做不背锅的运维
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了做不背锅的运维相关的知识,希望对你有一定的参考价值。
系统除了故障,第一个挨板子的就是运维人员。不管任何原因,先找运维,给他一口好锅。运维好苦啊!稳定运行时,似乎是多余的存在;又问题时,要替人背锅。与其被动,不如主动一点,不做背锅侠!
怎么做呢?先看几个例子,亲身经历。
砸锅例一
一支付系统,前端负载均衡,中间tomcat应用,后端memcached加oracle 11G rac两节点集群。遇上好的时机,公司的业务增长很快,但人手有限,跟不上业务的发展,只好尽可能的先上线,发现问题再修正。
某天,在西四环帮人排查宾馆wifi故障,楼里手机信号极差。还没查出什么原因,技术就打电话来质问:“你配的oracle最大连接数,真有3000个么?怎么到300就卡死了?”。赶紧跑到室外,坐在地上用手机打开wifi热点,用笔记本连数据库,load确实很高。还没查出什么原因,那边老板也来电话催促,说业务无法交易。我想,反正无法交易,不如把tomcat停一下,看数据库负载是不是会降下来。在征得同意以后,关掉killall -9 java 关闭tomcat,片刻orace负载下降明显;再启动时,负载狂飙,最高可到600多。
对oracle的一些配置进行了检查,性能未能得到任何改善。于是跟开发人员进行沟通,问他们近期是否做了项目更新?答复是肯定的,但无法确定是哪里的问题引起性能上的问题。我建议在应用服务器上安装某性能监控探针,获得许可,很快就部署完毕。等待10来分钟,数据就出来了。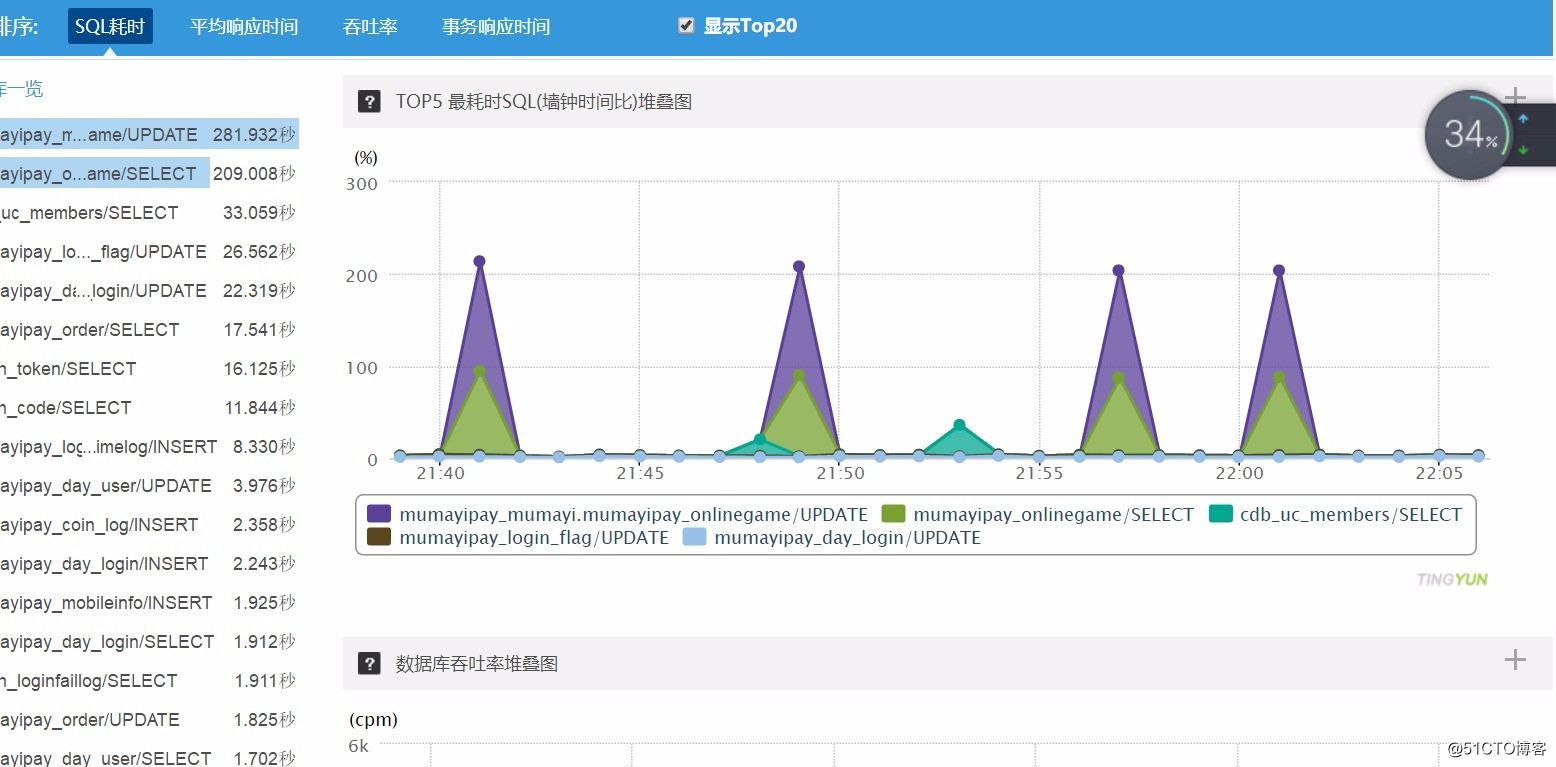
