日志打入kafka改造历程-我们到底能走多远系列49
Posted killbug
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日志打入kafka改造历程-我们到底能走多远系列49相关的知识,希望对你有一定的参考价值。
方案
日志收集的方案有很多,包括各种日志过滤清洗,分析,统计,而且看起来都很高大上。本文只描述一个打入kafka的功能。
流程:app->kafka->logstash->es->kibana
业务应用直接将日志打入kafka,然后由logstash消费,数据进入es。
另一方面,应用在服务器上会打日志文件。
如图:
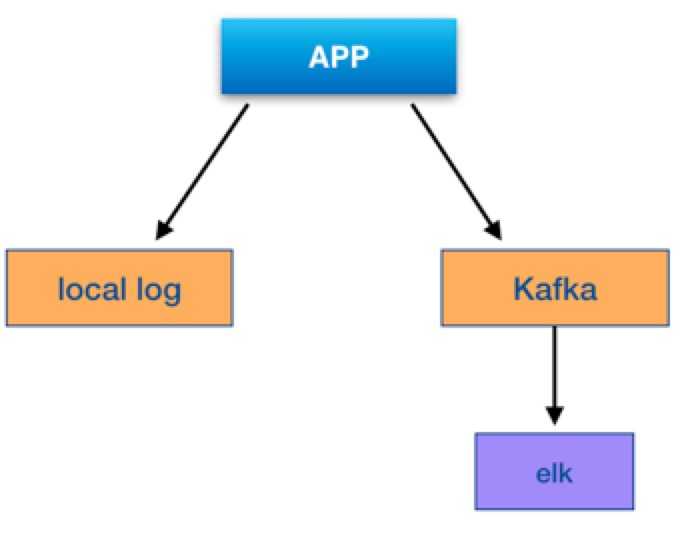
详细
初步实现
首先,我们来初步实现这个方案,搭建elk略去不谈,其中特别注意各个版本的兼容。这里主要在代码层面讲解如何实现的历程。
要将日志数据写入kafka,我们想只要依赖官方提供的kafka client就可以了,翻看github,有现成的:链接
没多少代码,通看一遍,在此基础上进行修改即可。
以下代码在spring boot框架基础。
核心appender代码:
public class KafkaAppender<E> extends KafkaAppenderConfig<E> {
/**
* Kafka clients uses this prefix for its slf4j logging.
* This appender defers appends of any Kafka logs since it could cause harmful infinite recursion/self feeding effects.
*/
private static final String KAFKA_LOGGER_PREFIX = "org.apache.kafka.clients";
public static final Logger logger = LoggerFactory.getLogger(KafkaAppender.class);
private LazyProducer lazyProducer = null;
private final AppenderAttachableImpl<E> aai = new AppenderAttachableImpl<E>();
private final ConcurrentLinkedQueue<E> queue = new ConcurrentLinkedQueue<E>();
private final FailedDeliveryCallback<E> failedDeliveryCallback = new FailedDeliveryCallback<E>() {
@Override
public void onFailedDelivery(E evt, Throwable throwable) {
aai.appendLoopOnAppenders(evt);
}
};
public KafkaAppender() {
// setting these as config values sidesteps an unnecessary warning (minor bug in KafkaProducer)
addProducerConfigValue(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getName());
addProducerConfigValue(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getName());
}
@Override
public void doAppend(E e) {
ensureDeferredAppends();
if (e instanceof ILoggingEvent && ((ILoggingEvent)e).getLoggerName().startsWith(KAFKA_LOGGER_PREFIX)) {
deferAppend(e);
} else {
super.doAppend(e);
}
}
@Override
public void start() {
// only error free appenders should be activated
if (!checkPrerequisites()) return;
lazyProducer = new LazyProducer();
super.start();
}
@Override
public void stop() {
super.stop();
if (lazyProducer != null && lazyProducer.isInitialized()) {
try {
lazyProducer.get().close();
} catch (KafkaException e) {
this.addWarn("Failed to shut down kafka producer: " + e.getMessage(), e);
}
lazyProducer = null;
}
}
@Override
public void addAppender(Appender<E> newAppender) {
aai.addAppender(newAppender);
}
@Override
public Iterator<Appender<E>> iteratorForAppenders() {
return aai.iteratorForAppenders();
}
@Override
public Appender<E> getAppender(String name) {
return aai.getAppender(name);
}
@Override
public boolean isAttached(Appender<E> appender) {
return aai.isAttached(appender);
}
@Override
public void detachAndStopAllAppenders() {
aai.detachAndStopAllAppenders();
}
@Override
public boolean detachAppender(Appender<E> appender) {
return aai.detachAppender(appender);
}
@Override
public boolean detachAppender(String name) {
return aai.detachAppender(name);
}
@Override
protected void append(E e) {
// encode 逻辑
final byte[] payload = encoder.doEncode(e);
final byte[] key = keyingStrategy.createKey(e);
final ProducerRecord<byte[], byte[]> record = new ProducerRecord<byte[],byte[]>(topic, key, payload);
Producer producer = lazyProducer.get();
if(producer == null){
logger.error("kafka producer is null");
return;
}
// 核心发送方法
