从 Java 角度深入理解 Kotlin
Posted Chiclaim
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从 Java 角度深入理解 Kotlin相关的知识,希望对你有一定的参考价值。
前言
前几个月,在组内分享了关于 Kotlin 相关的内容。但由于PPT篇幅的原因,有些内容讲的也不是很详细。
所以通过一篇文字来详解介绍 Kotlin 的特性,为了方便大家对本文有一个大概的了解,文本主要讲如下内容:(下面的目录和我在组内分享时PPT目录是类似的):
- Kotlin数据类型、访问修饰符
- Kotlin和Java数据类型对比
- Kotlin和Java访问修饰符对比
- Kotlin中的Class和Interface
- Kotlin中声明类的几种方式
- Kotlin中interface原理分析
- lambda 表达式
- lambda 初体验
- 定义 lambda 表达式
- Member Reference
- 常用函数 let、with、run、apply 分析
- lambda 原理分析
- 高阶函数
- 高阶函数的定义
- 高阶函数的原理分析
- 高阶函数的优化
- Kotlin泛型
- Java 泛型:不变、协变、逆变
- Kotlin 中的协变、逆变
- Kotlin 泛型擦除和具体化
- Kotlin集合
- kotlin 集合创建方式有哪些
- kotlin 集合的常用的函数
- Kotlin 集合 Sequence 原理
- Koltin 和 Java 交互的一些问题
- 总结
除了这篇文章,我还写过 Kotlin 相关的其他文章:
Kotlin 数据类型、访问修饰符
为什么要讲下 Kotlin 数据类型和访问修饰符修饰符呢?因为 Kotlin 的数据类型和访问修饰符和 Java 的还是有些区别的,所以单独拎出来说一下。
Kotlin 数据类型
我们知道,在 Java 中的数据类型分基本数据类型和基本数据类型对应的包装类型。如 Java 中的整型 int 和它对应的 Integer包装类型。
在 Kotlin 中是没有这样的区分的,例如对于整型来说只有 Int 这一个类型,Int 是一个类(姑且把它当装包装类型),我们可以说在 Kotlin 中在编译前只有包装类型,为什么说是编译前呢?因为编译时会根据情况把这个整型( Int )是编译成 Java 中的 int 还是 Integer。 那么是根据哪些情况来编译成基本类型还是包装类型呢,后面会讲到。我们先来看下 Kotlin和 Java 数据类型对比:
| Java基本类型 | Java包装类型 | Kotlin对应 |
|---|---|---|
| char | java.lang.Character | kotlin.Char |
| byte | java.lang.Byte | kotlin.Byte |
| short | java.lang.Short | kotlin.Short |
| int | java.lang.Integer | kotlin.Int |
| float | java.lang.Float | kotlin.Float |
| double | java.lang.Double | Kotlin.Double |
| long | java.lang.Long | kotlin.Long |
| boolean | java.lang.Boolean | kotlin.Boolean |
下面来分析下哪些情况编译成Java中的基本类型还是包装类型。下面以整型为例,其他的数据类型同理。
1. 如果变量可以为null(使用操作符?),则编译后是包装类型
//因为可以为 null,所以编译后为 Integer
var width: Int? = 10
var width: Int? = null
//编译后的代码
@Nullable
private static Integer width = 10;
@Nullable
private static Integer width;
再来看看方法返回值为整型:
//返回值 Int 编译后变成基本类型 int
fun getAge(): Int
return 0
//返回值 Int 编译后变成 Integer
fun getAge(): Int?
return 0
所以声明变量后者方法返回值的时候,如果声明可以为 null,那么编译后时是包装类型,反之就是基本类型。
2. 如果使用了泛型则编译后是包装类型,如集合泛型、数组泛型等
//集合泛型
//集合里的元素都是 Integer 类型
fun getAge3(): List<Int>
return listOf(22, 90, 50)
//数组泛型
//会编译成一个 Integer[]
fun getAge4(): Array<Int>
return arrayOf(170, 180, 190)
//看下编译后的代码:
@NotNull
public static final List getAge3()
return CollectionsKt.listOf(new Integer[]22, 90, 50);
@NotNull
public static final Integer[] getAge4()
return new Integer[]170, 180, 190;
3. 如果想要声明的数组编译后是基本类型的数组,需要使用 xxxArrayOf(…),如 intArrayOf
从上面的例子中,关于集合泛型编译后是包装类型在 Java 中也是一样的。如果想要声明的数组编译后是基本类型的数组,需要使用 Kotlin 为我们提供的方法:
//会编译成一个int[]
fun getAge5(): IntArray
return intArrayOf(170, 180, 190)
当然,除了intArrayOf,还有charArrayOf、floatArrayOf等等,就不一一列举了。
4. 为什么 Kotlin 要单独设计一套这样的数据类型,不共用 Java 的那一套呢?
我们都知道,Kotlin 是基于 JVM 的一款语言,编译后还是和 Java 一样。那么为什么不像集合那样直接使用 Java 那一套,要单独设计一套这样的数据类型呢?
Kotlin 中没有基本数据类型,都是用它自己的包装类型,包装类型是一个类,那么我们就可以使用这个类里面很多有用的方法。下面看下 Kotlin in Action 的一段代码:
fun showProgress(progress: Int)
val percent = progress.coerceIn(0, 100)
println("We're $percent% done!")
