贝叶斯推断 && 概率编程初探
Posted littlehann
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了贝叶斯推断 && 概率编程初探相关的知识,希望对你有一定的参考价值。
1. 写在之前的话
0x1:贝叶斯推断的思想
我们从一个例子开始我们本文的讨论。小明是一个编程老手,但是依然坚信bug仍有可能在代码中存在。于是,在实现了一段特别难的算法之后,他开始决定先来一个简单的测试用例,这个用例通过了。接着,他用了一个稍微复杂的测试用例,再次通过了。接下来更难的测试用例也通过了,这时,小明开始觉得这段代码出现bug的可能性大大大大降低了....
上面这段白话文中,已经包含了最质朴的贝叶斯思想了!简单来说,贝叶斯推断是通过新得到的证据不断地更新我们的信念。
贝叶斯推断很少会做出绝对的判断,但可以做出非常可信的判断。在上面的例子中,小明永远无法100%肯定代码是无缺陷的,除非他穷举测试了每一种可能出现的情形,这在实践中几乎是不可能的。但是,我们可以对代码进行大量的测试,如果每一次测试都通过了,我们“更”有把握觉得这段代码是没问题的。
贝叶斯推断的工作方式就在这里:我们会随着新的证据不断更新之前的信念,但很少做出绝对的判断,除非所有其他的可能都被一一排除。
0x2:贝叶斯思维和频率派思维的区别
1. 频率派关于概率的解释 - 统计
频率派是更古典的统计学派,它们认为概率是事件在长时间内发生的概率。例如,在频率派的哲学语境里,飞机事故的概率指的是长期来看,飞机事故的概率值。
对许多事件来说,这样解释是有逻辑的。但是对某些没有长期频率的事件来说,这样的解释是难以理解的。例如,在总统选举时,某个候选人的获选的概率是难以用统计的方式来回答的,因为这个候选人的选举可能只发生一次。频率论为了解决这个问题,提出了“替代现实”的说法,从而用在所有这些替代的“现实”中发生的概率定义了这个概率。
2. 贝叶斯派关于概率的解释 - 信息
贝叶斯派对概率有更直观的解释。它把概率解释成是对事件发生的信心。简单地说,概率是观点的概述。
如果某人把概率 0 赋给某个事件的发生,表明他完全确定此事不会发生;相反,如果某人赋的概率值是 1,则表明他十分肯定此事一定会发生。
0 和 1 之间的概率值可以表明此事可能发生的权重。
这个概率定义可以和飞机事故概率一致,如果除去所有外部信息,一个人对飞机事故发生的信心应该等同于他了解到的飞机事故的频率。同样,贝叶斯概率定义也能适用于总统选举,并且使得概率(信心)更加有意义:即你对候选人 A 获胜的信息有多少?
对我们而言,将对一个事件发生的信息等同于概率是十分自然的,这正是我们长期以来同世界打交道的方式。我们只能了解到部分的真相,但可以通过不断收集证据来完善我们对事物的观念。
3. 贝叶斯推断的先验概率和后验概率
1)先验概率
对于统计学派来说,在进行统计之前,我们对概率是一无所知的。对于统计学派和统计方法来说,所有的概率都必须在完成统计之后(包括最大似然估计)才能得到一个统计概率。
但是对于贝叶斯推断来说,在进行统计之前,我们对事物已经拥有了一个先验的判断,即先验概率,记为 P(A)。
例如:P(A):硬币有50%的概率是正面;P(A):一段很长的很复杂的代码可能含有bug
2)后验概率
我们用 P(A|X) 表示更新后的信念,其含义为在得到证据 X 后,A 事件的概率。考虑下面的例子:
P(A|X):我们观察到硬币落地后是正面,那么硬币是正面的后验概率会比50%大;
P(A|X):代码通过了所有的 X 个测试,现在代码可能仍然有bug,但是现在这个概率变得非常小了。
3)贝叶斯推断柔和地融合了我们对事物的先验领域知识以及实际的观察样本的统计结果
在上述的例子中,即便获得了新的证据,我们也并没有完全地放弃初始的信念,但是我们重新调整了信念使之符合目前的证据(训练样本),也就是说,证据让我们对某些结果更有信息。
通过引入先验的不确定性,我们事实上允许了我们的初始信念可能是错误的。在观察数据、证据或其他信息之后,我们不断更新我们的信念使得它错得不那么离谱
0x3:在大数据情况下统计思想和贝叶斯推断思想是相等的?
