |
范例:
1 <configuration> 2 <property> 3 <name>dfs.datanode.data.dir</name> 4 <value>file:/usr/local/hadoop/tmp/datanode</value> 5 <description>DataNode在本地文件系统中存放块的路径</description> 6 </property> 7 </configuration>
etc/hadoop/yarn-site.xml
- 配置ResourceManager 和 NodeManager:
| 参数 | 属性值 | 解释 |
| yarn.resourcemanager.address | 客户端对ResourceManager主机通过 host:port 提交作业 | host:port |
| yarn.resourcemanager.scheduler.address | ApplicationMasters 通过ResourceManager主机访问host:port跟踪调度程序获资源 | host:port |
| yarn.resourcemanager.resource-tracker.address | NodeManagers通过ResourceManager主机访问host:port | host:port |
| yarn.resourcemanager.admin.address | 管理命令通过ResourceManager主机访问host:port | host:port |
| yarn.resourcemanager.webapp.address | ResourceManager web页面host:port. | host:port |
| yarn.resourcemanager.scheduler.class | ResourceManager 调度类(Scheduler class) | CapacityScheduler(推荐),FairScheduler(也推荐),orFifoScheduler |
| yarn.scheduler.minimum-allocation-mb | 每个容器内存最低限额分配到的资源管理器要求 | 以MB为单位 |
| yarn.scheduler.maximum-allocation-mb | 资源管理器分配给每个容器的内存最大限制 | 以MB为单位 |
| yarn.resourcemanager.nodes.include-path/ yarn.resourcemanager.nodes.exclude-path |
NodeManagers的permitted/excluded列表 | 如有必要,可使用这些文件来控制允许NodeManagers列表 |
1 <configuration> 2 <property> 3 <name>yarn.resourcemanager.address</name> 4 <value>192.168.1.100:8081</value> 5 <description>IP地址192.168.1.100也可替换为主机名</description> 6 </property> 7 <property> 8 <name>yarn.resourcemanager.scheduler.address</name> 9 <value>192.168.1.100:8082</value> 10 <description>IP地址192.168.1.100也可替换为主机名</description> 11 </property> 12 <property> 13 <name>yarn.resourcemanager.resource-tracker.address</name> 14 <value>192.168.1.100:8083</value> 15 <description>IP地址192.168.1.100也可替换为主机名</description> 16 </property> 17 <property> 18 <name>yarn.resourcemanager.admin.address</name> 19 <value>192.168.1.100:8084</value> 20 <description>IP地址192.168.1.100也可替换为主机名</description> 21 </property> 22 <property> 23 <name>yarn.resourcemanager.webapp.address</name> 24 <value>192.168.1.100:8085</value> 25 <description>IP地址192.168.1.100也可替换为主机名</description> 26 </property> 27 <property> 28 <name>yarn.resourcemanager.scheduler.class</name> 29 <value>FairScheduler</value> 30 <description>常用类:CapacityScheduler、FairScheduler、orFifoScheduler</description> 31 </property> 32 <property> 33 <name>yarn.scheduler.minimum</name> 34 <value>100</value> 35 <description>单位:MB</description> 36 </property> 37 <property> 38 <name>yarn.scheduler.maximum</name> 39 <value>256</value> 40 <description>单位:MB</description> 41 </property> 42 <property> 43 <name>yarn.resourcemanager.nodes.include-path</name> 44 <value>nodeManager1, nodeManager2</value> 45 <description>nodeManager1, nodeManager2分别对应服务器主机名</description> 46 </property> 47 </configuration>
- 配置NodeManager
| 参数 | 属性值 | 解释 |
| yarn.nodemanager.resource.memory-mb | givenNodeManager即资源的可用物理内存,以MB为单位 | 定义在节点管理器总的可用资源,以提供给运行容器 |
| yarn.nodemanager.vmem-pmem-ratio | 最大比率为一些任务的虚拟内存使用量可能会超过物理内存率 | 每个任务的虚拟内存的使用可以通过这个比例超过了物理内存的限制。虚拟内存的使用上的节点管理器任务的总量可以通过这个比率超过其物理内存的使用 |
| yarn.nodemanager.local-dirs | 数据写入本地文件系统路径的列表用逗号分隔 | 多条存储路径可以提高磁盘的读写速度 |
| yarn.nodemanager.log-dirs | 本地文件系统日志路径的列表逗号分隔 | 多条存储路径可以提高磁盘的读写速度 |
| yarn.nodemanager.log.retain-seconds | 10800 | 如果日志聚合被禁用。默认的时间(以秒为单位)保留在节点管理器只适用日志文件 |
| yarn.nodemanager.remote-app-log-dir | logs | HDFS目录下的应用程序日志移动应用上完成。需要设置相应的权限。仅适用日志聚合功能 |
| yarn.nodemanager.remote-app-log-dir-suffix | logs | 后缀追加到远程日志目录。日志将被汇总到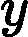 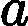 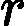 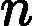   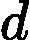 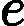  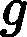 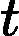 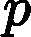 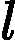 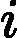  yarn.nodemanager.remote-app-logdir/{user}/${thisParam} 仅适用日志聚合功能。 yarn.nodemanager.remote-app-logdir/{user}/${thisParam} 仅适用日志聚合功能。 |
| yarn.nodemanager.aux-services | mapreduce-shuffle | Shuffle service 需要加以设置的Map Reduce的应用程序服务 |
