63-Django进阶(路由系统)
Posted druidchen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了63-Django进阶(路由系统)相关的知识,希望对你有一定的参考价值。
URL配置(URLconf)的本质是URL与要为该URL调用的视图函数之间的映射表。你就是以这种方式告诉Django,对于这个URL调用这段代码,对于那个URL调用那段代码。
1.1 URLconf配置
1.1.1 基本格式
1.11.x版本格式如下:
from django.conf.urls import url urlpatterns = [ url(正则表达式, views视图函数,参数,别名), ]
2.0版本格式如下:
from django.urls import path urlpatterns = [ path(‘articles/2003/‘, views.special_case_2003), path(‘articles/<int:year>/‘, views.year_archive), path(‘articles/<int:year>/<int:month>/‘, views.month_archive), path(‘articles/<int:year>/<int:month>/<slug:slug>/‘, views.article_detail), ]
1.1.2 参数说明
- 正则表达式:一个正则表达式字符串
- views视图函数:一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
- 参数:可选的要传递给视图函数的默认参数(字典形式)
- 别名:一个可选的name参数
1.2 正则表达式
1.2.1 基本配置
from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r‘^re1/‘, views.re_route1), # re1/xx/.../xx都能匹配成功 url(r‘^re2/$‘, views.re_route2), # 只有re2/才能匹配成功 url(r‘^re3/[0-9]{3}/$‘, views.re_route3), # 只有/re3/3位数字/这样才能匹配成功 url(r‘^re4/[0-9]{2,4}/$‘, views.re_route4), # 只有/re4/2~4位数字/这样才能匹配成功 url(r‘^re5/[a-zA-Z]{2,4}/[0-9]{2,4}/$‘, views.re_route5), # 只有/re5/2~4位字母/2~4位数字/这样才能匹配成功 ]
1.2.2 注意事项
- urlpatterns中的元素按照书写顺序从上往下逐一匹配正则表达式,一旦匹配成功则不再继续。
- 若要从URL中捕获一个值,只需要在它周围放置一对圆括号(分组匹配)。
- 不需要添加一个前导的反斜杠,因为每个URL 都有。例如,应该是^index 而不是 ^/index。
- 每个正则表达式前面的‘r‘ 是可选的但是建议加上。
1.2.3 补充说明
# 是否开启URL访问地址后面不为/跳转至带有/的路径的配置项 APPEND_SLASH=True
Django settings.py配置文件中默认没有 APPEND_SLASH 这个参数,但 Django 默认这个参数为 APPEND_SLASH = True。 其作用就是自动在网址结尾加‘/‘。
其效果就是,假如我们定义了urls.py如下:
from django.conf.urls import url from app01 import views urlpatterns = [ url(r‘^blog/$‘, views.blog), # 注意blog/后面的‘/‘,即访问blog时必须以‘/‘结尾 ]
访问 http://www.example.com/blog 时,默认将网址自动转换为 http://www.example/com/blog/ ,因此网站能正常访问。
如果在settings.py中设置了 APPEND_SLASH=False,此时我们再请求 http://www.example.com/blog 时就会提示找不到页面,必须手动添加/,即http://www.example.com/blog/
1.3 分组命名匹配
可以使用分组命名匹配的正则表达式组来捕获URL中的值并以关键字参数形式传递给视图。
在Python的正则表达式中,分组命名正则表达式组的语法是(?P<name>pattern),其中name是组的名称,pattern是要匹配的模式。
from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r‘^re1/‘, views.re_route1), # re1/xx/.../xx都能匹配成功 url(r‘^re2/$‘, views.re_route2), # 只有re2/才能匹配成功 url(r‘^re3/(?P<id>[0-9]{3})/$‘, views.re_route3), # 只有/re3/3位数字/这样才能匹配成功 url(r‘^re4/(?P<id>[0-9]{2,4})/$‘, views.re_route4), # 只有/re4/2~4位数字/这样才能匹配成功 url(r‘^re5/(?P<name>[a-zA-Z]{2,4})/(?P<id>[0-9]{2,4})/$‘, views.re_route5), # 只有/re5/2~4位字母/2~4位数字/这样才能匹配成功 ]
这个实现与1.2.1的示例完全相同,只有一个细微的差别:捕获的值作为关键字参数而不是位置参数传递给视图函数。
例如,针对url /re5/publisher/10/ 采用分组命名匹配的函数写法如下:
def re_route5(request, name, id): print(name) print(id) return HttpResponse("路由正则表达式测试5!")
