『TensotFlow』LSTM古诗生成任务总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了『TensotFlow』LSTM古诗生成任务总结相关的知识,希望对你有一定的参考价值。
往期RNN相关工程实践文章
『TensotFlow』RNN中文文本_下_暨研究生开学感想
背景
赶着这个周末把之前一直感兴趣的RNN文本生成实现了一下,实际效果极差,我很怀疑网上那些教程作者有没有实际的跑一边自己的模型。不过也是有收获的,对于tensorflow处理RNN那一套我还是挺熟悉的了现在。也正鉴于此,这里只是给出一个个人的总结,主要是有关RNN数据(预)处理流程以及tensorflow相关函数应用的总结,也会给出我对于demo网上模型时的一些困惑,我很怀疑他们使用的一些函数逻辑的正确性。
有关这个流程我还是有一点自己的看法的,不过由于实际上课程和实验室压力比较大,所以不打算深入研究这个任务了,如果放假的时候如果还有兴趣再说。
代码
中规中矩的头,
-注意一下,batch_size在训练时订的大一点(比如100),生成古诗时要修改为1
import os import copy import pprint import numpy as np import tensorflow as tf from collections import Counter os.environ[‘TF_CPP_MIN_LOG_LEVEL‘] = ‘2‘ batch_size = 1 pp = pprint.PrettyPrinter() poetry_file = ‘poetry.txt‘
数据读入以及筛选,
-没啥改进
‘‘‘诗词字符数据读入‘‘‘
poetry_body_str = []
with open(poetry_file, ‘r‘, encoding=‘utf-8‘) as f:
for line in f:
try:
title, body = line.strip(‘\\n‘).split(‘:‘)
if ‘_‘ in body or ‘(‘ in body or ‘(‘ in body or ‘《‘ in body or ‘[‘ in body: continue
if len(body) < 5 or len(body) > 79: continue
poetry_body_str.append(‘<‘ + body + ‘>‘)
except Exception as e:
pass
# pp.pprint(poetry_body)
诗词向量化,
-简化了网络上通用版本的代码
‘‘‘诗词向量数据生成‘‘‘
words = ‘_‘
for poetry in poetry_body_str:
words += poetry
words_list = sorted(Counter(words).items(), key=lambda x:-x[1])
word_dict = dict([(word,num)for word, num in zip(np.array(words_list)[:,0], range(len(words_list)))])
str2vec = lambda str:[word_dict.get(word) for word in str]
poetry_vector = [str2vec(poetry) for poetry in poetry_body_str]
因为涉及不少基础包的用法,所以做个小介绍,
高阶排序函数
sorted(序列,key=lambda)
list字典化
dict([(1,2),(3,4)...])
广播函数
map(fun, 序列)
numpy数组初始化函数
np.full((shape), value, type)
batch数据抽取函数,
-现在会动态生成每个batch,不是以前的一次切割永久使用
def batch_data():
data_raw = [poetry_vector[num] for num in np.random.choice(len(poetry_vector),batch_size)]
time_step = np.max([length for length in map(len,data_raw)])
data_res = np.full((batch_size, time_step), str2vec(‘_‘)[0], np.int32)
row = 0
for data in data_raw:
data_res[row][:len(data)] = data
row += 1
label = copy.deepcopy(data_res)
label[:,:-1] = data_res[:,1:]
return data_res,label
实际上我用sklearn进行了尝试,不过sklearn会基于英文的空格进行分词,无法对中文使用,不能正确区分中文字符,