deliveryStrategy.send(lazyProducer.get(), record, e, failedDeliveryCallback);
}
protected Producer<byte[], byte[]> createProducer() {
return new KafkaProducer<byte[], byte[]>(new HashMap<String, Object>(producerConfig));
}
private void deferAppend(E event) {
queue.add(event);
}
// drains queue events to super
private void ensureDeferredAppends() {
E event;
while ((event = queue.poll()) != null) {
super.doAppend(event);
}
}
/**
* Lazy initializer for producer, patterned after commons-lang.
*
* @see <a href="https://commons.apache.org/proper/commons-lang/javadocs/api-3.4/org/apache/commons/lang3/concurrent/LazyInitializer.html">LazyInitializer</a>
*/
private class LazyProducer {
private volatile Producer<byte[], byte[]> producer;
private boolean initialized;
public Producer<byte[], byte[]> get() {
Producer<byte[], byte[]> result = this.producer;
if (result == null) {
synchronized(this) {
if(!initialized){
result = this.producer;
if(result == null) {
// 注意 这里initialize可能失败,比如传入servers为非法字符,返回producer为空,所以只用initialized标记来确保不进行重复初始化,而避免不断出错的初始化
this.producer = result = this.initialize();
initialized = true;
}
}
}
}
return result;
}
protected Producer<byte[], byte[]> initialize() {
Producer<byte[], byte[]> producer = null;
try {
producer = createProducer();
} catch (Exception e) {
addError("error creating producer", e);
}
return producer;
}
public boolean isInitialized() { return producer != null; }
}
}以上代码对producer生产时进行initialized标记,确保在异常场景时只生产一次。
在实际场景中比如我们的servers配置非ip的字符,initialize方法会返回null,因为判断是否进行initialize()方法是判断producer是否为空,所以进入不断失败的情况,从而导致应用启动失败。
配置logback-spring.xml:
<springProperty scope="context" name="LOG_KAFKA_SERVERS" source="application.log.kafka.bootstrap.servers"/>
<springProperty scope="context" name="LOG_KAFKA_TOPIC" source="application.log.kafka.topic"/>
<appender name="KafkaAppender" class="com.framework.common.log.kafka.KafkaAppender">
<topic>${LOG_KAFKA_TOPIC}</topic>
<producerConfig>bootstrap.servers=${LOG_KAFKA_SERVERS}</producerConfig>
</appender>bootstrap.properties配置:
application.log.kafka.bootstrap.servers=10.0.11.55:9092
application.log.kafka.topic=prod-java在打入kafka的json进行自定义,上面的encoder.doEncode(e)进行扩展:
public class FormatKafkaMessageEncoder<E> extends KafkaMessageEncoderBase<E> {
protected static final int BUILDER_CAPACITY = 2048;
protected static final int LENGTH_OPTION = 2048;
public static final String CAUSED_BY = "Caused by: ";
public static final String SUPPRESSED = "Suppressed: ";
public static final char TAB = ' ';
public byte[] encode(ILoggingEvent event) {
Map<String, String> formatMap = new HashMap<>();
formatMap.put("timestamp", event.getTimeStamp()!=0?String.valueOf(new Date(event.getTimeStamp())):"");
formatMap.put("span", event.getMDCPropertyMap()!=null?event.getMDCPropertyMap().get("X-B3-SpanId"):"");
formatMap.put("trace", event.getMDCPropertyMap()!=null?event.getMDCPropertyMap().get("X-B3-TraceId"):"");
formatMap.put("class", event.getLoggerName());
formatMap.put("level", event.getLevel() != null?event.getLevel().toString():"");
formatMap.put("message", event.getMessage());
formatMap.put("stacktrace", event.getThrowableProxy()!=null?convertStackTrace(event.getThrowableProxy()):"");
formatMap.put("thread", event.getThreadName());
formatMap.put("ip", IpUtil.getLocalIP());
formatMap.put("application", event.getLoggerContextVO()!=null&&event.getLoggerContextVO().getPropertyMap()!=null?