编译后的代码为:
public static final void showProgress(int progress)
int percent = RangesKt.coerceIn(progress, 0, 100);
String var2 = "We're " + percent + "% done!";
System.out.println(var2);
从中可以看出,在开发阶段我们可很方便地使用 Int 类扩展函数。编译后,依然编译成基本类型 int,使用到的扩展函数的逻辑也会包含在内。
关于 Kotlin 中的数据类型就讲到这里,下面来看下访问修饰符
Kotlin 访问修饰符
我们知道访问修饰符可以修饰类,也可以修饰类的成员。下面通过两个表格来对比下 Kotlin 和 Java 在修饰类和修饰类成员的异同点:
表格一:类访问修饰符:
| 类访问修饰符 | Java可访问级别 | Kotlin可访问级别 |
|---|---|---|
| public | 均可访问 | 均可访问 |
| protected | 同包名 | 同包名也不可访问 |
| internal | 不支持该修饰符 | 同模块内可见 |
| default | 同包名下可访问 | 相当于public |
| private | 当前文件可访问 | 当前文件可访问 |
表格二:类成员访问修饰符:
| 成员修饰符 | Java可访问级别 | Kotlin可访问级别 |
|---|---|---|
| public | 均可访问 | 均可访问 |
| protected | 同包名或子类可访问 | 只有子类可访问 |
| internal | 不支持该修饰符 | 同模块内可见 |
| default | 同包名下可访问 | 相当于public |
| private | 当前文件可访问 | 当前文件可访问 |
通过以上两个表格,有几点需要讲一下。
1. internal 修饰符是 Kotlin 独有而 Java 中没有的
internal 修饰符意思是只能在当前模块访问,出了当前模块不能被访问。
需要注意的是,如果 A 类是 internal 修饰,B 类继承 A 类,那么 B 类也必须是 internal 的,因为如果 kotlin 允许 B 类声明成public 的,那么 A 就间接的可以被其他模块的类访问。
也就是说在 Kotlin 中,子类不能放大父类的访问权限。类似的思想在 protected 修饰符中也有体现,下面会讲到。
2. protected 修饰符在Kotlin和Java中的异同点
1) protected 修饰类
我们知道,如果 protected 修饰类,在 Java 中该类只能被同包名下的类访问。
这样也可能产生一些问题,比如某个库中的类 A 是 protected 的,开发者想访问它,只需要声明一个类和类A相同包名即可。
而在 Kotlin 中就算是同包名的类也不能访问 protected 修饰的类。
为了测试 protected 修饰符修饰类,我在写demo的时候,发现 protected 修饰符不能修饰顶级类,只能放在内部类上。
为什么不能修饰顶级类?
一方面,在 Java 中 protected 修饰的类,同包名可以访问,default 修饰符已经有这个意思了,把顶级类再声明成 protected 没有什么意义。
另一方面,在 Java 中 protected 如果修饰类成员,除了同包名可以访问,不同包名的子类也可以访问,如果把顶级类声明成protected,也不会存在不同包名的子类了,因为不同包名无法继承 protected 类
在 Kotlin 中也是一样的,protected 修饰符也不能修饰顶级类,只能修饰内部类。
在 Kotlin 中,同包名不能访问 protected 类,如果想要继承 protected 类,需要他们在同一个内部类下,如下所示:
open class ProtectedClassTest
protected open class ProtectedClass
open fun getName(): String
return "chiclaim"
protected class ProtectedClassExtend : ProtectedClass()
override fun getName(): String
return "yuzhiqiang"
除了在同一内部类下,可以继承 protected 类外,如果某个类的外部类和 protected 类的外部类有继承关系,这样也可以继承protected 类
class ExtendKotlinProtectedClass2 : ProtectedClassTest()
private var protectedClass: ProtectedClass? = null
//继承protected class
protected class A : ProtectedClass()
需要注意的是,继承 protected 类,那么子类也必须是 protected,这一点和 internal 是类似的。Kotlin 中不能放大访问权限,能缩小访问权限吗?答案是可以的。
可能有人会问,既然同包名都不能访问 protected 类,那么这个类跟私有的有什么区别?确实,如果外部类没有声明成 open,编译器也会提醒我们此时的 protected 就是 private
所以在 Kotlin 中,如果要使用 protected 类,需要把外部声明成可继承的 (open),如:
//继承 ProtectedClassTest
class ExtendKotlinProtectedClass2 : ProtectedClassTest()
//可以使用 ProtectedClassTest 中的 protected 类了
private var protectedClass: ProtectedClass? = null
2) protected修饰类成员
如果 protected 修饰类成员,在 Java 中可以被同包名或子类可访问;在 Kotlin 中只能被子类访问。
这个比较简单就不赘述了
3) 访问修饰符小结
- 如果不写访问修饰符,在 Java 中是 default 修饰符 (package-private);在 Kotlin 中是 public 的
- internal 访问修饰符是 Kotlin 独有,只能在模块内能访问的到
- protected 修饰类的时候,不管是 Java 和 Kotlin 都只能放到内部类上
- 在 Kotlin 中,要继承 protected 类,要么子类在同一内部类名下;要么该类的的外部类和 protected 类的外部类有继承关系
- 在 Kotlin 中,继承 protected 类,子类也必须是 protected 的
- 在 Kotlin 中,对于 protected 修饰符,去掉了同包名能访问的特性
- 如果某个 Kotlin 类能够被继承,需要 open 关键字,默认是 final 的
虽然Kotlin的数据类型和访问修饰符比较简单,还是希望大家能够动手写些demo验证下,这样可能会有意想不到的收获。你也可以访问我的 github 上面有比较详细的测试 demo,有需要的可以看下。
Kotlin 中的 Class 和 Interface
Kotlin 中声明类的几种方式
在实际的开发当中,经常需要去新建类。在 Kotlin 中有如下几种声明类的方式:
1) class className
这种方式和 Java 类似,通过 class 关键字来声明一个类。不同的是,这个类是 public final 的,不能被继承。
class Person
编译后:
public final class Person
2) class className([var/val] property: Type…)
这种方式和上面一种方式多加了一组括号,代表构造函数,我们把这样的构造函数称之为 primary constructor。这种方式声明一个类的主要做了一下几件事:
- 会生成一个构造方法,参数就是括号里的那些参数
- 会根据括号的参数生成对应的属性
- 会根据 val 和 var 关键字来生成 setter、getter 方法
var 和 val 关键字:var 表示该属性可以被修改;val 表示该属性不能被修改
class Person(val name: String) //name属性不可修改
---编译后---
public final class Person
//1. 生成 name 属性
@NotNull
private final String name;
//2. 生成 getter 方法
//由于 name 属性不可修改,所以不提供 name 的 setter 方法
@NotNull
public final String getName()
return this.name;
//3. 生成构造函数
public Person(@NotNull String name)
Intrinsics.checkParameterIsNotNull(name, "name");
super();
this.name = name;
如果我们把 name 修饰符改成 var,编译后会生成 getter 和 setter 方法,同时也不会有 final 关键字来修饰 name 属性
如果这个 name 不用 var 也不用 val 修饰, 那么不会生成属性,自然也不会生成 getter 和 setter 方法。不过可以在 init代码块 里进行初始化, 否则没有什么意义。
class Person(name: String)
//会生成 getter 和 setter 方法
var name :String? =null
//init 代码块会在构造方法里执行
init
this.name = name
----编译后
public final class Person
@Nullable
private String name;
@Nullable
public final String getName()
return this.name;
public final void setName(@Nullable String var1)
this.name = var1;
public Person(@NotNull String name)
Intrinsics.checkParameterIsNotNull(name, "name");
super();
this.name = name;
从上面的代码可知,init 代码块 的执行时机是构造函数被调用的时候,编译器会把 init 代码块里的代码 copy 到构造函数里。
如果有多个构造函数,那么每个构造函数里都会有 init 代码块的代码,但是如果构造函数里调用了另一个重载的构造函数,init 代码块只会被包含在被调用的那个构造函数里。
说白了,构造对象的时候,init 代码块里的逻辑只有可能被执行一次。
3) class className constructor([var/val] property: Type…)
该种方式和上面是等价的,只是多加了 constructor 关键字而已
4) 类似 Java 的方式声明构造函数
不在类名后直接声明构造函数 ,在类的里面再声明构造函数。我们把这样的构造函数称之为 secondary constructor
class Person
var name: String? = null
var id: Int = 0
constructor(name: String)
this.name = name
constructor(id: Int)
this.id = id
primary constructor 里的参数是可以被 var/val 修饰,而 secondary constructor 里的参数是不能被 var/val 修饰的
secondary constructor 用的比较少,用得最多的还是 primary constructor
5) data class className([var/val] property: Type)
新建 bean 类的时候,常常需要声明 equals、hashCode、toString 等方法,我们需要写很多代码。在 Kotlin 中,只需要在声明类的时候前面加 data 关键字就可以完成这些功能。
节省了很多代码篇幅。需要注意的是,那么哪些属性参与 equals、hashCode、toString 方法呢?