1 <configuration> 2 <property> 3 <name>yarn.nodemanager.resource.memory-mb</name> 4 <value>256</value> 5 <description>单位为MB</description> 6 </property> 7 <property> 8 <name>yarn.nodemanager.vmem-pmem-ratio</name> 9 <value>90</value> 10 <description>百分比</description> 11 </property> 12 <property> 13 <name>yarn.nodemanager.local-dirs</name> 14 <value>/usr/local/hadoop/tmp/nodemanager</value> 15 <description>列表用逗号分隔</description> 16 </property> 17 <property> 18 <name>yarn.nodemanager.log-dirs</name> 19 <value>/usr/local/hadoop/tmp/nodemanager/logs</value> 20 <description>列表用逗号分隔</description> 21 </property> 22 <property> 23 <name>yarn.nodemanager.log.retain-seconds</name> 24 <value>10800</value> 25 <description>单位为S</description> 26 </property> 27 <property> 28 <name>yarn.nodemanager.aux-services</name> 29 <value>mapreduce-shuffle</value> 30 <description>Shuffle service 需要加以设置的MapReduce的应用程序服务</description> 31 </property> 32 </configuration>
etc/hadoop/mapred-site.xml
- 配置mapreduce
| 参数 | 属性值 | 解释 |
| mapreduce.framework.name | yarn | 执行框架设置为 Hadoop YARN. |
| mapreduce.map.memory.mb | 1536 | 对maps更大的资源限制的. |
| mapreduce.map.java.opts | -Xmx2014M | maps中对jvm child设置更大的堆大小 |
| mapreduce.reduce.memory.mb | 3072 | 设置 reduces对于较大的资源限制 |
| mapreduce.reduce.java.opts | -Xmx2560M | reduces对 jvm child设置更大的堆大小 |
| mapreduce.task.io.sort.mb | 512 | 更高的内存限制,而对数据进行排序的效率 |
| mapreduce.task.io.sort.factor | 100 | 在文件排序中更多的流合并为一次 |
| mapreduce.reduce.shuffle.parallelcopies | 50 | 通过reduces从很多的map中读取较多的平行 副本 |
1 <configuration> 2 <property> 3 <name> mapreduce.framework.name</name> 4 <value>yarn</value> 5 <description>执行框架设置为Hadoop YARN</description> 6 </property> 7 <property> 8 <name>mapreduce.map.memory.mb</name> 9 <value>1536</value> 10 <description>对maps更大的资源限制的</description> 11 </property> 12 <property> 13 <name>mapreduce.map.java.opts</name> 14 <value>-Xmx2014M</value> 15 <description>maps中对jvm child设置更大的堆大小</description> 16 </property> 17 <property> 18 <name>mapreduce.reduce.memory.mb</name> 19 <value>3072</value> 20 <description>设置 reduces对于较大的资源限制</description> 21 </property> 22 <property> 23 <name>mapreduce.reduce.java.opts</name> 24 <value>-Xmx2560M</value> 25 <description>reduces对 jvm child设置更大的堆大小</description> 26 </property> 27 <property> 28 <name>mapreduce.task.io.sort</name> 29 <value>512</value> 30 <description>更高的内存限制,而对数据进行排序的效率</description> 31 </property> 32 <property> 33 <name>mapreduce.task.io.sort.factor</name> 34 <value>100</value> 35 <description>在文件排序中更多的流合并为一次</description> 36 </property> 37 <property> 38 <name>mapreduce.reduce.shuffle.parallelcopies</name> 39 <value>50</value> 40 <description>通过reduces从很多的map中读取较多的平行副本</description> 41 </property> 42 </configuration>
- 配置mapreduce的JobHistory服务器
| 参数 | 属性值 | 解释 |
| maprecude.jobhistory.address | MapReduce JobHistory Server host:port | 默认端口号 10020 |
| mapreduce.jobhistory.webapp.address | MapReduce JobHistory Server Web UIhost:port | 默认端口号 19888 |
| mapreduce.jobhistory.intermediate-done-dir | /mr-history/tmp | 在历史文件被写入由MapReduce作业 |
| mapreduce.jobhistory.done-dir | /mr-history/done | 目录中的历史文件是由MR JobHistory Server管理 |
1 <configuration> 2 <property> 3 <name> mapreduce.jobhistory.address</name> 4 <value>192.168.1.100:10200</value> 5 <description>IP地址192.168.1.100可替换为主机名</description> 6 </property> 7 <property> 8 <name>mapreduce.jobhistory.webapp.address</name> 9 <value>192.168.1.100:19888</value> 10 <description>IP地址192.168.1.100可替换为主机名</description> 11 </property> 12 <property> 13 <name>mapreduce.jobhistory.intermediate-done-dir</name> 14 <value>/usr/local/hadoop/mr-history/tmp</value> 15 <description>在历史文件被写入由MapReduce作业</description> 16 </property> 17 <property> 18 <name>mapreduce.jobhistory.done-dir</name> 19 <value>/usr/local/hadoop/mr-history/done</value> 20 <description>目录中的历史文件是由MR JobHistoryServer管理</description> 21 </property> 22 </configuration>
Web Interface
| Daemon | Web Interface | Notes |
| NameNode | http://nn_host:port/ | 默认端口号50070 |
| ResourceManager | http://rm_host:port/ | 默认端口号8088 |
| MapReduce JobHistory Server | http://jhs_host:port/ | 默认端口号19888 |
以上是关于Hadoop配置文件参数详解的主要内容,如果未能解决你的问题,请参考以下文章