HashMap,HashSet
Posted yejintianming00
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap,HashSet相关的知识,希望对你有一定的参考价值。
HashMap,HashSet
摘自:https://www.cnblogs.com/skywang12345/p/3310887.html#a1
目录
3. 疑问:如果两个key通过hash%Entry[].length得到的 index相同,会不会有覆盖的危险? 4
3. HashSet源码解析(基于JDK1.6.0_45) 8
2. 深入理解ConcurrentHashMap原理分析即线程安全问题 18
1) ConcurrentHashMap与HashTable的区别 18
七、 HashMap,HashTable和ConcurrentHashMap的区别 21
1. HashMap与ConcurrentHashMap的区别 21
2. ConcurrentHashMap vs Hashtable vs Synchronized Map区别 21
-
HashMap(键值对形式存取,键值不能相同)
-
HashMap的数据结构
数组的特点是:寻址容易,插入和删除困难。
链表的特点是:寻址困难,插入和删除容易。
综合这两者的特性,得到一种寻址容易,插入删除也容易的数据结构:这就是我们要提起的哈希表。
哈希表有多种不同的实现方法,我们接下来解释的是最常用的方法——拉链法,我们可以理解为"链表的数组":如图:
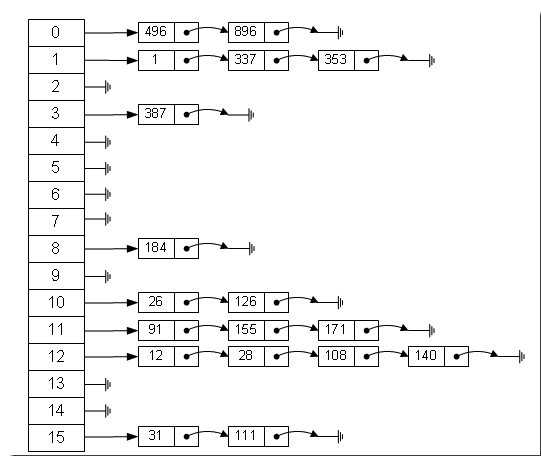
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中的呢?一般情况下是通过hash(key)%len获得,也就是元素的key的哈希值对数组的长度取余得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12,28,108,140都存储在数组下标为12的链表的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组,这可能让我们很不解,一个线性的数据怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HahsMap里面实现了一个静态内部类,其重要的属性有key,value,next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
-
HashMap的存取实现
既然是线性数组,为什么能随机存取呢?这里HashMap用了一个小算法,大致HashMap 采用一种所谓的"Hash 算法"来决定每个元素的存储位置。当程序执行 map.put(String,Obect)方法时,系统将调用String的 hashCode() 方法得到其 hashCode 值——每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置。是这样实现:
|
//存储时: int hash = key.hashCode();// 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值 int index = hash % Entry[].length; Entry[index] = value;
//取值时: int hash = key.hashCode(); int index = hash % Entry[].length; return Entry[index]; |
这里的话我们:
对于存储:
-
通过hashCode()计算key的hash值;
-
通过key的hash值对数组长度取余得到该key的value在数组中的下标;
-
将value赋值给Entry[index]实现键值对的存储
对于取值:
-
首先也是计算key的hash值;
-
计算key的hash值对数组长度取余得到该key的value在数组中的下标;
-
通过返回return Entry[index]得到键key所对应的值。
-
疑问:如果两个key通过hash%Entry[].length得到的 index相同,会不会有覆盖的危险?
这样占用的内存会很大
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方,第一个键值对A进来,通过计算其key的hash得到的index=0,记作:Entry[0]=A。一会又进来一个键值对B,通过计算其index也等于0;现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因素(也称为因子),随着map的size越来越大,Entry[]会以一定的规则加长长度。
-
解决hash冲突的方法
-
开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
-
再哈希法
-
链地址法
-
建立一个公共溢出区
Java中hashMap的解决方法就是采用链地址法。
-
-
Hash冲突是什么?
