表栈和队列
Posted bigfly277
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了表栈和队列相关的知识,希望对你有一定的参考价值。
目录
本系列讨论最简单的和最基本的三种数据类型:表、栈和队列,实际上,每一个有意义的程序都将显式的用到一种或多种这样的数据结构,而栈在程序中总要被间接的使用到。
本系列的重点:
- 介绍抽象数据类型的概念。
- 阐述如何有效的执行表的操作。
- 介绍栈ADT及其在实现递归方面的应用。
- 介绍队列ADT及其在操作系统和算法设计中的应用。
- 在这一系列中会实现ArrayList 和LinkedList 的代码。
1、抽象数据类型
抽象数据类型(abstract data type,ADT)是带有一组操作的一些对象的集合。诸如表、集合、图以及他们各自操作一起形成的这些对象都可以被看成抽象数据类型,就像整数、实数、布尔数都是数据类型一样,他们各自都有与之相关的操作,而抽象数据类型也是如此。 对于集合ADT,可以有添加(add)、删除(remove)以及包含(cantain)这样一些操作,但是对于每一种ADT并不存在什么法则来告诉我们必须要有哪些操作,这一版都取决去程序的设计者。
2、表ADT
我们将处理形如A0,A1,A2,...,AN-1的一般的表。我们说这个表的大小是N,如果N=0,那我们称这个特殊的表为空表(empty list)。
对于除空表之外的任何表我们说Ai-1的后继是Ai,Ai的前驱是Ai-1,表中的第一个元素是A0,最后一个元素是AN-1,元素Ai在表中的位置是i+1。与这些定义相关的是要在表ADT上操作的集合,printList和makeEmpty是常用的操作,find返回某一项首次出现的位置,insert和remove一般是从表的某个位置插入和删除某个元素,findKth则返回(作为参数而被指定的)某个位置上的元素。如果34,23,11,45,34是一个表则find(11)会返回2,insert(x,2)则可以把表变成34,23,x,11,45,34,remove(11)则又会将表变成34,23,x,45,34。
当然一个方法怎么样才是恰当的完全由程序员自己来确定。比如find(1)会返回什么?或者我们可以添加一下操作比如next,previous他们取一个位置作为参数返回其后继元和前驱元。
2.1、表的简单数组实现
对于表的这些所有的操作都可以用数组来实现。虽然数组的长度是固定的,但是在必要的时候我们可以对数组进行扩容。
int[] arr = new int[10];
...
//创建一个新数组,长度是原数组长度乘以2的1次方也就是两倍
int[] newArr = new int[arr.length<<1];
//把老数组的复制到新数组
newArr = Arrays.copyOf(arr, arr.length);
数组的实现是printList以线性时间被执行,而findKth操作花费常数时间,这是我们能预期的,但是插入和删除却又昂贵的开销。最坏的情况在位置0处(表的最前端)插入首先要将整个数组后移一个位置以空出空间来,而删除一个第一个元素则需要将表中的所有的元素前移一个位置,存在许多情况,表是通过高端进行插入操作建立的,其后只会发生对数组的访问(只有findKth操作),在这种情况之下数组是表的一种恰当实现,然而,如果发生对表的一下插入和删除操作,特别是对表的低端操作,那么数组就不是一个很好的选择,这个时候我们就需要一个新的数据结构链表(linked list)
2.2、简单链表
为了避免插入和删除的线性开销,我们需要保证表可以不连续存储,否则表的每个部门的移动都可能造成整体的移动。

链表由一系列节点组成,这些节点不必再内存中相连,每一个节点都含有表元素和到后继元的节点的链(link),我们称之为next链,最后一个next链应用null。为了执行printList或者find(x),必须要从表的第一个节点开始然后用一些后继的next链遍历改表即可。findKth操作不如数组实现时效率高,findKth花费O(i)的时间并以这种明显的方式遍历链表完成的,remove方法可以通过修改一个next引用来实现,insert方法需要使用new操作从系统中取得一个新节点,此后执行两次引用的调整。
