单机爬虫的逻辑以及问题解决
Posted callmegaga
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了单机爬虫的逻辑以及问题解决相关的知识,希望对你有一定的参考价值。
1.1单机爬虫
网络爬虫是指按照一定的规则,自动抓取互联网信息的程序或脚本。其原理很简单,就是获取到一个页面的内容,获取其中所有的下一级URL,然后访问。
单线程的爬虫可以设计成递归的模式。即使,方法的入口是一个URL,方法中对URL对象内容进行解析,操作和存储,同时,在方法中获取子集URL并调用方法本身。
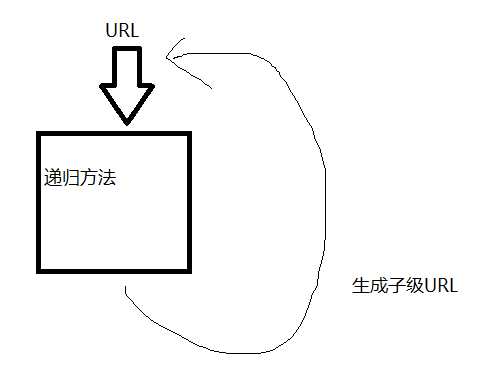
单线程递归的方式比较简单,但其不能充分利用计算机的资源,迭代后期大量URL访问过程在同一条线程内执行,必然也会互相抢夺网络资源,并且过程不可控,多线程并发比较难处理。
可以引入生产者消费者模型的思路,将URL队列储存起来,与访问过程分开来。
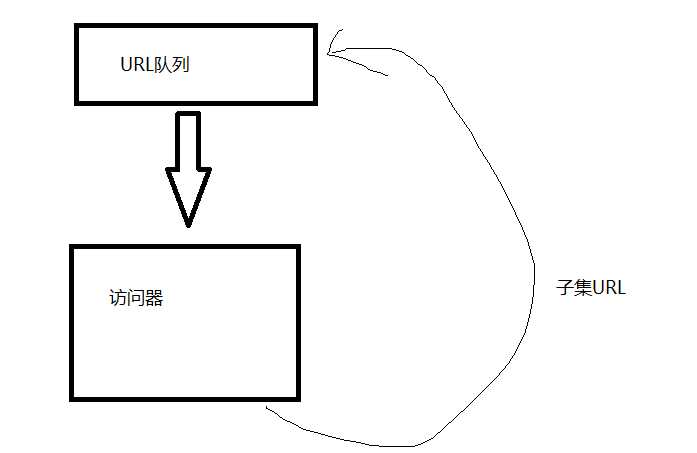
这样,其多线程开发就简单了很多,只要添加多个访问器同时执行就行了。
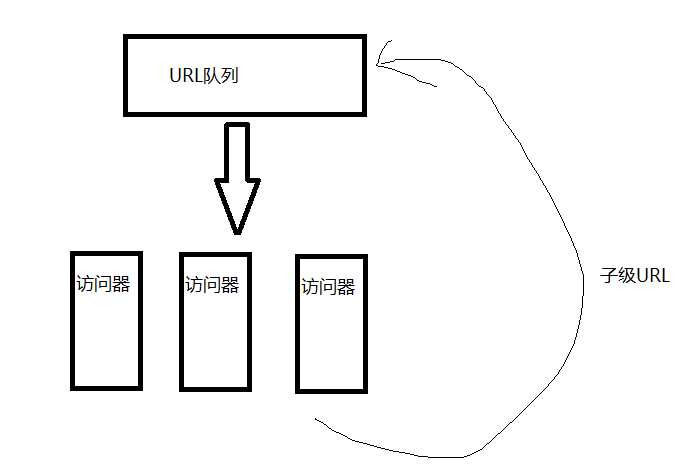
多线程的控制方面,可以加上一个控制器,其可以根据URL队列中的的数据量,控制访问器的新增与减少。
1.2单机爬虫遇到的问题以及解决方式
本次爬取的网站是XXX.XXXXX.XXXXX,其结构与FTP文件夹无异,需求是下载其主目录下所有的文件并保存到本地。网站的数据结构类似树。
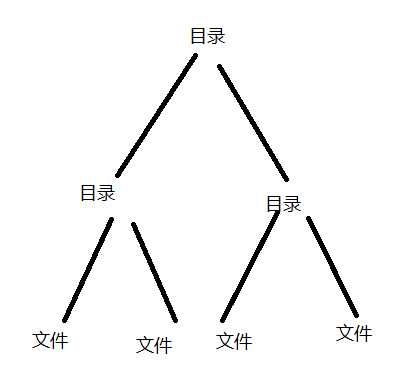
访问到每个URL时,如果是目录,则能从html代码中解析出子级URL,如果URL指向的是文件,则下载过来。
当然我也想直接通过XFTP连接服务器直接下载,但我没有FTP的访问地址,只有HTTP的访问地址。况且,该地址的访问,下载都是限速了的,即使通过FTP,也不能很快的下载完所有内容。
1.2.1网站的用户名密码认证
该网站需要通过用户名和密码访问,才能获取到里面的内容。
解决方式:
在访问代码中添加用户名和密码的认证
private static String getMethod(String url) {
String rb = null;
HttpClient client = new HttpClient();
GetMethod getMethod = new GetMethod(url);
try {
String str = Setting.username + ":" + Setting.password; // 这是能通过认证的用户名和密码
byte[] b = str.getBytes("utf-8");
str = new BASE64Encoder().encode(b); // 使用base64对用户名:密码进行加密
getMethod.setRequestHeader("Authorization", "Basic " + str); // 在请求头添加Authorization字段
// “Basic
// ”这里有个空格
client.executeMethod(getMethod);
rb = getMethod.getResponseBodyAsString();
} catch (Exception e) {
e.printStackTrace();
}
return rb;
}
1.2.2url队列内容过多,内存消耗大的问题
在单机爬虫中,一开始使用一个queue作为url队列,每一条下载线程,在执行下载动作前从队列中获取一条url,解析完之后,将解析完的url加到队列当中。
最早的想法是,要么queue加个size判断,size过大时,暂停一些线程?
