最邻近规则分类(K-Nearest Neighbor)KNN算法
Posted long5683
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最邻近规则分类(K-Nearest Neighbor)KNN算法相关的知识,希望对你有一定的参考价值。
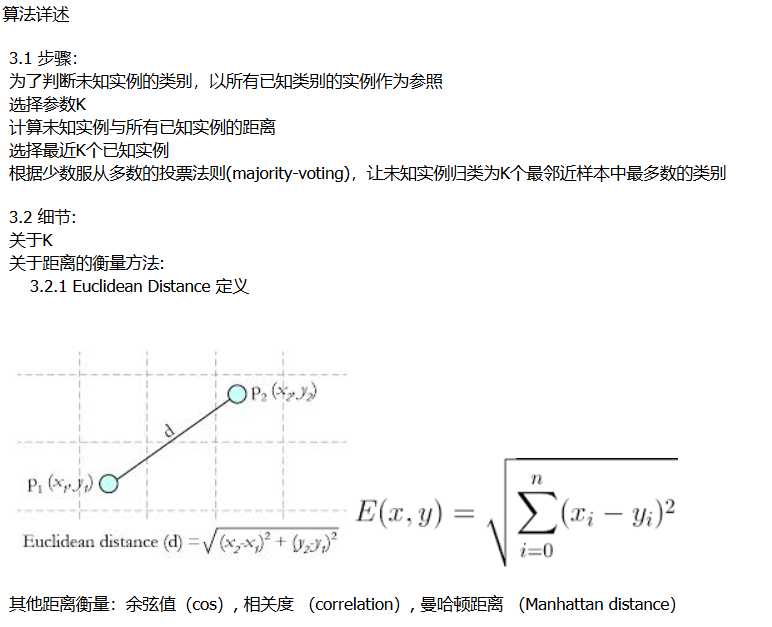
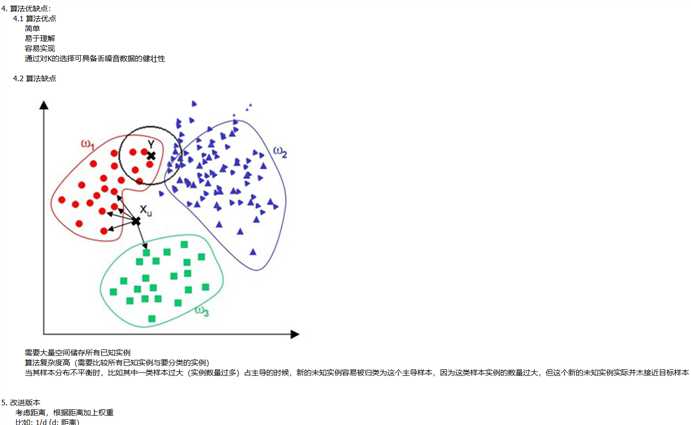
自写代码:
1 # Author Chenglong Qian 2 3 from numpy import * #科学计算模块 4 import operator #运算符模块 5 6 def createDaraSet(): 7 group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])#创建4行2列的数组 8 labels=[‘A‘,"A",‘B‘,‘B‘]#标签列表 9 return group,labels 10 11 group,labels=createDaraSet() 12 13 ‘‘‘k—近邻算法‘‘‘ 14 def classify0(inX,dataSet,labels,k): #inX:需要分类的向量,dataSet:训练样本,labels:标签,k:临近数目 15 ‘‘‘求距离‘‘‘ 16 dataSetSize=dataSet.shape[0] #样本数据行数,即样本的数量 17 diffMat=tile(inX,(dataSetSize,1))-dataSet #(来自numpy)tile:重复数组;将inX重复dataSetSize行,1列次;获得每组数据的差值(Xi-X,Yi-Y) 18 sqDiffMat=diffMat**2 #求平方 19 sqDistances=sqDiffMat.sum(axis=1) #sum(axis=1)矩阵每一行相加,sum(axis=0)每一列相加 20 distances=sqDistances**0.5 #开根号 21 sortedDistIndicies=distances.argsort() #argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y。 22 classCount={} 23 ‘‘‘排序‘‘‘ 24 for i in range(k): 25 voteIlabel=labels[sortedDistIndicies[i]] #sortedDistIndicies[i]第i+1小元素的索引 26 classCount[voteIlabel]=classCount.get(voteIlabel,0)+1 #classCount.get(voteIlabel,0)返回字典classCount中voteIlabel元素对应的值,若无,则将其设为0 27 #这里表示记录某一标签的数量 28 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)#sorted(需要排序的list,key=自定义排序方式,是否反转排序结果) 29 #items 将字典以列表形式返回 (python3.5中无 :iteritems将字典以迭代器形式返回) 30 #itemgetter函数用于获取对象的第几维的数据 operator.itemgetter(1)使用第二个元素进行排序 31 return sortedClassCount[0][0] 32 33 34 ‘‘‘把文本记录转换成矩阵Numpy的解析程序‘‘‘ 35 def file2matrix(filename): 36 fr=open(filename) 37 arrayOLines=fr.readlines() #readlines():返回由文件中剩余的文本(行)组成的列表 38 numberOfLines=len(arrayOLines) #返回对象的长度 39 returnMat=zeros((numberOfLines,3)) 40 classLabelVector=[] 41 index=0 42 for line in arrayOLines: 43 line=line.strip() #strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。 44 listFromLine=line.split(‘ ‘) #split() 通过指定分隔符对字符串进行切片 45 returnMat[index,:]=listFromLine[0:3] 46 classLabelVector.append(int(listFromLine[-1])) 47 index+=1 48 return returnMat,classLabelVector
库代码
1 from sklearn import neighbors 2 from sklearn import datasets 3 4 knn = neighbors.KNeighborsClassifier() 5 6 iris = datasets.load_iris() 7 8 print iris 9 10 knn.fit(iris.data, iris.target) 11 12 predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]]) 13 print "hello" 14 #print ("predictedLabel is :" + predictedLabel) 15 print predictedLabel
以上是关于最邻近规则分类(K-Nearest Neighbor)KNN算法的主要内容,如果未能解决你的问题,请参考以下文章