频率推断和贝叶斯推断都是一种编程函数,输入的是各种统计问题。频率推断返回的是一个统计值(通常是统计量,平均值是一个典型的例子),而贝叶斯推断则会返回一个概率值。
这个小节我们来讨论下,当样本数量 N 不断增大时,频率推断和贝叶斯推断会发生什么。
1. 频率推断:N越大,频率统计越接近真实概率
频率统计学派假设世界上存在一个真理,即概率。统计做的事只是通过大量的实验来揭示这个真理本身而已。当 N 趋于无穷时,频率统计得到的统计值会无限接近于概率本身,即规律本身。
2. 贝叶斯推断:N越大,先验的离谱程度会不断降低,即越靠近真实的规律本身
当我们增加 N 时,即增加更多的证据时,初始的信念会不断地被“洗刷”。这是符合期望的。例如如果你的先验是非常荒谬的信念类似“太阳今天会爆炸”,那么每一天的结果都会不断“洗刷”这个荒谬的先验,使得后验概率不断下降。
3. N趋于无穷大时,频率推断和贝叶斯推断趋近相等
让 N 表示我们拥有的证据的数量。如果 N 趋于无穷大,那么贝叶斯的结果通常和频率派的结果一致。
因此,对于足够大的 N,统计推断多多少少还是比较客观的。
另一方面,对于较小的 N,统计推断相对而言不太稳定,频率统计的结果有更大的方差和置信区间。所以才会有相关性检验、卡方检验、皮森相关系数这些评价算法。
贝叶斯推断在小数据这方面效果要更好,通过引入先验概率和返回概率结果(而不是某个固定的值),贝叶斯推断保留了不确定性,这种不确定性正式小数据集的不稳定性的反映。
4. 频率统计仍然是十分有用的!
虽然频率统计的有更大的方差和置信区间,在小数据集下表现也不一定稳定。但是频率统计仍然非常有用,在很多领域可能都是最好的办法。例如最小方差线性回归、LASSO回归、EM算法,这些都是非常有效和快速的方法。
贝叶斯方法能够在这些方法失效的场景发挥作用,或者是作为更有弹性的模型而补充。
0x4:贝叶斯推断和极大似然估计、SGD随机梯度下降是什么关系?
贝叶斯推断和极大似然估计、SGD随机梯度下降一样,都是一种求解算法模型超参数(模型分布)的方法。
贝叶斯推断更侧重于先验和证据的动态融合,得到极大后验概率估计;
极大似然估计更侧重于对训练样本的频率统计;
而SGD在各种场景下都能表现出较好的性能,通过反向梯度的思想,不断进行局部最优的求解,从而获取近似的全局最优解。
2. 贝叶斯框架
我们知道,对于我们感兴趣的估计,可以通过贝叶斯思想被解释为概率。在频率统计中,这个估计时通过统计得到的,而在贝叶斯估计中,估计时通过后验概率得到的。
我们已经从抽象概念上了解了何谓后验概率,后验概率即为:新证据对初始信念洗刷后的结果,即修正后的信念。这个概念怎么落实到数学计算上呢?