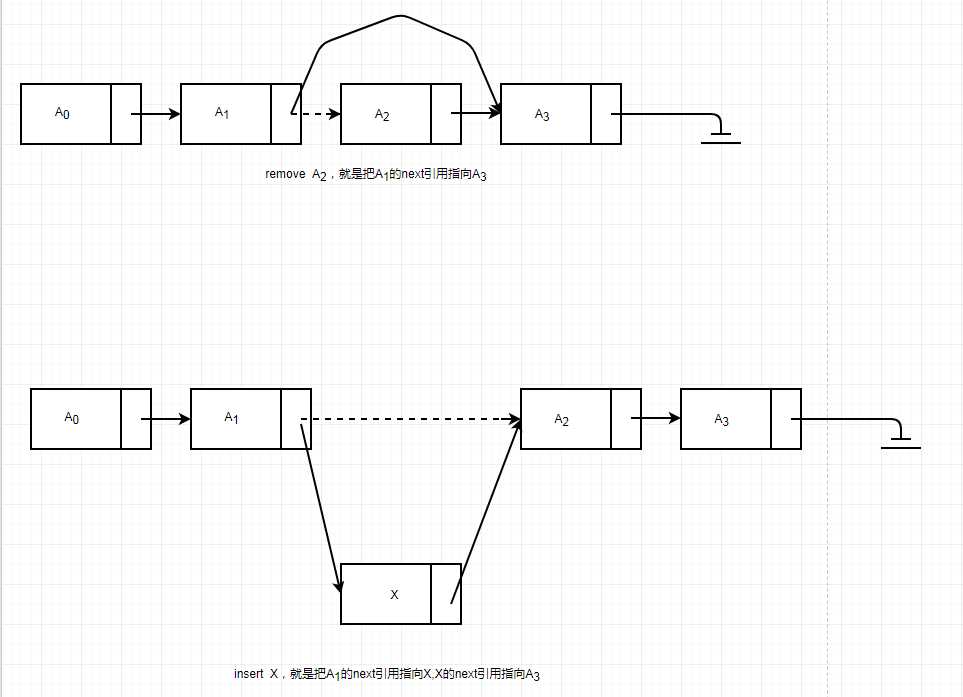
这样我们可以看到添加或者删除数据就不需要移动每一个数据了,但是如果要删除指定元素Ai,我们就需要把Ai-1的next引用指向Ai+1,我们都知道上面的链表我们可以通过Ai拿到Ai+1,但是我们不能通过Ai找到Ai-1,因为我们之前通过一个元素找他的后继元,但是找不到他的前驱元,所以我们就有了双向链表
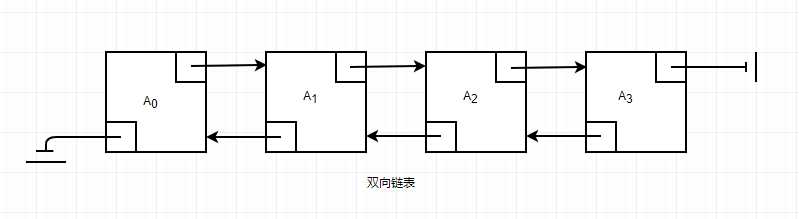
双向链表每一个数据元不但有当前数据和指向后继元素的next链,而且还有一个指向前驱元的previou链。这样我们可以通过一个数据元既可以找到他的后继又可以找到他的前驱。
3、Java Collections API中的表
3.1、Collection接口
??Collection API位于java.util包中,集合的概念在Collection接口中得到抽象,它存储一组类型相同的对象
public interface Collection<E> extends Iterable<E> {
int size();//返回集合中的项数
boolean isEmpty();//当且仅当集合的大小为0是返回true
void clear();//
boolean contains(Object o);//当集合包含o时返回true,但是它不规定怎么样才算包含, 具体包含的定义可以由他的实现类自己定义
boolean add(Object o);//添加数据成功返回true
boolean remove(Object o);//删除数据成功返回true
Iterator<E> iterator();
}上述方法都是该接口最重要的部分,Collection接口扩展了Iterable接口,实现Iterable接口的那些类可以使用增强for循环,该循环施于这些类之上以观察他们所有的项(2018年8月22日23:59:23)
因为Collection接口继承了Iterable接口,所以下面的代码可以打印任意集合中的所有的项
public static <T> void printColl(Collection<T> coll){
for(T item:coll){
System.out.println(item);
}
}3.2、Iterator接口
实现Interator接口必须提供一个称为iterator方法,这个方法返回一个Interator类型的对象
public interface Iterator<E>{
boolean hasNext();//有没有下一个
E next();//每次调用获取下一个元素,第一次调用给出第1项,第二次调用给出第2项
void remove();//移除next()方法返回的对象,以后我们就不能调用这个方法,知道下一次调用next才能使用这个方法
}所以删除用增强for遍历的方法其实是
public static<T> void printColl(Collection<T> coll){
Iterator<T> itr = coll.iterator();
while(itr.hasNext()){
T item = itr.next();
System.out.println(item);
}
}
Collection接口也包含一个remove方法,Iteraor的remove方法的主要优点在于,Collection的remove方法必须先找出要被删除的项。如果知道要删除项的位置,那么删除它的开销就 可能小的多,这个后面有机会写一个例子。当直接使用Interator(而不是用增强for间接使用)时候,如果正在被迭代的集合在结构上进行改变比如add,remove,clear方法时,那么迭代器就会不合法并且在后使用迭代器时候被抛出Concurrent-ModfificationException异常,这就意味着我们只有在立即需要使用的迭代器时候才会获取迭代器。然而迭代器调用自己的remove方法,那么这个迭代器依旧是合法的。这是我们有时候更愿意使用迭代器的remove方法的原因