primary constructor 构造函数里的参数,都会参与 equals、hashCode、toString 方法里。
这个也比较简单,大家可以利用 Kotlin 插件,查看下反编译后的代码即可。由于篇幅原因,在这里就不贴出来了。
6) object className
这种方法声明的类是一个单例类,以前在Java中新建一个单例类,需要写一些模板代码,在Kotlin中一行代码就可以了(类名前加上object关键字)
在 Kotlin 中 object 关键字有很多用法,等介绍完了 Kotlin 新建类方式后,单独汇总下 object 关键字的用法。
7) Kotlin 新建内部类
在 Kotlin 中内部类默认是静态的( Java 与此相反),不持有外部类的引用,如:
class OuterClass
//在 Kotlin 中内部类默认是静态的,不持有外部类的引用
class InnerStaticClass
//如果要声明非静态的内部类,需要加上 inner 关键字
inner class InnerClass
编译后代码如下:
class OuterClass
public static final class InnerStaticClass
public final class InnerClass
8) sealed class className
当我们使用 when 语句通常需要加 else 分支,如果添加了新的类型分支,忘记了在 when 语句里进行处理,遇到新分支,when 语句就会走 else 逻辑
sealed class 就是用来解决这个问题的。如果有新的类型分支且没有处理编译器就会报错。
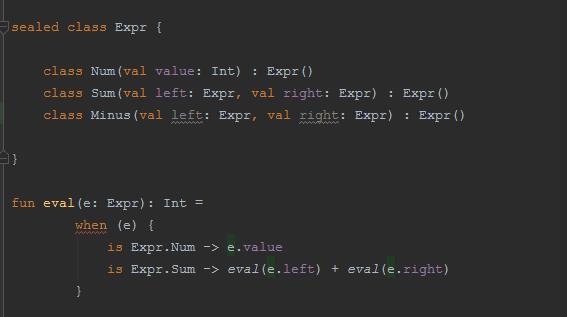
当 when 判断的是 sealed class,那么不需要加 else 默认分支,如果有新的子类,编译器会通过编译报错的方式提醒开发者添加新分支,从而保证逻辑的完整性和正确性
需要注意的是,当 when 判断的是 sealed class,千万不要添加 else 分支,否则有新类编译器也不会提醒
sealed class 实际上是一个抽象类且不能被继承,构造方法是私有的。
object 关键字用法汇总
除了上面我们介绍的,object 关键字定义单例类外,object 关键字还有以下几种用法:
1) companion object
我们把 companion object 称之为伴生对象,伴生体里面放的是一些静态成员:如静态常量、静态变量、静态方法
companion object 需要定义在一个类的内部,里面的成员都是静态的。如下所示:
class ObjectKeywordTest
//伴生对象
companion object
需要注意的是,在伴生体里面不同定义的方式有不同的效果,虽然他们都是静态的:
companion object
//公有常量
const val FEMALE: Int = 0
const val MALE: Int = 1
//私有常量
val GENDER: Int = FEMALE
//私有静态变量
var username: String = "chiclaim"
//静态方法
fun run()
println("run...")
- 如果使用 val 来定义,而没有使用 const 那么该属性是一个私有常量
- 如果使用 const 和 val 来定义则是一个公共常量
- 如果使用 var 来定义,则是一个静态变量
虽然只是一个关键字的差别,但是最终编译出的结果还是有细微的差别的,在开发中注意下就可以了。
我们来看下上面代码编译之后对应的 Java 代码:
class ObjectKeywordTest
//公有常量
public static final int FEMALE = 0;
public static final int MALE = 1;
//私有常量
private static final int gender = 1;
//静态变量
@NotNull
private static String username = "chiclaim";
public static final ObjectKeywordTest.Companion Companion = new ObjectKeywordTest.Companion((DefaultConstructorMarker)null);
public static final class Companion
public final void run()
String var1 = "run...";
System.out.println(var1);
public final int getGENDER()
return ObjectKeywordTest.GENDER;
@NotNull
public final String getUsername()
return ObjectKeywordTest.username;
public final void setUsername(@NotNull String var1)
Intrinsics.checkParameterIsNotNull(var1, "<set-?>");
ObjectKeywordTest.username = var1;
private Companion()
我们发现会生成一个名为 Companion 的内部类,如果伴生体里是方法,则该方法定义在该内部类中,如果是属性则定义在外部类里。如果是私有变量在内部类中生成 getter 方法。
同时还会在外部声明一个名为 Companion 的内部类对象,用来访问这些静态成员。伴生对象的默认名字叫做 Companion,你也可以给它起一个名字,格式为:
companion object YourName
除了给这个伴生对象起一个名字,还可以让其实现接口,如:
class ObjectKeywordTest4
//实现一个接口
companion object : IAnimal
override fun eat()
println("eating apple")
fun feed(animal: IAnimal)
animal.eat()
fun main(args: Array<String>)
//把类名当作参数直接传递
//实际传递的是静态对象 ObjectKeywordTest4.Companion
//每个类只会有一个伴生对象
feed(ObjectKeywordTest4)
2) object : className 创建匿名内部类对象
如下面的例子,创建一个 MouseAdapter 内部类对象:
jLabel.addMouseListener(object : MouseAdapter()
override fun mouseClicked(e: MouseEvent?)