而对于采用分组匹配的函数写法如下:
def re_route5(request, arg1, arg2): print(arg1) print(arg2) return HttpResponse("路由正则表达式测试5!")
1.3.1 URLconf匹配的位置
URLconf 在请求的URL 上查找,将它当做一个普通的Python 字符串。不包括GET和POST参数以及域名。
例如,http://www.example.com/myapp/ 请求中,URLconf 将查找myapp/。
在http://www.example.com/myapp/?page=3 请求中,URLconf 仍将查找myapp/。
URLconf 不检查请求的方法。换句话讲,所有的请求方法 —— 同一个URL的POST、GET、HEAD等等 —— 都将路由到相同的函数。
1.3.2 捕获的参数永远都是字符串
每个在URLconf中捕获的参数都作为一个普通的Python字符串传递给视图,无论正则表达式使用的是什么匹配方式。例如,下面这行URLconf 中:
url(r‘^re5/(?P<name>[a-zA-Z]{2,4})/(?P<id>[0-9]{2,4})/$‘, views.re_route5),
传递到视图函数views.re_route5()中的name、id参数永远是一个字符串类型。

1.3.3 视图函数中指定默认值
在urls.py中
from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r‘^blog/$‘, views.page), # 不指定page参数时使用默认参数 url(r‘^blog/page(?P<num>[0-9]+)/$‘, views.page), # 指定page参数时使用指定值 ]
在views.py中,为num指定默认值
def page(request, num="1"): # 关键值参数,默认值为1 return HttpResponse("当前第%s页" % num)
在上面的例子中,两个URL模式指向相同的view - views.page - 但是第一个模式并没有从URL中捕获任何东西。
如果第一个模式匹配上了,page()函数将使用其默认参数num=“1”,如果第二个模式匹配,page()将使用正则表达式捕获到的num值。
实现效果就是访问url http://127.0.0.1:8000/blog/时(不指定page参数),页面如下:
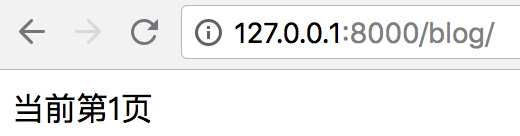
当访问url http://127.0.0.1:8000/blog/page10/(指定page参数),页面如下:
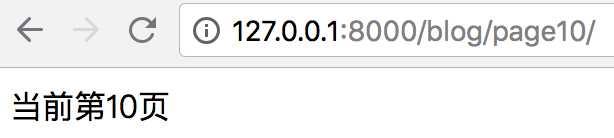
1.3.4 include其它URL
当不同的app下面有相同的页面时,可以用include来解决此问题:
例如,app01下面有home页面,app02下面也有home页面,那么我们可以把两个home.html文件如下布放:
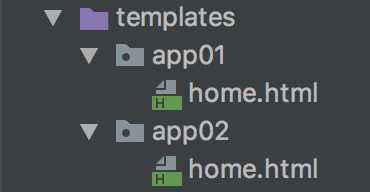
urls.py文件如下配置:
from django.conf.urls import url from django.conf.urls import include from app01 import app01urls from app02 import app02urls urlpatterns = [ url(r‘^app01/‘, include(app01urls)), # 所有以app01开头的url都交给app01/app01urls(app01urls.py)来处理 url(r‘^app02/‘, include(app02urls)), # 所有以app02开头的url都交给app02/app02urls(app02urls.py)来处理 ]
app01下的app01urls.py代码如下:
from django.conf.urls import url from app01 import views urlpatterns = [ url(r‘^home/‘, views.apphome), ]
app02下的app02urls.py代码如下:
from django.conf.urls import url from app02 import views urlpatterns = [ url(r‘^home/‘, views.apphome), ]
