StreamSets 多线程 Pipelines
Posted rongfengliang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了StreamSets 多线程 Pipelines相关的知识,希望对你有一定的参考价值。
以下为官方文档:
Multithreaded Pipeline Overview
A multithreaded pipeline is a pipeline with an origin that supports parallel execution, enabling one pipeline to run in multiple threads.
Multithreaded pipelines enable processing high volumes of data in a single pipeline on one Data Collector, thus taking full advantage of all available CPUs on the Data Collector machine. When using multithreaded pipelines, make sure to allocate sufficient resources to the pipeline and Data Collector.
A multithreaded pipeline honors the configured delivery guarantee for the pipeline, but does not guarantee the order in which batches of data are processed.
How It Works
When you configure a multithreaded pipeline, you specify the number of threads that the origin should use to generate batches of data. You can also configure the maximum number of pipeline runners that Data Collector uses to perform pipeline processing.
A pipeline runner is a sourceless pipeline instance - an instance of the pipeline that includes all of the processors and destinations in the pipeline and represents all pipeline processing after the origin.
Origins perform multithreaded processing based on the origin systems they work with, but the following is true for all origins that generate multithreaded pipelines:
When you start the pipeline, the origin creates a number of threads based on the multithreaded property configured in the origin. And Data Collector creates a number of pipeline runners based on the pipeline Max Runners property to perform pipeline processing. Each thread connects to the origin system and creates a batch of data, and passes the batch to an available pipeline runner.
Each pipeline runner processes one batch at a time, just like a pipeline that runs on a single thread. When the flow of data slows, the pipeline runners wait idly until they are needed, generating an empty batch at regular intervals. You can configure the Runner Idle Time pipeline property specify the interval or to opt out of empty batch generation.
Multithreaded pipelines preserve the order of records within each batch, just like a single-threaded pipeline. But since batches are processed by different pipeline instances, the order that batches are written to destinations is not ensured.
For example, take the following multithreaded pipeline. The HTTP Server origin processes HTTP POST and PUT requests passed from HTTP clients. When you configure the origin, you specify the number of threads to use - in this case, the Max Concurrent Requests property:
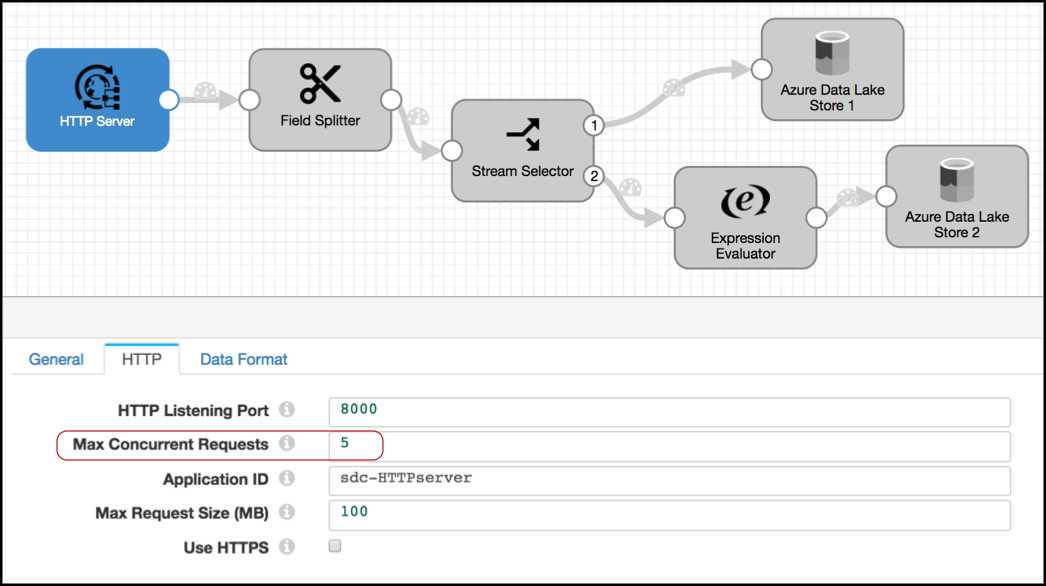
Let‘s say you configure the pipeline to opt out of the Max Runners property. When you do this, Data Collector generates a matching number of pipeline runners for the number of threads.
With Max Concurrent Requests set to 5, when you start the pipeline the origin creates five threads and Data Collector creates five pipeline runners. Upon receiving data, the origin passes a batch to each of the pipeline runners for processing.
Conceptually, the multithreaded pipeline looks like this:
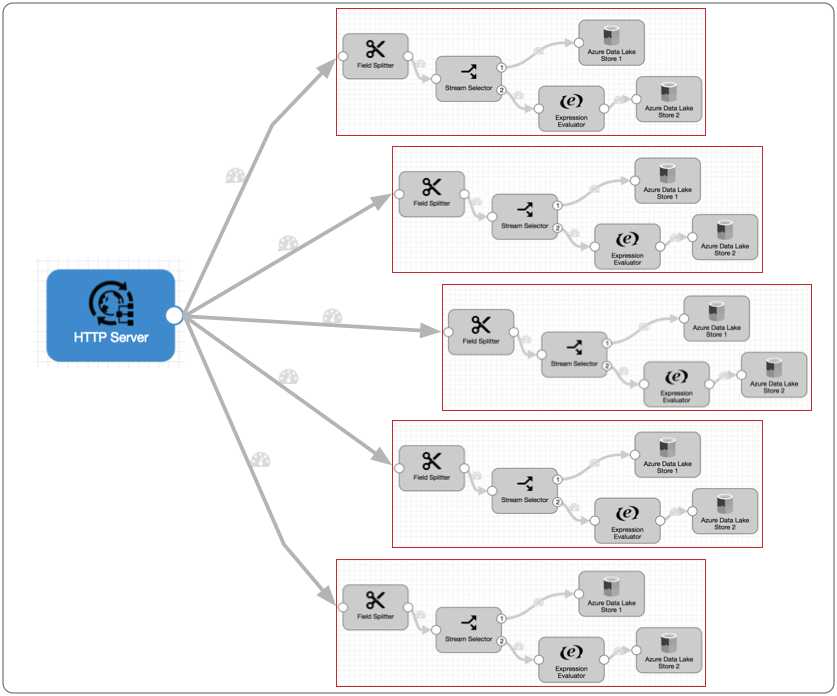
Each pipeline runner performs the processing associated with the rest of the pipeline. After a batch is written to pipeline destinations - in this case, Azure Data Lake Store 1 and 2 - the pipeline runner becomes available for another batch of data. Each batch is processed and written as quickly as possible, independently from batches processed by other pipeline runners, so the write-order of the batches can differ from the read-order.
At any given moment, the five pipeline runners can each process a batch, so this multithreaded pipeline processes up to five batches at a time. When incoming data slows, the pipeline runners sit idle, available for use as soon as the data flow increases.
以上是关于StreamSets 多线程 Pipelines的主要内容,如果未能解决你的问题,请参考以下文章
StreamSets学习系列之StreamSets的集群安装(图文详解)