若两个不相等的 key 产生了相等的哈希值,这时则需要采用哈希冲突。
首先,HashMap是由线性数组组成的,现在我们假设初始数组的长度为5;然后我们存储数据,假设存储的第一个数据的键值的hashcode计算出来的值为6,然后我们通过hashcode计算出来的值与数组长度取余得到存储第一个数据的下标,即6%5=1;当我们存储另外的数据,如果通过键值的hashcode计算出来的值是11,那么此时计算出数据的下标11%5=1也是1。这就是哈希冲突。
-
如何解决哈希冲突?
Java采用拉链法解决哈希冲突。
-
得到一个key;
-
计算key的hashValue;
-
根据 hashValue 值定位到 data[hashValue] 。( data[hashValue] 是一条链表)
-
若 data[hashValue] 为空则直接插入,不然则添加到链表头部。
-
-
HashMap的put()和remove()方法
|
HashMap<String, Integer> map = new HashMap<String, Integer>(); map.put("wang", 01); map.put("wang",02); System.out.println(map.get("wang")); System.out.println("----------------"); map.remove("wang"); System.out.println(map.get("wang")); |
|
*************** 2 ---------------- null |
-
两次插入的键相同时不是哈希冲突
方法:则直接更新该键的值
-
两次插入的键不同时,但是得到相同的hashValue时,是哈希冲突
方法:将值插入到单链表的头结点。
-
删除关键字值为k的记录,应先在该关键字值的哈希地址处的单链表中找到该记录,然后删除之。
-
HashSet(是一个没有重复元素的集合)
-
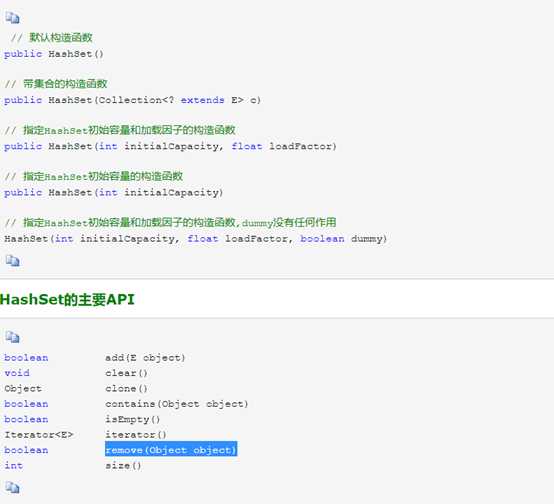
HashSet简介
HashSet是一个没有重复元素的集合,它是由HashMap实现的,不保证元素的顺序,而且HashSet允许使用null元素。
HashSet是非同步的,如果多个线程同时访问一个HashSet,而其中至少一个线程修改了该set,那么它必须保持外部同步。这通常是通过对自然封装该set的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用Collections.synchronizedSet方法来包装set,最好在创建完成时完成这一操作,以防止对该set进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(...));
HashSet通过iterator()迭代器进行访问。
-
HashSet的数据结构
HashSet的继承关系如下:
java.lang.Object
? java.util.AbstractCollection<E>
? java.util.AbstractSet<E>
? java.util.HashSet<E>
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable { }
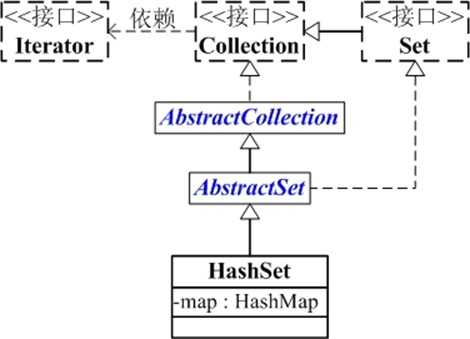
从上图可以看出:
-
HashSet继承与AbstractSet,并且实现了Set接口
-
HashSet的本质是一个"没有重复元素"的集合,它是通过HashMap实现的。HashSet中含有一个"HashMap类型的成员变量"map,HashSet的操作函数,实际上都是通过map实现的。
-
-
HashSet源码解析(基于JDK1.6.0_45)
为了更了解HashSet的原理,下面对HashSet源码代码作出分析。
|
package java.util;
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable { static final long serialVersionUID = -5024744406713321676L;
// HashSet是通过map(HashMap对象)保存内容的 private transient HashMap<E,Object> map;
// PRESENT是向map中插入key-value对应的value // 因为HashSet中只需要用到key,而HashMap是key-value键值对; // 所以,向map中添加键值对时,键值对的值固定是PRESENT private static final Object PRESENT = new Object();
// 默认构造函数 public HashSet() { // 调用HashMap的默认构造函数,创建map map = new HashMap<E,Object>(); }