super.mouseClicked(e)
println("mouseClicked")
override fun mouseMoved(e: MouseEvent?)
super.mouseMoved(e)
println("mouseMoved")
)
至此,object 关键字有 3 种用法:
- 定义单例类,格式为:object className
- 定义伴生对象,格式为:companion object
- 创建匿名内部类对象,格式为:object : className
Kotlin 中的 Interface
我们都知道,在 Java8 之前,Interface 中是不能包含有方法体的方法和属性,只能包含抽象方法和常量。
在 Kotlin 中的接口在定义的时候可以包含有方法体的方法,也可以包含属性。
//声明一个接口,包含方法体的方法 plus 和一个属性 count
interface InterfaceTest
var count: Int
fun plus(num: Int)
count += num
//实现该接口
class Impl : InterfaceTest
//必须要覆盖 count 属性
override var count: Int = 0
我们来看下底层 Kotlin 接口是如何做到在接口中包含有方法体的方法、属性的。
public interface InterfaceTest
//会为我们生成三个抽象方法:属性的 getter 和 setter 方法、plus 方法
int getCount();
void setCount(int var1);
void plus(int var1);
//定义一个内部类,用于存放有方法体的方法
public static final class DefaultImpls
public static void plus(InterfaceTest $this, int num)
$this.setCount($this.getCount() + num);
//实现我们上面定义的接口
public final class Impl implements InterfaceTest
private int count;
public int getCount()
return this.count;
public void setCount(int var1)
this.count = var1;
//Kotlin 会自动为我们生成 plus 方法,方法体就是上面内部类封装好的 plus 方法
public void plus(int num)
InterfaceTest.DefaultImpls.plus(this, num);
通过反编译,Kotlin 接口里可以定义有方法体的方法也没有什么好神奇的。
就是通过内部类封装好了带有方法体的方法,然后实现类会自动生成方法
这个特性还是挺有用的,当我们不想是使用抽象类时,具有该特性的 Interface 就派上用场了
lambda 表达式
在 Java8 之前,lambda 表达式在 Java 中都是没有的,下面我们来简单的体验一下 lambda 表达式:
//在android中为按钮设置点击事件
button.setOnClickListener(new View.OnClickListener()
@override
public void onClick(View v)
//todo something
);
//在Kotlin中使用lambda
button.setOnClickListenerview ->
//todo something
可以发现使用 lambda 表达式,代码变得非常简洁。下面我们就来深入探讨下 lambda 表达式。
什么是 lambda 表达式
我们先从 lambda 最基本的语法开始,引用一段 Kotlin in Action 中对 lambda 的定义:

总的来说,主要有 3 点:
- lambda 总是放在一个花括号里 ()
- 箭头左边是 lambda 参数 (lambda parameter)
- 箭头右边是 lambda 体 (lambda body)
我们再来看上面简单的 lambda 实例:
button.setOnClickListenerview -> //view是lambda参数
//lambda体
//todo something
lambda 表达式与 Java 的 functional interface
上面的 OnClickListener 接口和 Button 类是定义在 Java 中的。
该接口只有一个抽象方法,在 Java 中这样的接口被称作 functional interface 或 SAM (single abstract method)
因为我们在实际的工作中可能和 Java 定义的 API 打的交道最多了,因为 Java 这么多年的生态,我们无处不再使用 Java 库,
所以在 Kotlin 中,如果某个方法的参数是 Java 定义的 functional interface,Kotlin 支持把 lambda 当作参数进行传递的。
需要注意的是,Kotlin 这样做是指方便的和 Java 代码进行交互。但是如果在 Kotlin 中定义一个方法,它的参数类型是functional interface,是不允许直接将 lambda 当作参数进行传递的。如:
//在Kotlin中定义一个方法,参数类型是Java中的Runnable
//Runnable是一个functional interface
fun postDelay(runnable: Runnable)
runnable.run()
//把lambda当作参数传递是不允许的
postDelay
println("postDelay")
在 Kotlin 中调用 Java 方法,能够将 lambda 当作参数传递,需要满足两个条件:
- 该 Java 方法的参数类型是 functional interface (只有一个抽象方法)
- 该 functional interface 是 Java 定义的,如果是 Kotlin 定义的,就算该接口只有一个抽象方法,也是不行的
如果 Kotlin 定义了方法想要像上面一样,把 lambda 当做参数传递,可以使用高阶函数。这个后面会介绍。
Kotlin 允许 lambda 当作参数传递,底层也是通过构建匿名内部类来实现的:
fun main(args: Array<String>)
val button = Button()
button.setOnClickListener
println("click 1")
button.setOnClickListener
println("click 2")
//编译后对应的 Java 代码:
public final class FunctionalInterfaceTestKt
public static final void main(@NotNull String[] args)
Intrinsics.checkParameterIsNotNull(args, "args");
Button button = new Button();
button.setOnClickListener((OnClickListener)null.INSTANCE);
button.setOnClickListener((OnClickListener)null.INSTANCE);
发现反编译后对应的 Java 代码有的地方可读性也不好,这是 Kotlin 插件的 bug,比如 (OnClickListener)null.INSTANCE
所以这个时候需要看下它的 class 字节码:
//内部类1
final class lambda/FunctionalInterfaceTestKt$main$1 implements lambda/Button$OnClickListener
public final static Llambda/FunctionalInterfaceTestKt$main$1; INSTANCE
//...
//内部类2
final class lambda/FunctionalInterfaceTestKt$main$2 implements lambda/Button$OnClickListener
public final static Llambda/FunctionalInterfaceTestKt$main$2; INSTANCE
//...