# from sklearn.feature_extraction.text import CountVectorizer
# cv = CountVectorizer()
LSTM网络结构构建,
-优化了代码结构,使得逻辑更加清晰
-语法采用了2017年tf最新版本,实际上流传网络的各个版本古诗代码都已经不能在新版tf上运行了(呼叫『TensotFlow』深层循环神经网络)
with tf.variable_scope(‘placeholder‘):
input_vec = tf.placeholder(tf.int32,[None,None])
output_targets = tf.placeholder(tf.int32,[None,None])
def rnn_network(rnn_size=128,num_layers=2):
def lstm_cell():
l_cell = tf.contrib.rnn.BasicLSTMCell(rnn_size,state_is_tuple=True,reuse=tf.get_variable_scope().reuse)
return l_cell
cell = tf.contrib.rnn.MultiRNNCell([lstm_cell() for _ in range(num_layers)])
initial_state = cell.zero_state(batch_size, tf.float32) # 初始化LSTM网络节点,参数为尺寸
with tf.variable_scope(‘LSTM‘):
with tf.variable_scope(‘embedding‘):
E = tf.get_variable(‘embedding‘,[len(words_list) + 1,rnn_size])
input_embedding = tf.nn.embedding_lookup(E,input_vec)
output_embedding, last_state = tf.nn.dynamic_rnn(cell, input_embedding, initial_state=initial_state,scope=‘lstm‘)
output = tf.reshape(output_embedding,[-1,rnn_size])
with tf.variable_scope(‘output‘):
W = tf.get_variable(‘W‘, [rnn_size,len(words_list)+1])
b = tf.get_variable(‘b‘, [len(words_list)+1])
logits = tf.matmul(output,W) + b
probs = tf.nn.softmax(logits)
return logits, last_state, probs, cell, initial_state
下图给出了预处理之后在整个网络中数据维度的变化情况(灵魂绘图师),可以比较直观的观测出数据流动情况,
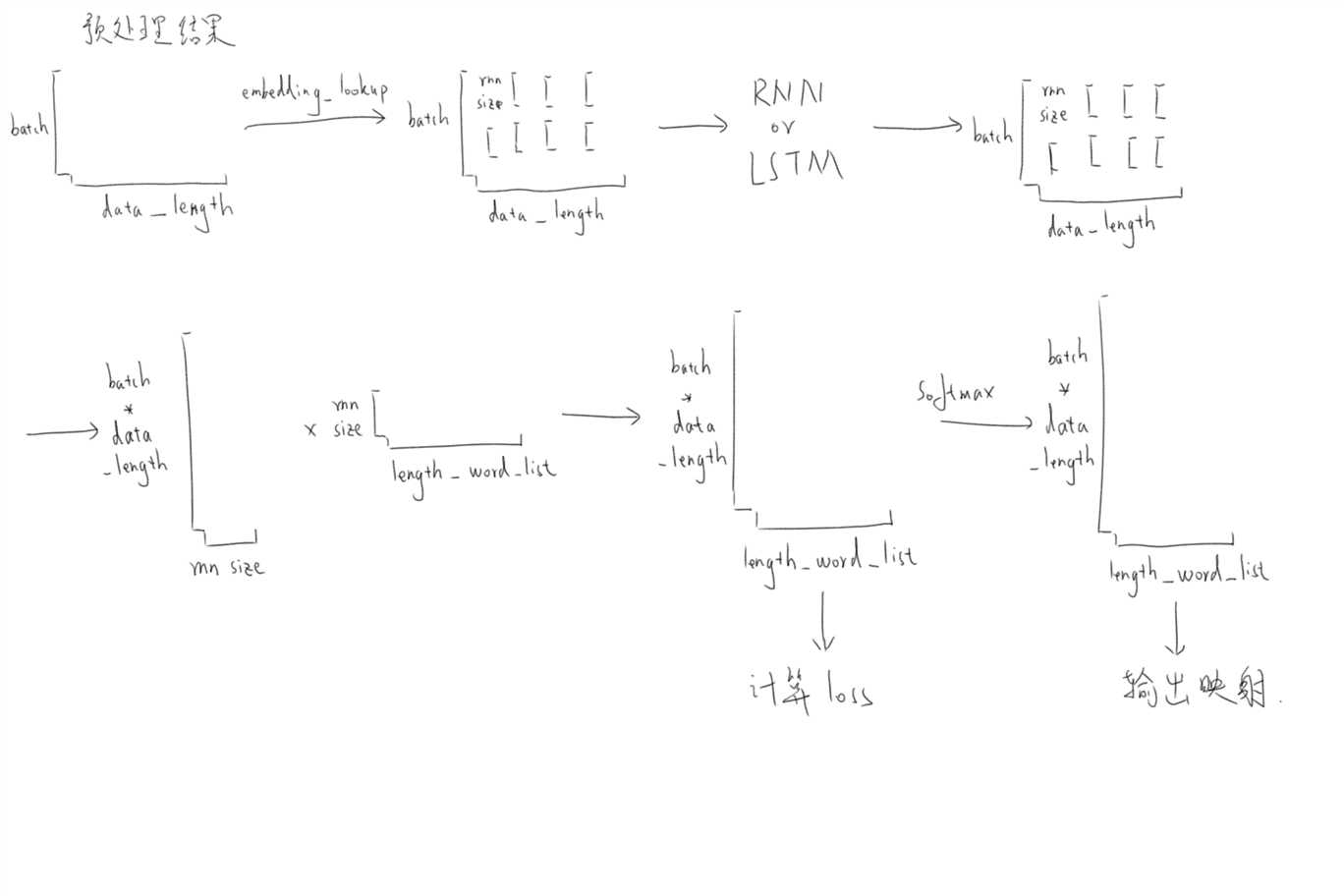
训练模型,
-没啥改进
-值得注意的是现在网上流传的大部分版本古诗生成的模型读取写法都有问题,我这个没有
def train_LSTM_network():
logits, last_state, _, _, _ = rnn_network()
targets = tf.reshape(output_targets, [-1])
cost = tf.reduce_mean(tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits],
[targets],
[tf.ones_like(targets,dtype=tf.float32)]))
learning_rate = tf.Variable(0.0,trainable=False)
tvars = tf.trainable_variables()
grabs, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars), 5)
optimzer = tf.train.AdamOptimizer(learning_rate)
train = optimzer.apply_gradients(zip(grabs,tvars))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
batch_num = len(poetry_vector)//batch_size
for epoch in range(50):
sess.run(tf.assign(learning_rate, 0.002*(0.97**epoch)))
for batches in range(batch_num):