// 带集合的构造函数 public HashSet(Collection<? extends E> c) { // 创建map。 // 为什么要调用Math.max((int) (c.size()/.75f) + 1, 16),从 (c.size()/.75f) + 1 和 16 中选择一个比较大的树呢? // 首先,说明(c.size()/.75f) + 1 // 因为从HashMap的效率(时间成本和空间成本)考虑,HashMap的加载因子是0.75。 // 当HashMap的"阈值"(阈值=HashMap总的大小*加载因子) < "HashMap实际大小"时, // 就需要将HashMap的容量翻倍。 // 所以,(c.size()/.75f) + 1 计算出来的正好是总的空间大小。 // 接下来,说明为什么是 16 。 // HashMap的总的大小,必须是2的指数倍。若创建HashMap时,指定的大小不是2的指数倍; // HashMap的构造函数中也会重新计算,找出比"指定大小"大的最小的2的指数倍的数。 // 所以,这里指定为16是从性能考虑。避免重复计算。 map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16)); // 将集合(c)中的全部元素添加到HashSet中 addAll(c); }
// 指定HashSet初始容量和加载因子的构造函数 public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<E,Object>(initialCapacity, loadFactor); }
// 指定HashSet初始容量的构造函数 public HashSet(int initialCapacity) { map = new HashMap<E,Object>(initialCapacity); }
HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor); }
// 返回HashSet的迭代器 public Iterator<E> iterator() { // 实际上返回的是HashMap的"key集合的迭代器" return map.keySet().iterator(); }
public int size() { return map.size(); }
public boolean isEmpty() { return map.isEmpty(); }
public boolean contains(Object o) { return map.containsKey(o); }
// 将元素(e)添加到HashSet中 public boolean add(E e) { return map.put(e, PRESENT)==null; }
// 删除HashSet中的元素(o) public boolean remove(Object o) { return map.remove(o)==PRESENT; }
public void clear() { map.clear(); }
// 克隆一个HashSet,并返回Object对象 public Object clone() { try { HashSet<E> newSet = (HashSet<E>) super.clone(); newSet.map = (HashMap<E, Object>) map.clone(); return newSet; } catch (CloneNotSupportedException e) { throw new InternalError(); } }
// java.io.Serializable的写入函数 // 将HashSet的"总的容量,加载因子,实际容量,所有的元素"都写入到输出流中 private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden serialization magic s.defaultWriteObject(); // Write out HashMap capacity and load factor s.writeInt(map.capacity()); s.writeFloat(map.loadFactor()); // Write out size s.writeInt(map.size()); // Write out all elements in the proper order. for (Iterator i=map.keySet().iterator(); i.hasNext(); ) s.writeObject(i.next()); } // java.io.Serializable的读取函数 // 将HashSet的"总的容量,加载因子,实际容量,所有的元素"依次读出 private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden serialization magic s.defaultReadObject();