//main函数
// access flags 0x19
public final static main([Ljava/lang/String;)V
@Lorg/jetbrains/annotations/NotNull;() // invisible, parameter 0
L0
ALOAD 0
LDC "args"
INVOKESTATIC kotlin/jvm/internal/Intrinsics.checkParameterIsNotNull (Ljava/lang/Object;Ljava/lang/String;)V
L1
LINENUMBER 10 L1
NEW lambda/Button
DUP
INVOKESPECIAL lambda/Button.<init> ()V
ASTORE 1
L2
LINENUMBER 11 L2
ALOAD 1
GETSTATIC lambda/FunctionalInterfaceTestKt$main$1.INSTANCE : Llambda/FunctionalInterfaceTestKt$main$1;
CHECKCAST lambda/Button$OnClickListener
INVOKEVIRTUAL lambda/Button.setOnClickListener (Llambda/Button$OnClickListener;)V
从中可以看出,它会新建 2 个内部类,内部类会暴露一个 INSTANCE 实例供外界使用。
也就是说传递 lambda 参数多少次,就会生成多少个内部类
但是不管这个 main 方法调用多少次,一个 setOnClickListener,都只会有一个内部类对象,因为暴露出来的 INSTANCE 是一个常量
我们再来调整一下 lambda 体内的实现方式:
fun main(args: Array<String>)
val button = Button()
var count = 0
button.setOnClickListener
println("click $++count")
button.setOnClickListener
println("click $++count")
也就是 lambda 体里面使用了外部变量了,再来看下反编译后的 Java 代码:
public static final void main(@NotNull String[] args)
Intrinsics.checkParameterIsNotNull(args, "args");
Button button = new Button();
final IntRef count = new IntRef();
count.element = 0;
button.setOnClickListener((OnClickListener)(new OnClickListener()
public final void click()
StringBuilder var10000 = (new StringBuilder()).append("click ");
IntRef var10001 = count;
++count.element;
String var1 = var10000.append(var10001.element).toString();
System.out.println(var1);
));
button.setOnClickListener((OnClickListener)(new OnClickListener()
public final void click()
StringBuilder var10000 = (new StringBuilder()).append("click ");
IntRef var10001 = count;
++count.element;
String var1 = var10000.append(var10001.element).toString();
System.out.println(var1);
));
从中发现,每次调用 setOnClickListener 方法的时候都会 new 一个新的内部类对象
由此,我们做一个小结:
- 一个 lambda 对应一个内部类
- 如果 lambda 体里没有使用外部变量,则调用方法时只会有一个内部类对象
- 如果 lambda 体里使用了外部变量,则每调用一次该方法都会新建一个内部类对象
lambda 表达式赋值给变量
lambda 除了可以当作参数进行传递,还可以把 lambda 赋值给一个变量:
//定义一个 lambda,赋值给一个变量
val sum = x: Int, y: Int, z: Int ->
x + y + z
fun main(args: Array<String>)
//像调用方法一样调用lambda
println(sum(12, 10, 15))
//控制台输出:37
接下来分析来其实现原理,反编译查看其对应的 Java 代码:
public final class LambdaToVariableTestKt
@NotNull
private static final Function3 sum;
@NotNull
public static final Function3 getSum()
return sum;
public static final void main(@NotNull String[] args)
Intrinsics.checkParameterIsNotNull(args, "args");
int var1 = ((Number)sum.invoke(12, 10, 15)).intValue();
System.out.println(var1);
static
sum = (Function3)null.INSTANCE;
其对应的 Java 代码是看不到具体的细节的,而且还是会有 null.INSTANCE 的情况,但是我们还是可以看到主体逻辑。
但由 于class 字节篇幅很大,就不贴出来了,通过我们上面的分析,INSTANCE 是一个常量,在这里也是这样的:
首先会新建一个内部类,该内部类实现了接口 kotlin/jvm/functions/Function3,为什么是 Function3 因为我们定义的 lambda 只有 3 个参数。
所以 lambda 有几个参数对应的就是 Function 几,最多支持 22 个参数,也就是Function22。我们把这类接口称之为 FunctionN。
然后内部类实现了接口的 invoke 方法,invoke 方法体里的代码就是 lambda 体的代码逻辑。
这个内部类会暴露一个实例常量 INSTANCE,供外界使用。
如果把上面 Kotlin 的代码放到一个类里,然后在 lambda 体里使用外部的变量,那么每调用一次 sum 也会创建一个新的内部类对象,上面我们对 lambda 的小结在这里依然是有效的。
上面 setOnClickListener 的例子,我们传了两个 lambda 参数,生成了两个内部类,我们也可以把监听事件的 lambda 赋值给一个变量:
val button = Button()
val listener = Button.OnClickListener
println("click event")
button.setOnClickListener(listener)
button.setOnClickListener(listener)
这样对于 OnClickListener 接口,只会有一个内部类。
从这个例子中我们发现,className 这样的格式也能创建一个对象,这是因为接口 OnClickListener 是 SAM interface,只有一个抽象函数的接口。
编译器会生成一个 SAM constructor,这样便于把一个 lambda 表达式转化成一个 functional interface 实例对象。
至此,我们又学到了另一种创建对象的方法。
做一个小结,在 Kotlin 中常规的创建对象的方式(除了反射、序列化等):
- 类名后面接括号,格式:className()
- 创建内部类对象,格式:object : className
- SAM constructor 方式,格式:className
高阶函数
由于高阶函数和 lambda 表达式联系比较紧密,在不介绍高阶函数的情况下,lambda 有些内容无法讲,所以在高阶函数这部分,还将会继续分析lambda表达式。
高阶函数的定义
如果某个函数是以另一个函数作为参数或者返回值是一个函数,我们把这样的函数称之为高阶函数
比如 Kotlin 库里的 filter 函数就是一个高阶函数:
//Kotlin library filter function
public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T>
//调用高阶函数 filter,直接传递 lambda 表达式
list.filter person ->
person.age > 18
filter 函数定义部分 predicate: (T) -> Boolean 格式有点像 lambda,但是又不是,传参的时候又可以传递 lambda 表达式。
弄清这个问题之前,我们先来介绍下 function type,它格式如下:
名称 : (参数) -> 返回值类型
- 冒号左边是
function type的名字 - 冒号右边是参数
- 尖括号右边是返回值
比如:predicate: (T) -> Boolean predicate 就是名字,T 泛型就是参数,Boolean 就是返回值类型
高阶函数是以另一个函数作为参数或者其返回值是一个函数,也可以说高阶函数参数是 function type 或者返回值是 function type
在调用高阶函数的时候,我们可以传递 lambda,这是因为编译器会把 lambda 推导成 function type
高阶函数原理分析
我们定义一个高阶函数到底定义了什么?我们先来定义一个简单的高阶函数:
fun process(x: Int, y: Int, operate: (Int, Int) -> Int)
println(operate(x, y))
编译后代码如下:
public static final void process(int x, int y, @NotNull Function2 operate)
Intrinsics.checkParameterIsNotNull(operate, "operate");
int var3 = ((Number)operate.invoke(x, y)).intValue();
System.out.println(var3);
我们又看到了 FunctionN 接口了,上面介绍把 lambda 赋值给一个变量的时候讲到了 FunctionN 接口
发现高阶函数的 function type 编译后也会变成 FunctionN,所以能把 lambda 作为参数传递给高阶函数也是情理之中了
这是一个高阶函数编译后的情况,我们再来看下调用高阶函数的情况:
//调用高阶函数,传递一个 lambda 作为参数
process(a, b) x, y ->
x * y
//编译后的字节码:
GETSTATIC higher_order_function/HigherOrderFuncKt$main$1.INSTANCE : Lhigher_order_function/HigherOrderFuncKt$main$1;
CHECKCAST kotlin/jvm/functions/Function2
INVOKESTATIC higher_order_function/HigherOrderFuncKt.process (IILkotlin/jvm/functions/Function2;)V
发现会生成一个内部类,然后获取该内部类实例,这个内部类实现了 FunctionN。介绍 lambda 的时候,我们说过了 lambda会编译成 FunctionN
如果 lambda 体里使用了外部变量,那每次调用都会创建一个内部类实例,而不是 INSTANCE 常量实例,这个也在介绍lambda 的时候说过了。
再探 lambda 表达式
lambda 表达式参数和 function type 参数
除了 filter,还有常用的 forEach 也是高阶函数:
//list 里是 Person 集合
//遍历list集合
list.forEach person ->
println(person.name)
我们调用 forEach 函数的传递 lambda 表达式,lambda 表达式的参数是 person,那为什么参数类型是集合里的元素 Person,而不是其他类型呢?比是集合类型?