3.3、List接口、ArrayList类和LinkedList类
List接口继承了Collection接口,所以他包含Collection接口所有的方法,另外它还外加了一些自己的方法。
public interface List<E> extends Collection<E> {
E get(int index);//获取指定位置上的元素
E set(int index,E e);//修改指定位置上的元素
void add(int index,E e);//在指定位置上添加一条新的元素
void remove(int index);//删除指定位置上的元素
}List ADT有两种实现方式,ArrayList类提供了List ADT的一种可增长数组的实现方式,使用ArrayList的有点在于对get和set调用花费常数时间,其缺点在于删除现有项或者新增项花费比较多的时间,除非在末端添加或者删除。LikedList类提供了List ADT的双向链表实现,使用LikedList的有点在于新增项和删除项花费时间较少(在一直变动项位置的前提下),这意味着在表的前端或者末端添加和删除时候用常数时间的操作,由此LinkedList提供了addFirst和removeFirst、addLast和removeLast以及getFirst和getLast等以有效添加删除访问表两端的数据项,使用LikedList的缺点是它不容易做索引,因此对get的调用花费时间较多。下面我们看一个例子
public static void makeList1(List<Integer> list,int N){
list.clear();
for (int i = 0; i < N; i++) {
list.add(i);
}
}
不管传递的参数是ArrayList 还是LinkedList,makeList 的运行时间都是O(N),因为add方法都是在表的末端添加数据,从而花费的都是常数时间(这里我们忽略ArrayList偶尔的扩容所花费的时间),现在我们通过在表的前端添加数据来构造一个List
public static void makeList2(List<Integer> list,int N){
list.clear();
for (int i = 0; i < N; i++) {
list.add(0,i);
}
}
那么对于LinkedList而言,他的运行时间依旧是O(N),但是对于ArrayList来说他的运行时间O(N2),因为在ArrayList中在前端添加一条数据要把后面所有的数据都要往后移动,光这个步骤花费的时间是O(N)。
下面我们来计算一个List中的数之和
public static int sum(List<Integer> list){
int total = 0;
for (int i = 0; i < list.size(); i++) {
total += list.get(i);
}
return total;
}这里ArrayList的运行时间是O(N),但对于LinkedList来说,其运行时间是O(N2),因为在LinkedList中,每一次调用get花费时间是O(N)。可是如果我们用的是增强for循环的话,那么它对任意List的运行时间都是O(N),因为迭代器将有效的从一项到下一项推进。
对搜索而言,ArrayList和LinkedList都是低效的。对于Collection的contains和remove方法调用均花费的是线性时间。
在ArrayList中有一个容量的概念,它表示基础数组的大小,在需要的时候,ArraList将自动增加其容量以保证它至少有表的大小。如果该大小的早期估计存在,那么ensureCapacity可以设置一个容量足够大的容量避免以后的扩容,再有trimToSize可以在所有的ArrayList添加操作完成之后使用避免浪费空间。
3.4、例子:remove方法对LinkedList类的应用
作为一个例子,我们先提出一个需求,将一个表中所有的偶数删除(如果表包含6,5,4,8,1,9,则在调用放过后表中只有5,1,9)。