event.getLoggerContextVO().getPropertyMap().get("springAppName"):"");
String formatJson = JSONObject.toJSONString(formatMap);
return formatJson.getBytes();
}
@Override
public byte[] doEncode(E event) {
return encode((ILoggingEvent) event);
}
public String convertStackTrace(IThrowableProxy tp){
StringBuilder sb = new StringBuilder(BUILDER_CAPACITY);
recursiveAppend(sb, tp, null);
return sb.toString();
}
private void recursiveAppend(StringBuilder sb, IThrowableProxy tp, String prefix) {
if(tp == null){
return;
}
if (prefix != null) {
sb.append(prefix);
}
sb.append(tp.getClassName()).append(": ").append(tp.getMessage());
sb.append(CoreConstants.LINE_SEPARATOR);
StackTraceElementProxy[] stepArray = tp.getStackTraceElementProxyArray();
boolean unrestrictedPrinting = LENGTH_OPTION > stepArray.length;
int maxIndex = (unrestrictedPrinting) ? stepArray.length : LENGTH_OPTION;
for (int i = 0; i < maxIndex; i++) {
sb.append(TAB);
StackTraceElementProxy element = stepArray[i];
sb.append(element);
sb.append(CoreConstants.LINE_SEPARATOR);
}
IThrowableProxy[] suppressed = tp.getSuppressed();
if (suppressed != null) {
for (IThrowableProxy current : suppressed) {
recursiveAppend(sb, current, SUPPRESSED);
}
}
recursiveAppend(sb, tp.getCause(), CAUSED_BY);
}
}其中recursiveAppend方法是模仿ch.qos.logback.classic.spi.ThrowableProxyUtil,用来答应异常的全部堆栈。
还有这个ip的获取问题,InetAddress.getLocalHost().getHostAddress()解决不了。
以下是详细代码:
public class IpUtil {
public static final String DEFAULT_IP = "127.0.0.1";
public static String cacheLocalIp = null;
private static Logger logger = LoggerFactory.getLogger(IpUtil.class);
/**
* 直接根据第一个网卡地址作为其内网ipv4地址,避免返回 127.0.0.1
*
* @return
*/
private static String getLocalIpByNetworkCard() {
String ip = null;
try {
for (Enumeration<NetworkInterface> e = NetworkInterface.getNetworkInterfaces(); e.hasMoreElements(); ) {
NetworkInterface item = e.nextElement();
for (InterfaceAddress address : item.getInterfaceAddresses()) {
if (item.isLoopback() || !item.isUp()) {
continue;
}
if (address.getAddress() instanceof Inet4Address) {
Inet4Address inet4Address = (Inet4Address) address.getAddress();
ip = inet4Address.getHostAddress();
}
}
}
} catch (Exception e) {
logger.error("getLocalIpByNetworkCard error", e);
try {
ip = InetAddress.getLocalHost().getHostAddress();
} catch (Exception e1) {
logger.error("InetAddress.getLocalHost().getHostAddress() error", e1);
ip = DEFAULT_IP;
}
}
return ip == null ? DEFAULT_IP : ip;
}
public synchronized static String getLocalIP() {
if(cacheLocalIp == null){
cacheLocalIp = getLocalIpByNetworkCard();
return cacheLocalIp;
}else{
return cacheLocalIp;
}
}
}另外在logback-spring.xml中配置了本地日志appender:
<!-- 按照每天生成日志文件 -->
<appender name="filelog" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- rollover daily -->
<fileNamePattern>${LOG_FOLDER}/${springAppName}.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<!-- each file should be at most 100MB, keep 6 days worth of history-->
<maxFileSize>300MB</maxFileSize>
<!--历史文件保留个数-->
<maxHistory>5</maxHistory>
</rollingPolicy>
<encoder>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符-->
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
</encoder>
</appender>注意这里使用SizeAndTimeBasedRollingPolicy而不是使用TimeBasedRollingPolicy+SizeBasedTriggeringPolicy。
后者是按文件大小优先级最高不会自动按日期生成新的log文件。
至此,一个打入kafka日志的代码就算完结了,功能完全,执行正确。
异常场景
思考下,在启动应用或在应用运行时,kafka无法正确接收信息,比如挂掉了。那么这个打日志的功能会怎么表现呢?