到底是什么决定了我们调用高阶函数时传递的 lambda 表达式的参数是什么类型呢?
我们来看下 forEach 源码:
public inline fun <T> Iterable<T>.forEach(action: (T) -> Unit): Unit
for (element in this) action(element)
发现里面对集合进行 for 循环,然后把集合元素作为参数传递给 action (function type)
所以,调用高阶函数时,lambda 参数是由 function type 的参数决定的
lambda receiver
我们再看下 Kotlin 高阶函数 apply,它也是一个高阶函数,调用该函数时 lambda 参数是调用者本身 this:
list.apply //lambda 参数是 this,也就是 List
println(this)
我们看下 apply 函数的定义:
public inline fun <T> T.apply(block: T.() -> Unit): T
发现 apply 函数的的 function type 有点不一样,block: T.() -> Unit 在括号前面有个 T.
调用这样的高阶函数时,lambda 参数是 this,我们把这个 this 称之为 lambda receiver
把这类 lambda 称之为带有接受者的 lambda 表达式 (lambda with receiver)
这样的 lambda 在编写代码的时候提供了很多便利,调用所有关于 this 对象的方法 ,都不需要 this.,直接写方法即可,如下面的属于 StringBuilder 的 append 方法:
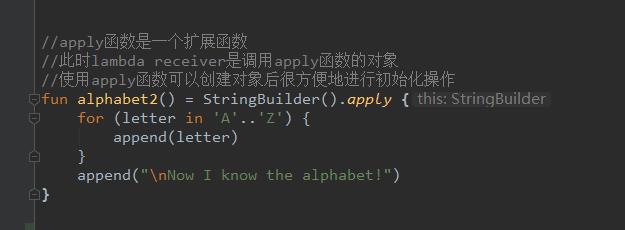
除了 apply,函数 with、run 的 lambda 参数都是 this:
public inline fun <T> T.apply(block: T.() -> Unit): T
public inline fun <T, R> T.run(block: T.() -> R): R
public inline fun <T, R> with(receiver: T, block: T.() -> R): R
它们三者都能完成彼此的功能:
//apply
fun alphabet2() = StringBuilder().apply
for (letter in 'A'..'Z')
append(letter)
append("\\nNow I know the alphabet!")
//with
fun alphabet() = with(StringBuilder())
for (letter in 'A'..'Z')
append(letter)
append("\\nNow I know alphabet!").toString()
//run
fun alphabet3() = StringBuilder().run
for (c in 'A'..'Z')
append(c)
append("\\nNow I know the alphabet!")
高阶函数 let、with、apply、run 总结
1) let 函数一般用于判断是否为空
//let 函数的定义
public inline fun <T, R> T.let(block: (T) -> R): R
return block(this)
//let 的使用
message?.let //lambda参数it是message
val result = it.substring(1)
println(result)
2) with 是全局函数,apply 是扩展函数,其他的都一样
3) run 函数的 lambda 是一个带有接受者的 lambda,而 let 不是,除此之外功能差不多
public inline fun <T, R> T.run(block: T.() -> R): R
public inline fun <T, R> T.let(block: (T) -> R): R
所以 let 能用于空判断,run 也可以:

高阶函数的优化
通过上面我们对高阶函数原理的分析:在调用高阶函数的时候 ,会生成一个内部类。
如果这个高阶函数被程序中很多地方调用了,那么就会有很多的内部类,那么程序的体积就会变得不可控了。
而且如果调用高阶函数的时候,lambda 体里使用了外部变量,则会每次创建新的对象。
所以需要对高阶函数进行优化下。
上面我们在介绍 kotlin 内置的一些的高阶函数如 let、run、with、apply,它们都是内联函数,使用 inline 关键字修饰
内联 inline 是什么意思呢?就是在调用 inline 函数的地方,编译器在编译的时候会把内联函数的逻辑拷贝到调用的地方。
依然以在介绍高阶函数原理那节介绍的 process 函数为例:
//使用 inline 修饰高阶函数
inline fun process(x: Int, y: Int, operate: (Int, Int) -> Int)
println(operate(x, y))
fun main(args: Array<String>)
val a = 11
val b = 2
//调用 inline 的高阶函数
process(a, b) x, y ->
x * y
//编译后对应的 Java 代码:
public static final void main(@NotNull String[] args)
int a = 11;
int b = 2;
int var4 = a * b;
System.out.println(var4);
Kotlin泛型
要想掌握 Kotlin 泛型,需要对 Java 的泛型有充分的理解。掌握 Java 泛型后 ,Kotlin 的泛型就很简单了。
所以我们先来看下 Java 泛型相关的知识点:
Java 泛型:不变性 (invariance)、协变性 (covariance)、逆变性 (contravariance)
我们先定义两个类:Plate、Food、Fruit
//定义一个`盘子`类
public class Plate<T>
private T item;
public Plate(T t)
item = t;
public void set(T t)
item = t;
public T get()
return item;
//食物
public class Food
//水果类
public class Fruit extends Food
然后定义一个takeFruit()方法
private static void takeFruit(Plate<Fruit> plate)
然后调用takeFruit方法,把一个装着苹果的盘子传进去:
takeFruit(new Plate<Apple>(new Apple())); //泛型之不变
发现编译器报错,发现装着苹果的盘子竟然不能赋值给装着水果的盘子,这就是泛型的不变性 (invariance)
这个时候就要引出泛型的协变性了
1) 协变性
假设我就要把一个装着苹果的盘子赋值给一个装着水果的盘子呢?