但是每一个下载单元的执行过程,如果该url访问的是目录,其必然会生成一大堆子级url目录的。
之后将url队列分为2个,在生成子级URL的时候,先判断一下,如果是目录,则放到一个队列中,如果是文件,则放到另一个队列中。
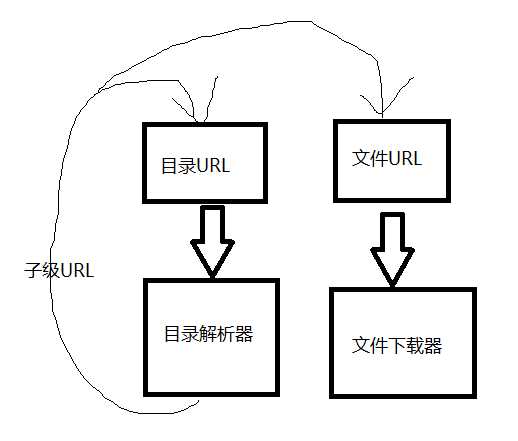
通过文件URL队列的大小来控制目录解析器的执行与暂停。
但这样的话,结构就有些繁琐了,同时需要动态的控制目录解析器和文件下载器的数量,比较麻烦。
之后的想法是用优先级队列,通过子级URL在加入到队列中,做一个判断,如果是文件,就放到队列前面优先执行。
URL如果是目录,执行其会使URL队列的size增加,而如果URL是文件,则执行完,其size会减少,通过文件放前面的形式,一定程度上能缓解url队列过多的问题。
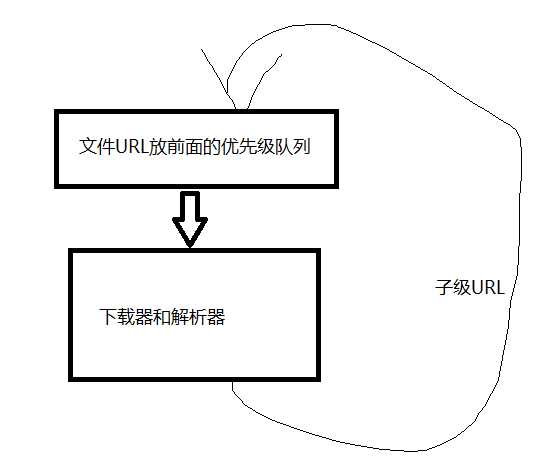
1.2.3下载器和解析器的目标URL识别问题
代码无法通过URL的构成完全判断其是目录还是文件,通过后缀判断有时候会少一些东西,通过地址中的最后一个点的位置去判断,也不能保证不会出错。
因此,URL进入到执行单元时,是应该执行下载操作还是解析操作,就可能存在一定错误执行的概率。
我的解决方式就是,统一执行对目录URL的解析操作,如果返回值为空,则执行下载操作。从而实现下载器和解析器的统一,减少系统的复杂度。
1.2.4url访问或下载的超时终止实现
对于一个url,如果其指向一个文件,而大小又特别大,比如300M,则其执行完会需要很久很久的时间,并且其会消耗大量的缓存,对于这样的操作,应该尽量避免(太大的文件一般是安装包啥的,我只想要里面的文本文件或配置文件)。
则需要实现一个可以定时的线程,其执行一段时间,一段时间内未结束,则强行终止。
我的执行方式比较简单粗暴。
Thread t1;
Thread t2;
private void download(String nextUrl) throws Exception {
t1 = new Thread() {
public void run() {
try {
List<String> lis = Downloader.whyNotDownloadIt(nextUrl);
if (lis.size() > 0) {
DefaultMethod.saveAnUrl(lis);
}
} catch (Exception e) {
saveAnErrorUrl(nextUrl);
}
t2.stop();
}
};
t2 = new Thread() {
public void run() {
try {
Thread.sleep(Setting.max_download_time);
} catch (InterruptedException e) {
e.printStackTrace();
}
t1.stop();
saveAnErrorUrl(nextUrl);
}
};
t1.start();
t2.start();
t1.join();
t2.join();
}
在下载任务开始时,创建两条线程,一条执行任务,一条计时,两条线程在彼此代码的尾部加上终止对方的代码,同时下载器等待2条线程的执行,从而实现定时功能。
以上是关于单机爬虫的逻辑以及问题解决的主要内容,如果未能解决你的问题,请参考以下文章