Fiddler忽略捕捉大文件流
Posted lunarflyer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Fiddler忽略捕捉大文件流相关的知识,希望对你有一定的参考价值。
Fiddler是款非常不错的抓包软件,可以方便的捕捉各种软件发起的HTTP请求,甚至可以在发送给服务器前或响应给应用前修改数据。但是在使用时发现,在开启Fiddler时,在浏览器中下载文件时不会马上弹出文件下载框,过了很长一段时间后才会弹出,音乐播放器在切换歌曲时下一首歌曲也会卡顿很久。在关闭Fiddler后就不会出现这种情况。
观察Fiddler的抓包记录时,发现在浏览器中下载文件时,该记录的Result值为-,当由“-”变成“200”时,浏览器弹出了下载框,由此可以判断在下载文件时Fiddler会先将服务器返回的内容缓存起来,内容接收完毕后再一次性返回给应用程序。这种设计应该是为了方便调试修改数据包用,但是对于下载文件之类的操作就不是非常友好了。
Fiddler提供了非常强大的扩展功能,利用FiddlerScript可以个性化定制自己的需求,如定制化过滤数据包、个性化颜色等等。在右侧的FiddlerScript选项卡或菜单-Rule-Customize Rule可进入FiddlerScript的编辑界面。
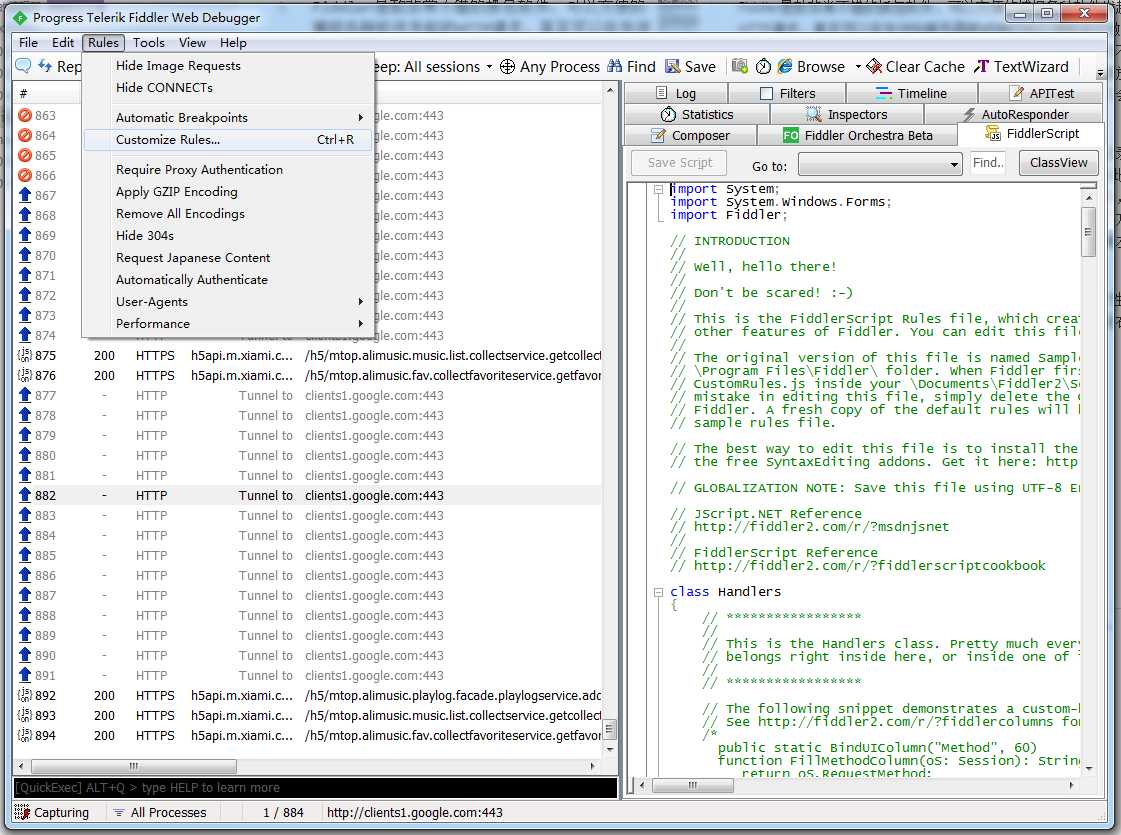
在编辑器中找到搜索OnPeekAtResponseHeaders函数,在函数主体最后加上如下代码:
if (oSession.ResponseHeaders["Content-Length"] > 102400) {
oSession.Ignore();
}OnPeekAtResponseHeaders是在接收到HTTP头之后执行的方法,通过判断HTTP头中Content-Length长度,如果大于100KB则让fiddler忽略此次抓包的请求。
保存后Fiddler会自动重新加载脚本,在浏览器中下载文档时直接弹出文件下载框,不再有卡顿的现象。
附:FiddlerScript知识库
http://docs.telerik.com/fiddler/KnowledgeBase/FiddlerScript/ModifyRequestOrResponse
以上是关于Fiddler忽略捕捉大文件流的主要内容,如果未能解决你的问题,请参考以下文章