// Read in HashMap capacity and load factor and create backing HashMap int capacity = s.readInt(); float loadFactor = s.readFloat(); map = (((HashSet)this) instanceof LinkedHashSet ? new LinkedHashMap<E,Object>(capacity, loadFactor) : new HashMap<E,Object>(capacity, loadFactor)); // Read in size int size = s.readInt(); // Read in all elements in the proper order. for (int i=0; i<size; i++) { E e = (E) s.readObject(); map.put(e, PRESENT); } } } |
说明: HashSet的代码实际上非常简单,通过上面的注释应该很能够看懂。它是通过HashMap实现的,若对HashSet的理解有困难,建议先学习以下HashMap;学完HashMap之后,在学习HashSet就非常容易了。
-
HashSet的遍历方式
-
通过Iterator遍历HashSet
-
第一步:根据iterator()获取HashSet的迭代器
遍历迭代器获取各个元素
|
// 假设set是HashSet对象 for(Iterator iterator = set.iterator(); iterator.hasNext(); ) { iterator.next(); } |
-
通过for-each遍历HashSet
-
第一步:根据toArray()获取HashSet的元素集合对应的数组
-
遍历数组,获取各个元素
|
// 假设set是HashSet对象,并且set中元素是String类型 String[] arr = (String[])set.toArray(new String[0]); for (String str:arr) System.out.printf("for each : %s ", str); |
向HashSet中添加元素,如果set中元素已存在,则返回false;如果不存在,则返回true。
-
TreeMap与HashMap的区别和共同点
|
TreeMap |
HashMap |
|
TreeMap实现了SortMap接口,是基于红黑树的 |
HashMap实现了Map接口,是基于哈希散列表的 |
|
TreeMap默认按键的升序排序 |
HashMap随机存储 |
|
TreeMap的遍历是Iterator按顺序遍历的 |
HahsMap的遍历是Iterator随机遍历的 |
|
TreeMap键和值都不能为空 |
HashMap键只能有一个null,值可以有多个null |
|
TreeMap插入删除查找的效率比较低 |
HashMap插入删除查找的效率比较高 |
|
非线程安全的 |
非线程安全的 |
-
HashMap和HashTable的区别
在HashSet中,元素都存到HashMap键值对的Key上面,而Value时有一个统一的值private static final Object PRESENT = new Object();,
当有新值加入时,底层的HashMap会判断Key值是否存在(HashMap细节请移步深入理解HashMap),如果不存在,则插入新值,同时这个插入的细节会依照HashMap插入细节;如果存在就不插入
|
HashMap |
HashSet |
|
HashMap实现了Map接口 |
HashSet实现了Set接口 |
|
HashMap存储键值对 |
HashSet仅仅存储对象,存储的是键,他们的值是相同的。 |
|
使用pub()方法将元素放入map中 |
使用add()方法将元素放入set中 |
|
HashMap中使用键对象来计算hashcode值(不会返回true和false) |
HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false |
|
HashMap查找比较快,因为是使用唯一的键来获取对象 |
HashSet较HashMap来说比较慢 |
-
HashMap和HashTable的区别
|
HashMap |
HashTable |
|
HashMap是基于AbstractMap |
HashTable基于Dictionary类 |
|
HashMap可以允许存在一个为null的key和任意个为null的value |