当然是每次写日志都会尝试去连kafka,但是失败,必然影响应用状态。
所以想到熔断的思路,假设kafka挂掉,可以通过熔断的方式降低对应用的影响。
这里就实现了一下熔断器的逻辑。
状态流转图:
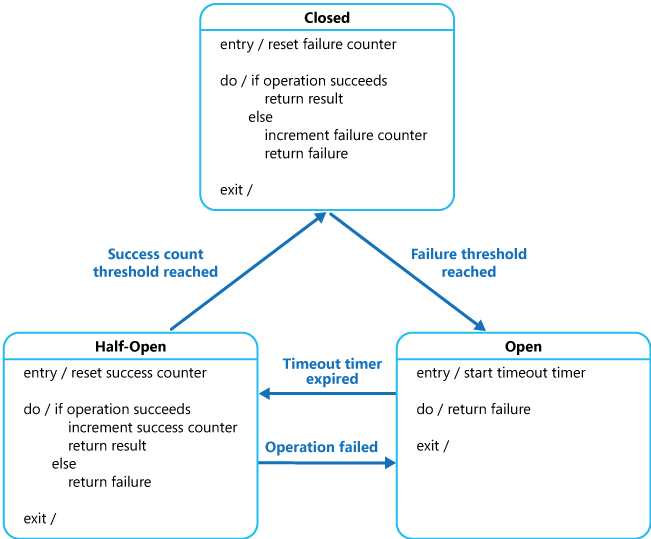
熔断器:
/**
* @desc 熔断器
* 1,使用failureCount和consecutiveSuccessCount控制断路器状态的流转,两者都使用了AtomicInteger以确保并发场数量的精准
* 2,successCount 没有使用AtomicInteger 不确保准确性
* 3,failureThreshold,consecutiveSuccessThreshold,timeout参数非法赋默认值
*/
public class CircuitBreaker {
private static final Logger logger = LoggerFactory.getLogger(CircuitBreaker.class);
private String name;
/**
* 熔断器状态
*/
private CircuitBreakerState state;
/**
* 失败次数阀值
*/
private int failureThreshold;
/**
* 熔断状态时间窗口
*/
private long timeout;
/**
* 失败次数
*/
private AtomicInteger failureCount;
/**
* 成功次数 (并发不准确)
*/
private int successCount;
/**
* 半开时间窗口里连续成功的次数
*/
private AtomicInteger consecutiveSuccessCount;
/**
* 半开时间窗口里连续成功的次数阀值
*/
private int consecutiveSuccessThreshold;
public CircuitBreaker(String name, int failureThreshold, int consecutiveSuccessThreshold, long timeout) {
if(failureThreshold <= 0){
failureThreshold = 1;
}
if(consecutiveSuccessThreshold <= 0){
consecutiveSuccessThreshold = 1;
}
if(timeout <= 0){
timeout = 10000;
}
this.name = name;
this.failureThreshold = failureThreshold;
this.consecutiveSuccessThreshold = consecutiveSuccessThreshold;
this.timeout = timeout;
this.failureCount = new AtomicInteger(0);
this.consecutiveSuccessCount = new AtomicInteger(0);
state = new CloseCircuitBreakerState(this);
}
public void increaseFailureCount(){
failureCount.addAndGet(1);
}
public void increaseSuccessCount(){
successCount++;
}
public void increaseConsecutiveSuccessCount(){
consecutiveSuccessCount.addAndGet(1);
}
public boolean increaseFailureCountAndThresholdReached(){
return failureCount.addAndGet(1) >= failureThreshold;
}
public boolean increaseConsecutiveSuccessCountAndThresholdReached(){
return consecutiveSuccessCount.addAndGet(1) >= consecutiveSuccessThreshold;
}
public boolean isNotOpen(){
return !isOpen();
}
/**
* 熔断开启 关闭保护方法的调用
* @return
*/
public boolean isOpen(){
return state instanceof OpenCircuitBreakerState;
}
/**
* 熔断关闭 保护方法正常执行
* @return
*/
public boolean isClose(){
return state instanceof CloseCircuitBreakerState;
}
/**
* 熔断半开 保护方法允许测试调用
* @return
*/
public boolean isHalfClose(){
return state instanceof HalfOpenCircuitBreakerState;
}
public void transformToCloseState(){
state = new CloseCircuitBreakerState(this);
}
public void transformToHalfOpenState(){
state = new HalfOpenCircuitBreakerState(this);
}
public void transformToOpenState(){
state = new OpenCircuitBreakerState(this);
}
/**
* 重置失败次数
*/
public void resetFailureCount() {