X_batch, y_batch = batch_data()
train_loss,_,_ = sess.run([cost, last_state,train],
feed_dict={input_vec:X_batch, output_targets:y_batch})
print(epoch, batches, train_loss)
if batches % 500 == 0:
if not os.path.exists(‘./logs‘):
os.makedirs(‘./logs‘)
saver.save(sess,‘./logs/model.ckpt‘,global_step=epoch)
古诗生成,
-基本照抄网上的版本
-研究一下代码就可以发现这个vec2str函数有问题,根本不是标准的向量向字符的反向映射过程,而且s值恒为1还要煞有介事的拉出来乘一下也...
-这个vec2str
def gen_poetry():
def vec2str(probs):
t = np.cumsum(probs) # 求累积和
s = np.sum(probs) # 求和,由于处理的是softmax输出,所以实际恒为1
sample = (np.searchsorted(t,(np.random.rand(1) * s)[0])) # 生成随机数,并插入累积和数组,返回序号
print(probs.shape,‘\\n‘,t[-1],‘\\n‘,s,‘\\n‘,sample)
return np.array(words_list)[:,0][sample]
def vec2str_(probs):
return np.array(words_list)[:,0][np.argmax(probs)] # 实际上这才应该是正常的映射函数,在概率分布中取出最大的,取其对应的字符
_,last_state,probs,cell,initial_state = rnn_network()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
ckpt = tf.train.get_checkpoint_state(‘./logs/‘)
saver = tf.train.import_meta_graph(ckpt.model_checkpoint_path + ‘.meta‘)
saver.restore(sess,ckpt.model_checkpoint_path)
state_ = sess.run(cell.zero_state(1,tf.float32)) # 初始化LSTM网络节点,参数为尺寸
start_step = np.array([str2vec(‘<‘)])
[probs_,state_] = sess.run([probs,last_state],
feed_dict={input_vec: start_step,initial_state: state_})
word = vec2str(probs_)
poetry_res = ‘‘
while word != ‘>‘:
poetry_res += word
step = np.array([str2vec(word)])
[probs_,state_] = sess.run([probs,last_state],
feed_dict={input_vec: step,initial_state: state_})
word = vec2str(probs_)
print(poetry_res)
return poetry_res
主函数,
if __name__==‘__main__‘:
train_LSTM_network()
gen_poetry()
总结
实际上生成不了古诗,epoch为50的时候loss的确会下降到2.6左右(浮动还是挺大的),作为参考刚刚开始时是8.5左右,但是即使这样生成函数运行时也是生成不出来有意义的东西。
网上流传的说能学出来格式(5字一个‘,‘)也基本是胡扯,这里给出一篇勉强靠谱的参考博客,是在网上流传最广的版本的一个加强 Tensorflow:基于LSTM生成藏头诗,虽然我下载了他的model和生成程序,但是跑出来的东西和我自己的生成没什么差别。当然,我是指普通的古诗生成,我看他的代码中,对于藏头诗的字数什么的做出了硬性的(使用代码截断字数,不靠模型自己学习)规范,所以感觉可能比较靠谱,但是考虑到明天又是周一了,不玩啦,大家感兴趣的自己去看看他的博客吧,还是做了一些不错的改进的,笑。
以上是关于『TensotFlow』LSTM古诗生成任务总结的主要内容,如果未能解决你的问题,请参考以下文章
杨森翔:春节文化大观上编 第三章 春节古诗词 目录 第一节:春节诗词概述 除夕诗词概述 元日诗词概述 (示例代
手把手写深度学习(17):用LSTM为图片生成文字描述(Image-to-text任务)