HashTable中的key和value都不允许为null |
|
HashMap时单线程安全的,多线程是不安全的 |
Hashtable是多线程安全的 |
|
HashMap仅支持Iterator的遍历方式 |
Hashtable支持Iterator和Enumeration两种遍历方式 |
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。Hashtable的方法都用synchronized来修饰,所以它是线程同步的。
-
Hashtable的遍历:-
遍历Hashtable的键值对
-
-
第一步:根据entrySet()获取Hashtable的"键值对"的Set集合。 -
通过Iterator迭代器遍历"第一步"得到的集合。
|
-
通过Iterator遍历Hashtable的键
-
第一步:根据keySet()获取Hashtable的"键"的Set集合。 -
第二步:通过Iterator迭代器遍历"第一步"得到的集合。
|
// 假设table是Hashtable对象 // table中的key是String类型,value是Integer类型 String key = null; Integer integ = null; Iterator iter = table.keySet().iterator(); while (iter.hasNext()) { // 获取key key = (String)iter.next(); // 根据key,获取value integ = (Integer)table.get(key); } |
-
通过Iterator遍历Hashtable的值
-
第一步:根据value()获取Hashtable的"值"的集合。 -
第二步:通过Iterator迭代器遍历"第一步"得到的集合
|
// 假设table是Hashtable对象 // table中的key是String类型,value是Integer类型 Integer value = null; Collection c = table.values(); Iterator iter= c.iterator(); while (iter.hasNext()) { value = (Integer)iter.next(); } |
-
通过Enumeration遍历Hashtable的键
-
第一步:根据keys()获取Hashtable的集合。 -
第二步:通过Enumeration遍历"第一步"得到的集合
|
Enumeration enu = table.elements(); while(enu.hasMoreElements()) { System.out.println(enu.nextElement()); } |
-
通过Enumeration遍历Hashtable的值
-
第一步:根据elements()获取Hashtable的集合。 -
第二步:通过Enumeration遍历"第一步"得到的集合
|
Enumeration enu = table.elements(); while(enu.hasMoreElements()) { System.out.println(enu.nextElement()); } |
-
ConcurrentHashMap的应用
-
concurrentHashMap的优势
首先常用的三种HashMap包括HashMap,HashTable和concurrentHashMap:
-
HashMap在并发编程过程中使用可能导致死循环,因为插入过程不是原子操作,每个HashEntry是一个链表节点,很可能在插入的过程中,已经设置了后节点,实际还未插入,最终反而插入在后节点之后,造成链中出现环,破坏了链表的性质,失去了尾节点,出现死循环。
-
HashTable因为内部是采用synchronized来保证线程安全的,但在线程竞争激烈的情况下HashTable的效率下降得很快因为synchronized关键字会造成代码块或方法成为为临界区(对同一个对象加互斥锁),当一个线程访问临界区的代码时,其他线程也访问同一临界区时,会进入阻塞或轮询状态。究其原因,实际上是有获取锁意向的线程的数目增加,但是锁还是只有单个,导致大量的线程处于轮询或阻塞,导致同一时间段有效执行的线程的增量远不及线程总体增量。
-
在查询时,尤其能够体现出CocurrentHashMap在效率上的优势,HashTable使用Sychronized关键字,会导致同时只能有一个查询在执行,而Cocurrent则不采取加锁的方法,而是采用volatile关键字,虽然也会牺牲效率,但是由于Sychronized,于该文末尾继续讨论。
-
CocurrentHashMap利用锁分段技术增加了锁的数目,从而使争夺同一把锁的线程的数目得到控制。
-
-
锁分段技术就是对数据集进行分段,每段竞争一把锁,不同数据段的数据不存在锁竞争,从而有效提高高并发访问效率。