failureCount.set(0);
}
/**
* 重置连续成功次数
*/
public void resetConsecutiveSuccessCount() {
consecutiveSuccessCount.set(0);
}
public long getTimeout() {
return timeout;
}
/**
* 判断是否到达失败阀值
* @return
*/
protected boolean failureThresholdReached() {
return failureCount.get() >= failureThreshold;
}
/**
* 判断连续成功次数是否达到阀值
* @return
*/
protected boolean consecutiveSuccessThresholdReached(){
return consecutiveSuccessCount.get() >= consecutiveSuccessThreshold;
}
/**
* 保护方法失败后操作
*/
public void actFailed(){
state.actFailed();
}
/**
* 保护方法成功后操作
*/
public void actSuccess(){
state.actSuccess();
}
public static interface Executor {
/**
* 任务执行接口
*
*/
void execute();
}
public void execute(Executor executor){
if(!isOpen()){
try{
executor.execute();
this.actSuccess();
}catch (Exception e){
this.actFailed();
logger.error("CircuitBreaker executor error", e);
}
}else{
logger.error("CircuitBreaker named {} is open", this.name);
}
}
public String show(){
Map<String, Object> map = new HashMap<>();
map.put("name:",name);
map.put("state", isClose());
map.put("failureThreshold:",failureThreshold);
map.put("failureCount:",failureCount);
map.put("consecutiveSuccessThreshold:",consecutiveSuccessThreshold);
map.put("consecutiveSuccessCount:",consecutiveSuccessCount);
map.put("successCount:",successCount);
map.put("timeout:",timeout);
map.put("state class",state.getClass());
return JSONObject.toJSONString(map);
}
}状态机:
public interface CircuitBreakerState {
/**
* 保护方法失败后操作
*/
void actFailed();
/**
* 保护方法成功后操作
*/
void actSuccess();
}
public abstract class AbstractCircuitBreakerState implements CircuitBreakerState{
protected CircuitBreaker circuitBreaker;
public AbstractCircuitBreakerState(CircuitBreaker circuitBreaker) {
this.circuitBreaker = circuitBreaker;
}
@Override
public void actFailed() {
circuitBreaker.increaseFailureCount();
}
@Override
public void actSuccess() {
circuitBreaker.increaseSuccessCount();
}
}
public class CloseCircuitBreakerState extends AbstractCircuitBreakerState{
public CloseCircuitBreakerState(CircuitBreaker circuitBreaker) {
super(circuitBreaker);
circuitBreaker.resetFailureCount();
circuitBreaker.resetConsecutiveSuccessCount();
}
@Override
public void actFailed() {
// 进入开启状态
if (circuitBreaker.increaseFailureCountAndThresholdReached()) {
circuitBreaker.transformToOpenState();
}
}
}
public class HalfOpenCircuitBreakerState extends AbstractCircuitBreakerState{
public HalfOpenCircuitBreakerState(CircuitBreaker circuitBreaker) {
super(circuitBreaker);
circuitBreaker.resetConsecutiveSuccessCount();
}
@Override
public void actFailed() {
super.actFailed();
