第 52 讲:论一只爬虫的自我修养
Posted jiangkeji
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第 52 讲:论一只爬虫的自我修养相关的知识,希望对你有一定的参考价值。

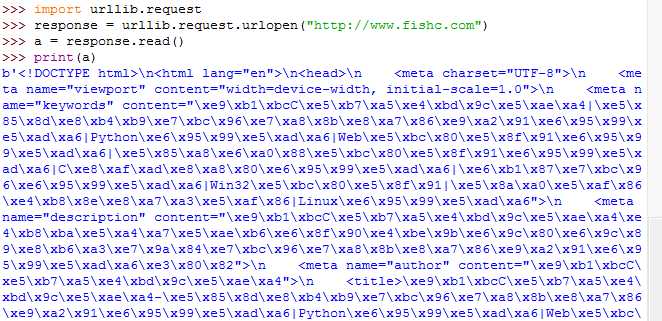
>>> import urllib.request
>>> response = urllib.request.urlopen("http://www.fishc.com")
>>> a = response.read()
>>> a = a.decode("utf-8")
>>> print(a)
课后作业:
0. 请问 URL 是“统一资源标识符”还是“统一资源定位符”?
统一资源标识符
1. 什么是爬虫?
网络爬虫是一种程序,主要用于搜索引擎,它将一个网站的所有内容与链接进行阅读,并建立相关的全文索引到数据库中,然后跳到另一个网站.样子好像一只大蜘蛛.
当人们在网络上(如google)搜索关键字时,其实就是比对数据库中的内容,找出与用户相符合的.网络爬虫程序的质量决定了搜索引擎的能力,如google的搜索引擎明显要比百度好,就是因为它的网络爬虫程序高效,编程结构好.
fAb-Hk5%2h4W`N}@3Gq~&Zipu
2. 设想一下,如果你是负责开发百度蜘蛛的攻城狮,你在设计爬虫时应该特别注意什么问题?
H#dK+1`
3. 设想一下,如果你是网站的开发者,你应该如何禁止百度爬虫访问你网站中的敏感内容?(课堂上没讲,可以自行百度答案)qgI"?Z .A
4. urllib.request.urlopen() 返回的是什么类型的数据?‘JpH6<^
w
对象。
5. 如果访问的网址不存在,会产生哪类异常?(虽然课堂没讲过,但你可以动手试试)3 kta
-
6. 鱼C工作室(http://www.fishc.com)的主页采用什么编码传输的?@a}UL"
=
utf=8
7. 为了解决 ASCII 编码的不足,什么编码应运而生?G7j Y
动动手:
下载鱼C工作室首页(http://www.fishc.com),并打印前三百个字节
以上是关于第 52 讲:论一只爬虫的自我修养的主要内容,如果未能解决你的问题,请参考以下文章