这个需求对于ArrayList来说几乎是一个失败的策略,因为从一个ArrayList中几乎删除任意项都是非常昂贵的操作,但是在LinkedList中我们知道从已知位置删除可以通过重新安排链从而有效的完成。
想法一:
public static void removeEnentVer1(List<Integer> list){
int i = 0;
while (i < list.size()){
if(list.get(i) % 2 == 0 ){
list.remove(i);
}else{
i++;
}
}
}这个方法暴露了两个问题,首先LinkedList对get调用效率不高,其次对remove的调用同样不高,因为到达位置i的代价是昂贵的。
想法二:
public static void removeEnentVer2(List<Integer> list){
for (Integer itm : list) {
if(itm % 2 == 0){
list.remove(itm);
}
}
}这个方法我们不用get,而是用增强for,间接使用迭代器一步步遍历该表,这是高效率的,但是我们使用Collection的remove方法来删除,首先这不是一个高效的操作,因为remove方法必须先搜索到该项,它花费是线性时间,再次我们运行这个程序时发现会抛出异常,因为我们在一项被删除时,由增强for循环使用的基础迭代器是非法的。
想法三:
public static void removeEventVer3(List<Integer> list){
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()){
if(iterator.next()%2==0){
iterator.remove();
}
}
}这个想法是比较成功的,在迭代器找到一个偶数值项时候,我们可以使用迭代器的remove方法来删除刚刚看到的值,对于一个LinkedList而言,对该迭代器的remove方法调用只花费常数时间,因为迭代器就位于要被删除的节点。因此,对于LikedList整个程序花费的时间是线性的而不是二次的,而对于ArrayList即使迭代器位于要删除项的位置,remove方法仍然是昂贵的,因为删除一项数组后面的所有的数据都要向前移动一位,所以对于ArrayList而言整个程序所花费的时间还是二次的。
如果我们传递一个LikedList
3.5、关于ListInterator
ListIterator扩展了List的Iterator的功能,ListInterator和Iterator的区别:
- ListIterator有add()方法,可以向List中添加对象,而Iterator不能。
- ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历。但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator就不可以。
- ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现。Iterator 没有此功能。
- 都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现。Iterator仅能遍历,不能修改。因为ListIterator的这些功能,可以实现对LinkedList等List数据结构的操作。
public interface ListIterator<E> extends Iterator<E> {
boolean hasPrevious();//有没有前一项
E previous();//拿到前一项
void add(E e);//有next没有previous添加在第一位,既有next又有previous添加到它们之间,有previous没有next添加在最后
void set(E e);//修改
}(2018年8月23日23:28:00)
以上是关于表栈和队列的主要内容,如果未能解决你的问题,请参考以下文章