circuitBreaker.transformToOpenState();
}
@Override
public void actSuccess() {
super.actSuccess();
// 达到成功次数的阀值 关闭熔断
if(circuitBreaker.increaseFailureCountAndThresholdReached()){
circuitBreaker.transformToCloseState();
}
}
}
public class OpenCircuitBreakerState extends AbstractCircuitBreakerState{
public OpenCircuitBreakerState(CircuitBreaker circuitBreaker) {
super(circuitBreaker);
final Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
circuitBreaker.transformToHalfOpenState();
timer.cancel();
}
}, circuitBreaker.getTimeout());
}
}
/* @desc 熔断器工厂 集中应用中的CircuitBreaker
* 注意:这里一个熔断器一旦生产,生命周期和应用一样,不会被清除
*/
public class CircuitBreakerFactory {
private static ConcurrentHashMap<String, CircuitBreaker> circuitBreakerMap = new ConcurrentHashMap();
public CircuitBreaker getCircuitBreaker(String name){
CircuitBreaker circuitBreaker = circuitBreakerMap.get(name);
return circuitBreaker;
}
/**
*
* @param name 唯一名称
* @param failureThreshold 失败次数阀值
* @param consecutiveSuccessThreshold 时间窗内成功次数阀值
* @param timeout 时间窗
* 1,close状态时 失败次数>=failureThreshold,进入open状态
* 2,open状态时每隔timeout时间会进入halfOpen状态
* 3,halfOpen状态里需要连续成功次数达到consecutiveSuccessThreshold,
* 即可进入close状态,出现失败则继续进入open状态
* @return
*/
public static CircuitBreaker buildCircuitBreaker(String name, int failureThreshold, int consecutiveSuccessThreshold, long timeout){
CircuitBreaker circuitBreaker = new CircuitBreaker(name, failureThreshold, consecutiveSuccessThreshold, timeout);
circuitBreakerMap.put(name, circuitBreaker);
return circuitBreaker;
}
}发送kafka消息时使用熔断器:
/**
* 因日志为非业务应用核心服务,防止kafka不稳定导致影响应用状态,这里使用使用熔断机制 失败3次开启熔断,每隔20秒半开熔断,连续成功两次关闭熔断。
*/
CircuitBreaker circuitBreaker = CircuitBreakerFactory.buildCircuitBreaker("KafkaAppender-c", 3, 2, 20000);
public <K, V, E> boolean send(Producer<K, V> producer, ProducerRecord<K, V> record, final E event,
final FailedDeliveryCallback<E> failedDeliveryCallback) {
if(circuitBreaker.isNotOpen()){
try {
producer.send(record, (metadata, exception) -> {
if (exception != null) {
circuitBreaker.actFailed();
failedDeliveryCallback.onFailedDelivery(event, exception);
logger.error("kafka producer send log error",exception);
}else{
circuitBreaker.actSuccess();
}
});
return true;
} catch (KafkaException e) {
circuitBreaker.actFailed();
failedDeliveryCallback.onFailedDelivery(event, e);
logger.error("kafka send log error",e);
return false;
}
}else{
logger.error("kafka log circuitBreaker open");
return false;
}
}总结
1,elk搭建时需特别注意各个版本的兼容,kafka client的版本需和kafka版本保持一致
2,方案容许kafka日志失败,而本地日志更加可靠,所以用熔断器方案,以应对万一。也可用于对其他第三方请求时使用。
以上是关于日志打入kafka改造历程-我们到底能走多远系列49的主要内容,如果未能解决你的问题,请参考以下文章