说明:本图不是事发时截取的,仅仅是为了方便读者了解。
一帮人紧急召集到一块,从性能探针的管理页面找出最耗资源的sql语句进行代码还原(程序员来查这个代码是什么功能)。一番动作之后,告知是后台管理操作--运营人员及代理商查询当日交易数据,由于产品设计上的缺陷,只要数十人同时进行此项操作,数据库就会直接挂起。
这个后台设计上的缺陷主要有一下几点:
- 管理后台登陆时,会查询所有代理商的数据,代理商会查询下级代理商的数据。而不管是哪一级的登陆,都会顺带查询其下最终用户的数据。如此叠加,产生巨大的数据查询量。
- 数据的统计,不是字段值做数学运算,而是以 select count() 的方式进行。这比单独做一个表,把字段值做数学运算要耗资源。
- 不管有无需要,都抓取最终用户的交易详情。总用户数有300多万,运营人员一打开统计,就会去查询这些记录;代理商也是这样,只不过记录数会少一些,但多人操作,就会重复查询,给数据库造成巨大的压力。
负责技术的老总坦承,其实大部分管理,最关心的是总额,很少去挨个查看详情。如果需要查看,再按一定条件去执行这个操作。
弄清了问题,程序员马上去落实,更新代码以后,问题得以彻底的解决。
砸锅例二
夏初的时候,上线了一个区块链媒体项目。预估到流量会比较可观,不仅采购的云主机配置高,而且还是多台,并且购买了负载均衡服务。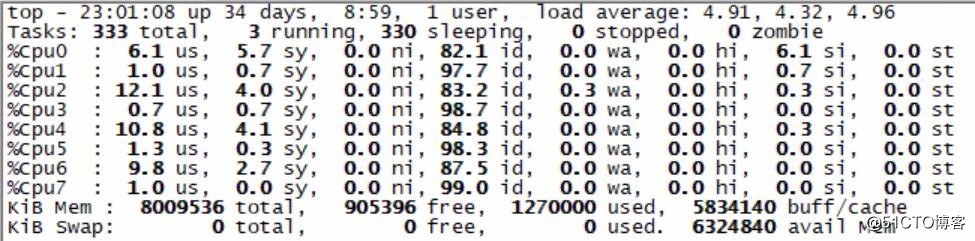
可万万没想到,项目一上线,还没做任何宣传,集群中所有服务器的负载都飚得老高,load接近1000,还好没死机,还能远程ssh登陆。
以上是关于做不背锅的运维的主要内容,如果未能解决你的问题,请参考以下文章
不背锅运维:Go实现aes加密,并带你手撸一个命令行应用程序