-
CocurrentHashMap在get方法是无需加锁的,因为用到的共享变量都采用volatile关键字修饰,巴证共享变量在线程之间的可见性(每次读取都先同步缓存和内存,直接从内存中获取值,虽然不是原子操作,但根据JAVA内存模型的happen before原则,对volatile字段的写入操作先于读操作,能够保证不会脏读),volatile为了让变量提供线程之间的内存可见性,会禁止程序执行结果的重排序(导致缓存优化的效果降低)
-
深入理解ConcurrentHashMap原理分析即线程安全问题
-
ConcurrentHashMap与HashTable的区别
HashTable 的put()源代码
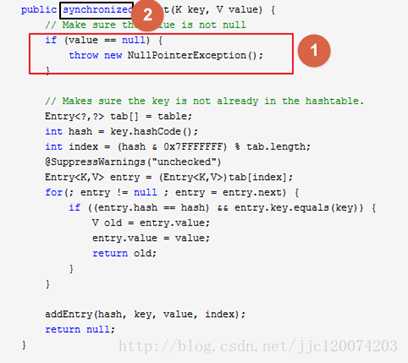
从代码可以看出来在所有put 的操作的时候都需要用 synchronized 关键字进行同步。并且key 不能为空。
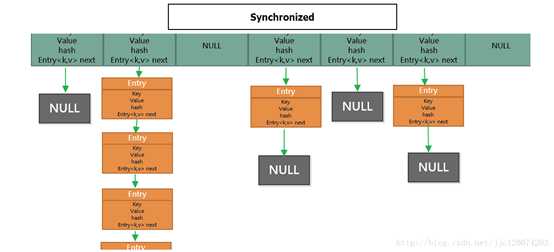
这样相当于每次进行put 的时候都会进行同步当10个线程同步进行操作的时候,就会发现当第一个线程进去其他线程必须等待第一个线程执行完成,才可以进行下去。性能特别差。
-
ConcurrentHashMap详解
分段锁技术:ConcurrentHashMap相比 HashTable而言解决的问题就是的它不是锁全部数据,而是锁一部分数据,这样多个线程访问的时候就不会出现竞争关系。不需要排队等待了。
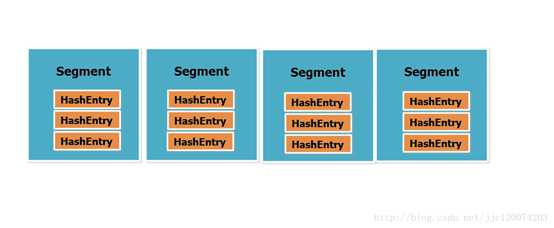
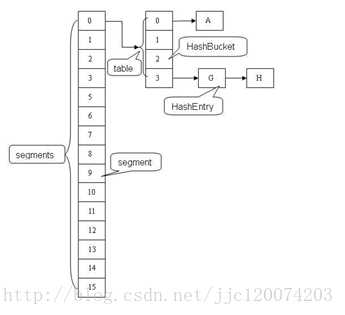
从图中可以看出来ConcurrentHashMap的主干是个Segment数组。、
它把区间按照并发级别(concurrentLevel),分成了若干个segment。默认情况下内部按并发级别为16来创建。对于每个segment的容量,默认情况也是16。
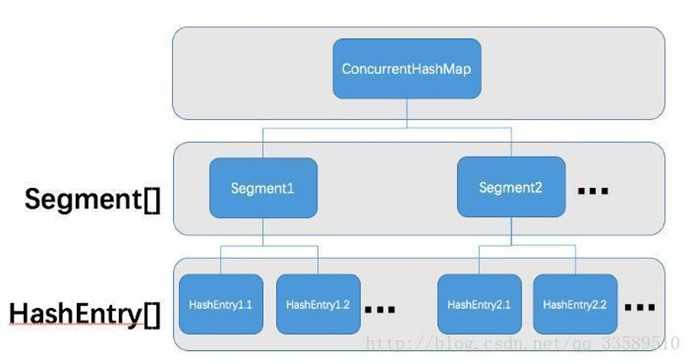
ConcurrentHashMap是由Segment数组和HashEntry数组组成.
Segment是一种可重入锁,在ConcurrentHashMap里扮演锁的角色;
HashEntry则用于存储键值对数据.
一个ConcurrentHashMap里包含一个Segment数组.
Segment的结构和HashMap类似,是一种数组和链表结构.
一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,
必须首先获得与它对应的Segment锁
这就是为什么ConcurrentHashMap支持允许多个修改同时并发进行,原因就是采用的Segment分段锁功能,每一个Segment 都想的于小的hash table并且都有自己锁,只要修改不再同一个段上就不会引起并发问题。
-
HashMap,HashTable和ConcurrentHashMap的区别
-
HashMap与ConcurrentHashMap的区别
-
他们之间的第一个重要的区别就是ConcurrentHashMap是线程安全的和在并发环境下不需要加额外的同步。
-
你可以使用Collections.synchronizedMap(HashMap)来包装HashMap作为同步容器,这时它的作用几乎与Hashtable一样,当每次对Map做修改操作的时候都会锁住这个Map对象,而ConcurrentHashMap会基于并发的等级来划分整个Map来达到线程安全,它只会锁操作的那一段数据而不是整个Map都上锁。
-
ConcurrentHashMap有很好的扩展性,在多线程环境下性能方面比做了同步的HashMap要好,但是在单线程环境下,HashMap会比ConcurrentHashMap好一点。
-
ConcurrentHashMap vs Hashtable vs Synchronized Map区别
虽然三个集合类在多线程并发应用中都是线程安全的,但是他们有一个重大的差别,就是他们各自实现线程安全的方式。
-
Hashtable是jdk1的一个遗弃的类,它把所有方法都加上synchronized关键字来实现线程安全,所有的方法都同步这样造成多个线程访问效率特别低。
-
Synchronized Map与HashTable差别不大,也是在并发中作类似的操作,两者的唯一区别就是Synchronized Map没被遗弃,它可以通过使用Collections.synchronizedMap()来包装Map作为同步容器使用。
-
ConcurrentHashMap的设计有点特别,表现在多个线程操作上。ConcurrentHashMap不需要锁整个Map,相反它划分了多个段(segments),要操作哪一段才上锁那段数据。
以上是关于HashMap,HashSet的主要内容,如果未能解决你的问题,请参考以下文章