我们来修改下 takeFruit 方法的参数 (? extends Fruit):
private static void takeFruit(Plate<? extends Fruit> plate)
然后调用 takeFruit 方法,把一个装着苹果的盘子传进去:
takeFruit(new Plate<Apple>(new Apple())); //泛型的协变
这个时候编译器不报错了,而且你不仅可以把装着苹果的盘子放进去,还可以把任何继承了 Fruit 类的水果都能放进去:
//包括自己本身 Fruit 也可以放进去
takeFruit(new Plate<Fruit>(new Fruit()));
takeFruit(new Plate<Apple>(new Apple()));
takeFruit(new Plate<Pear>(new Pear()));
takeFruit(new Plate<Banana>(new Banana()));
在 Java 中把 ? extends Type 类似这样的泛型,称之为 上界通配符(Upper Bounds Wildcards)
为什么叫上界通配符?因为 Plate<? extends Fruit>,可以存放 Fruit 和它的子类们,最高到 Fruit 类为止。所以叫上界通配符
好,现在编译器不报错了,我们来看下 takeFruit 方法体里的一些细节:
private static void takeFruit(Plate<? extends Fruit> plate)
//plate5.set(new Fruit()); //编译报错
//plate5.set(new Apple()); //编译报错
Fruit fruit = plate5.get(); //编译正常
发现 takeFruit() 的参数 plate 的 set 方法不能使用了,只有 get 方法可以使用。如果我们需要调用 set 方法呢?
这个时候就需要引入泛型的逆变性了
2) 逆变性
修改下泛型的形式 (extends 改成 super):
private static void takeFruit(Plate<? super Fruit> plate)
plate.set(new Apple()); //编译正常
//Fruit fruit = plate.get(); //编译报错
//Fruit pear = plate.get(); //编译报错
发现 set 方法可以用了,但是 get 方法“失效”了。我们把类似 ? super Type 这样的泛型,称之为下界通配符(Lower Bounds Wildcards)
在介绍上界通配符 (extends) 的时候,我们知道上界通配符的泛型可以存放该类型的和它的子类们。
那么,下界通配符 (super) 顾名思义就是能存放 该类型和它的父类们。所以对于 Plate<? super Fruit> 只能放进 Fruit 和 Food。
我们在回到刚刚说到的 set 和 get 方法:set 方法的参数是该泛型;get 方法的返回值是该泛型
也就是说上界通配符 (extends),只允许获取 (get),不允许修改 (set)。可以理解为只生产(返回给别人用),不消费。
下界通配符 (super),只允许修改 (set),不允许获取 (get)。可以理解为只消费 (set 方法传进来的参数可以使用了),不生产。
可以总结为:PECS(Producer Extends, Consumer Super)
3) 泛型小结
- 上界通配符的泛型可以存放
该类型的和它的子类们,下界通配符能存放该类型和它的父类们
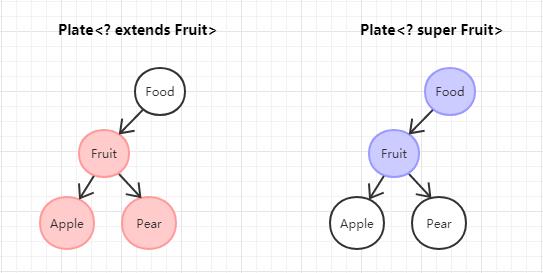
- PECS(Producer Extends, Consumer Super)
上界通配符一般用于读取,下界通配符一般用于修改。比如 Java 中 Collections.java 的 copy 方法:
public static <T> void copy(List<? super T> dest, List<? extends T> src)
int srcSize = src.size();
if (srcSize > dest.size())
throw new IndexOutOfBoundsException("Source does not fit in dest");
if (srcSize < COPY_THRESHOLD ||
(src instanceof RandomAccess && dest instanceof RandomAccess))
for (int i=0; i<srcSize; i++)
dest.set(i, src.get(i));
else
ListIterator<? super T> di=dest.listIterator();
ListIterator<? extends T> si=src.listIterator();
for (int i=0; i<srcSize; i++)
di.next();
di.set(si.next());
dest 参数只用于修改,src 参数用于读取操作,只读 (read-only)
通过泛型的协变逆变来控制集合是只读,还是只改。使得程序代码更加优雅。
Kotlin 泛型的协变、逆变
掌握了 Java 的泛型,Kotlin 泛型就简单很多了,大体上是一致的,但还有一些区别。我们挨个的来介绍下:
1) Kotlin 协变
关于泛型的不变性,Kotlin 和 Java都是一致的。比如 List<Apple> 不能赋值给 List<Fruit> 。
我们来看下 Kotlin 协变:
fun takeFruit(fruits: List<Fruit>)
fun main(args: Array<String>)
val apples: List<Apple> = listOf(Apple(), Apple())
takeFruit(apples)
编译器不会报错,为什么可以把 List<Apple> 赋值给 List<Fruit>,根据泛型不变性 ,应该会报错的。
不报错的原因是这里的 List 不是 java.util.List 而是 Kotlin 里的 List:
//kotlin Collection
public interface List<out E> : Collection<E>
//Java Collection
public interface List<E> extends Collection<E>
发现 Kotlin 的 List 泛型多了 out 关键字,这里的 out 关键相当于 java 的 extends 通配符
所以不仅可以把 List<Apple> 赋值给 List<Fruit>,Fruit 的子类都可以:
fun main(args: Array<String>)
val foods: List<Food> = listOf(Food(), Food())
val fruits: List<Fruit> = listOf(Fruit(), Fruit())
val apples: List<Apple> = listOf(Apple(), Apple())
val pears: List<Pear> = listOf(Pear(), Pear())
//takeFruit(foods) 编译报错
takeFruit(fruits)
takeFruit(apples)
takeFruit(pears)
2) Kotlin 逆变
out 关键字对应 Java 中的 extends 关键字,那么 Java 的 super 关键字对应 Kotlin 的 in 关键字
关于逆变 Kotlin 中的排序函数 sortedWith,就用到了 in 关键字:
public fun <T> Iterable<T>.sortedWith(comparator: Comparator<in T>): List<T>
//声明 3 个比较器
val foodComparator = Comparator<Food> e1, e2 ->
e1.hashCode() - e2.hashCode()
val fruitComparator = Comparator<Fruit> e1, e2 ->
e1.hashCode() - e2.hashCode()
val appleComparator = Comparator<Apple> e1, e2 ->
e1.hashCode() - e2.hashCode()
//然后声明一个集合
val list = listOf(Fruit(), Fruit(), Fruit(), Fruit())
//Comparator 声明成了逆变 (contravariant),这和 Java 的泛型通配符 super 一样的
//所以只能传递 Fruit 以及 Fruit 父类的 Comparator
list.sortedWith(foodComparator)
list.sortedWith(fruitComparator)
//list.sortedWith(appleComparator) 编译报错
3) Kotlin和Java在协变性、逆变性的异同点
Java 中的上界通配符 extends 和下界通配符 super,这两个关键字非常形象
extends 表示 只要 继承 了这个类包括其本身都能存放
super 表示 只要是这个类的父类包括其本身都能存放
同样的 Kotlin 中 out 和 in 关键字也很相像,这个怎么说呢?