这样就可以实现分别访问app01和app02两个不同app下同名的home页
1.4 传递额外的参数给视图函数
URLconfs 具有一个钩子,让你传递一个Python 字典作为额外的参数传递给视图函数。
django.conf.urls.url() 函数可以接收一个可选的第三个参数,它是一个字典,表示想要传递给视图函数的额外关键字参数。
例如:
from django.conf.urls import url from . import views urlpatterns = [ url(r‘^blog/(?P<year>[0-9]{4})/$‘, views.year_archive, {‘foo‘: ‘bar‘}), ]
在这个例子中,对于/blog/2005/请求,Django 将调用views.year_archive(request, year=‘2005‘, foo=‘bar‘)。
这个技术在Syndication 框架中使用,来传递元数据和选项给视图。
1.5 命名URL和URL反向解析
在使用Django 项目时,一个常见的需求是获得URL的最终形式,以用于嵌入到生成的内容中(视图中和显示给用户的URL等)或者用于处理服务器端的导航(重定向等)。
人们强烈希望不要硬编码这些URL(费力、不可扩展且容易产生错误)或者设计一种与URLconf 毫不相关的专门的URL 生成机制,因为这样容易导致一定程度上产生过期的URL。
换句话讲,需要的是一个DRY 机制。除了其它有点,它还允许设计的URL 可以自动更新而不用遍历项目的源代码来搜索并替换过期的URL。
获取一个URL 最开始想到的信息是处理它视图的标识(例如名字),查找正确的URL 的其它必要的信息有视图参数的类型(位置参数、关键字参数)和值。
Django 提供一个办法是让URL 映射是URL 设计唯一的地方。你填充你的URLconf,然后可以双向使用它:
- 根据用户/浏览器发起的URL 请求,它调用正确的Django 视图,并从URL 中提取它的参数需要的值。
- 根据Django 视图的标识和将要传递给它的参数的值,获取与之关联的URL。
第一种方式是我们在前面的章节中一直讨论的用法。第二种方式叫做反向解析URL、反向URL 匹配、反向URL 查询或者简单的URL 反查。
在需要URL 的地方,对于不同层级,Django 提供不同的工具用于URL 反查:
- 在模板中:使用url模板标签。
- 在Python 代码中:使用django.core.urlresolvers.reverse() 函数。
- 在更高层的与处理Django 模型实例相关的代码中:使用get_absolute_url() 方法。
上面说了一大堆,你可能并没有看懂。(那是官方文档的生硬翻译)。
咱们简单来说就是可以给我们的URL匹配规则起个名字,一个URL匹配模式起一个名字。
这样我们以后就不需要写死URL代码了,只需要通过名字来调用当前的URL。
举个简单的例子:
创建一个index.html:
<h3>把URL路径写死的首页链接,如果urls.py文件中的URL路径发生改变(由/home/变为/home8080/)则导致不能正常跳转</h3> <a href="/home/">首页</a> <hr> <h3>通过反射的URL首页链接,即使urls.py文件中的URL路径发生改变(由/home/变为/home8080/)仍能正常跳转</h3> <a href="{% url ‘homepage‘ %}">首页</a>
在views函数中可以这样引用:
def home(request): return render(request, "home.html") def index(request): return render(request, "index.html")
在urls.py中:
url(r‘^index/‘, views.index), url(r‘^home8080/‘, views.home), url(r‘^home8080/‘, views.home, name="homepage"),
访问127.0.0.1:8000/index,页面如下:

点击第一个首页,不能跳转(<a>标签的href为/home/,但urls.py中没有/home/对应的函数);第二个首页,用了反向解析,仍然能跳转(<a>标签的href为URL的别名,通过别名‘homepage‘仍然能在urls.py中解析到真实的URL)
以上是关于63-Django进阶(路由系统)的主要内容,如果未能解决你的问题,请参考以下文章