在介绍 Java 泛型的时候说过,上界通配符 extends 只能 get (后者只能做出参,这就是 out),不能 set (意思就是不能参数传进来)。所以只能出参(out)
下界通配符 super 只能 set (意思就是可以入参,这就是 in),不能 get。所以只能入参(in)
Kotlin 和 Java 只是站在不同的角度来看这个问题而已。可能 Kotlin 的 in 和 out 更加简单明了,不用再记什么 PECS(Producer Extends, Consumer Super) 缩写了
除了关键字不一样,另一方面,Java 和 Kotlin关于泛型定义的地方也不一样。
在介绍 Java 泛型的时候,我们定义通配符的时候都是在方法上,比如:
void takeExtendsFruit(Plate<? extends Fruit> plate)
虽然Java支持在类上使用 ? extends Type,但是不支持 ? super Type,并且在类上定义了 ? extends Type,对该类的方法是起不到 只读、只写 约束作用的。
我们把 Java 上的泛型变异称之为:use-site variance,意思就是在用到的地方定义变异
在 Kotlin 中,不仅支持在用到的地方定义变异,还支持在定义类的时候声明泛型变异 (declaration-site variance)
比如上面的排序方法 sortedWith 就是一个 use-site variance:
public fun <T> Iterable<T>.sortedWith(comparator: Comparator<in T>): List<T>
再比如 Kotlin List,它就是 declaration-site variance,它在声明List类的时候,定义了泛型协变
这个时候会对该 List 类的方法产生约束:泛型不能当做方法入参,只能当做出参。Kotlin List 源码片段如下所示:
public interface List<out E> : Collection<E>
public operator fun get(index: Int): E
public fun listIterator(): ListIterator<E>
public fun listIterator(index: Int): ListIterator<E>
public fun subList(fromIndex: Int, toIndex: Int): List<E>
public fun indexOf(element: @UnsafeVariance E): Int
//省略其他代码
比如 get、subList 等方法泛型都是作为出参返回值的,我们也发现 indexOf 方法的参数竟然是泛型 E,不是说只能当做出参,不能是入参吗?
这里只是为了兼容 Java 的 List 的 API,所以加上了注解 @UnsafeVariance (不安全的协变),编译器就不会报错了。
例如我们自己定义一个 MyList 接口,不加 @UnsafeVariance 编译器就会报错了:
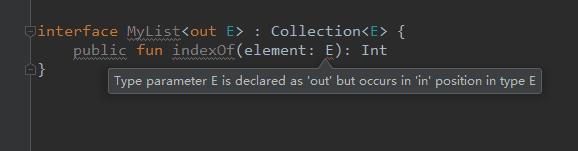
Kotlin 泛型擦除和具体化
Kotlin 和 Java 的泛型只在编译时有效,运行时会被擦除 (type erasure)。例如下面的代码就会报错:
//Error: Cannot check for instance of erased type: T
//fun <T> isType(value: Any) = value is T
Kotlin 提供了一种泛型具体化的技术,它的原理是这样的:
我们知道泛型在运行时会擦除,但是在 inline 函数中我们可以指定泛型不被擦除,
因为 inline 函数在编译期会 copy 到调用它的方法里,所以编译器会知道当前的方法中泛型对应的具体类型是什么,
然后把泛型替换为具体类型,从而达到不被擦除的目的,在 inline 函数中我们可以通过 reified 关键字来标记这个泛型在编译时替换成具体类型
如下面的代码就不会报错了:
inline fun <reified T> isType(value: Any) = value is T
泛型具体化的应用案例
我们在开发中,常常需要把 json 字符串解析成 Java bean 对象,但是我们不是知道 JSON 可以解析成什么对象,通常我们通过泛型来做。
但是我们在最底层把这个不知道的类封装成泛型,在具体运行的时候这个泛型又被擦除了,从而达不到代码重用的最大化。
比如下面一段代码,请求网络成功后把 JSON 解析(反射)成对象,然后把对象返回给上层使用:

从上面代码可以看出,CancelTakeoutOrderResponse 我们写了 5 遍.
那么我们对上面的代码进行优化下,上面的代码只要保证 Type 对象那里使用是具体的类型就能保证反射成功了
把这个 wrapCallable 方法在包装一层:

再看下优化后的 cancelTakeoutOrder 方法,发现 CancelTakeoutOrderResponse 需要写 2 遍:
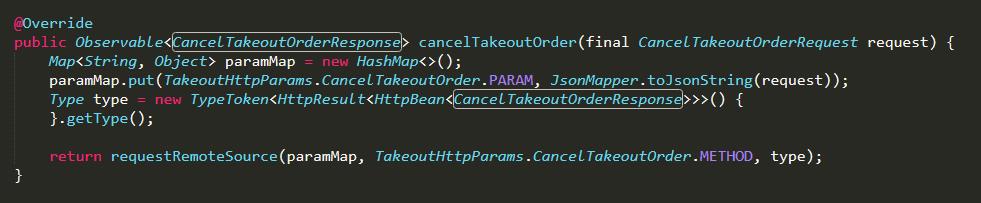
我们在使用 Kotlin 的泛型具体换,再来优化下:
因为泛型具体化是一个内联函数,所以需要把 requestRemoteSource 方法体积变小,所以我们包装一层:

再看下优化后的 cancelTakeoutOrder 方法,发现 CancelTakeoutOrderResponse 需要写 1 遍就可以了:

以上是关于从 Java 角度深入理解 Kotlin的主要内容,如果未能解决你的问题,请参考以下文章