0x1:贝叶斯定理
我们需要一个方法能够将几个因素连接起来,即先验概率、我们的证据、后验概率。这个方法就是贝叶斯定理,得名于它的创立者托马斯.贝叶斯。
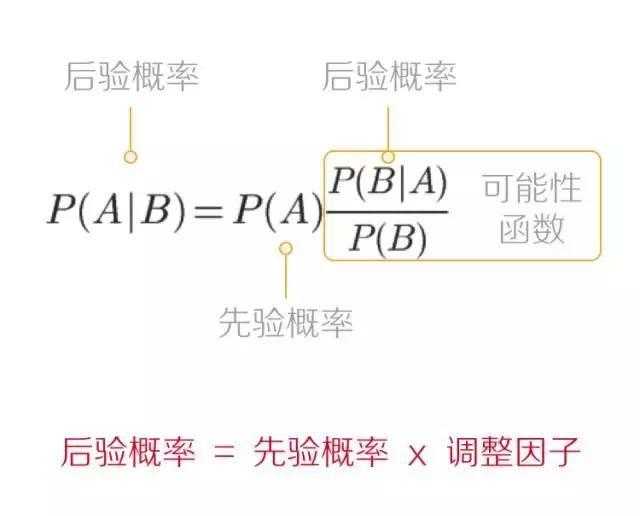
上面的公式并不等同于贝叶斯推断,它是一个存在于贝叶斯推断之外的数学真理。或者应该说贝叶斯推断是在贝叶斯定理的基石上建立起来的。
在贝叶斯推断里,贝叶斯定理公式仅仅被用来连接先验概率 P(A) 和更新后的后验概率 P(A|B)
0x2:一个贝叶斯推断的例子 - 图书管理员还是农民
斯蒂文是一个害羞的人,他乐于助人,但是他对其他人不太关注。他非常乐见事情处于合理的顺序,并对他的工作非常细心。从特征工程的角度来看,似乎我们更应该判定史蒂文为已个图书管理员。
但是这里忽略了一个非常重要的先验知识,即男性图书管理员的人数只有男性农民的 1/20,这个先验知识将极大改变史蒂文是否是图书管理员这个事件的后验概率。
1. 形式化定义这个问题
把问题简化,假设世上只有两种职业,图书管理员和农民,并且农民的数量确实是图书管理员的20倍。
设事件 A 为史蒂文是一个图书管理员。如果我们没有史蒂文的任何信息,那么 P(A) = 1/21。这是我们的先验。
我们假设从史蒂文的邻居们那里我们获得了关于他的一些信息,我们称它们为 X,我们想知道的就是 P(A|X)。由贝叶斯定理得:P(A|X) = P(X|A) * P(A) / P(X)。
P(X|A)被定义为在史蒂文真的是一个图书管理员的情况下,史蒂文的邻居们给出的某种描述的概率,即如果史蒂文真的是一个图书管理员,他的邻居们将他描述为一个图书管理员的概率。这个值很可能接近于1,假设它为 0.95。
P(X) 可以解释为:任何人史蒂文的描述和史蒂文邻居的描述一致的概率,我们将其做逻辑上的改造:
P(X) = P(X and A) + P(X and ~A) = P(X|A)P(A) + P(X|~A)P(~A)
P(X|A)P(A) 这两个值我们都已经知道了。另外,~A 表示史蒂文不是一个图书管理员的概率,那么他一定是一个农民。所以 P(~A) = 1 - P(A) = 20 / 21。
P(X|~A) 即在史蒂文是一个农名的情况下,史蒂文的邻居给出的某个描述的概率,我们假设其为 0.5。
综上,P(X) = 0.95 * 1/24 + 0.5 * 20/21 = 0.515773809524
带入贝叶斯定理公式,P(A|X) = 0.95 * 1/20 / 0.515773809524 = 0.0877091748413
可以看到,因为农民数量远大于图书管理员,所以后验概率并不算高,尽管我们看到 P(X|A)的概率要大于 P(X|~A),即我们得到的特征描述更倾向于表明史蒂文是一个图书管理员。
这个例子非常好的阐述了,先验概率以及证据时如何动态影响最终的后验概率结果的。
2. 通过可视化的代码呈现该问题
# -*- coding: utf-8 -*- import numpy as np from matplotlib import pyplot as plt plt.rcParams[‘savefig.dpi‘] = 300 plt.rcParams[‘figure.dpi‘] = 300 colours = ["#348ABD", "#A60628"] prior = [1/20., 20/21.] # 图书管理员和农民的先验概率分别是 1/20 和 20/21 posterior = [0.087, 1-0.087] # 后验概率 plt.bar([0, .7], prior, alpha=0.70, width=0.25, color=colours[0], label="prior distribution", lw="3", edgecolor=colours[0]) plt.bar([0 + 0.25, .7 + 0.25], posterior, alpha=0.7, width=0.25, color=colours[1], label="posterior distribution", lw="3", edgecolor=colours[1]) plt.ylim(0, 1) plt.xticks([0.20, 0.95], [‘Librarian‘, ‘Farmer‘]) plt.title("Prior and Posterior probability of Steve‘s occupation") plt.ylabel("Probability") plt.legend(loc="upper left") plt.show()
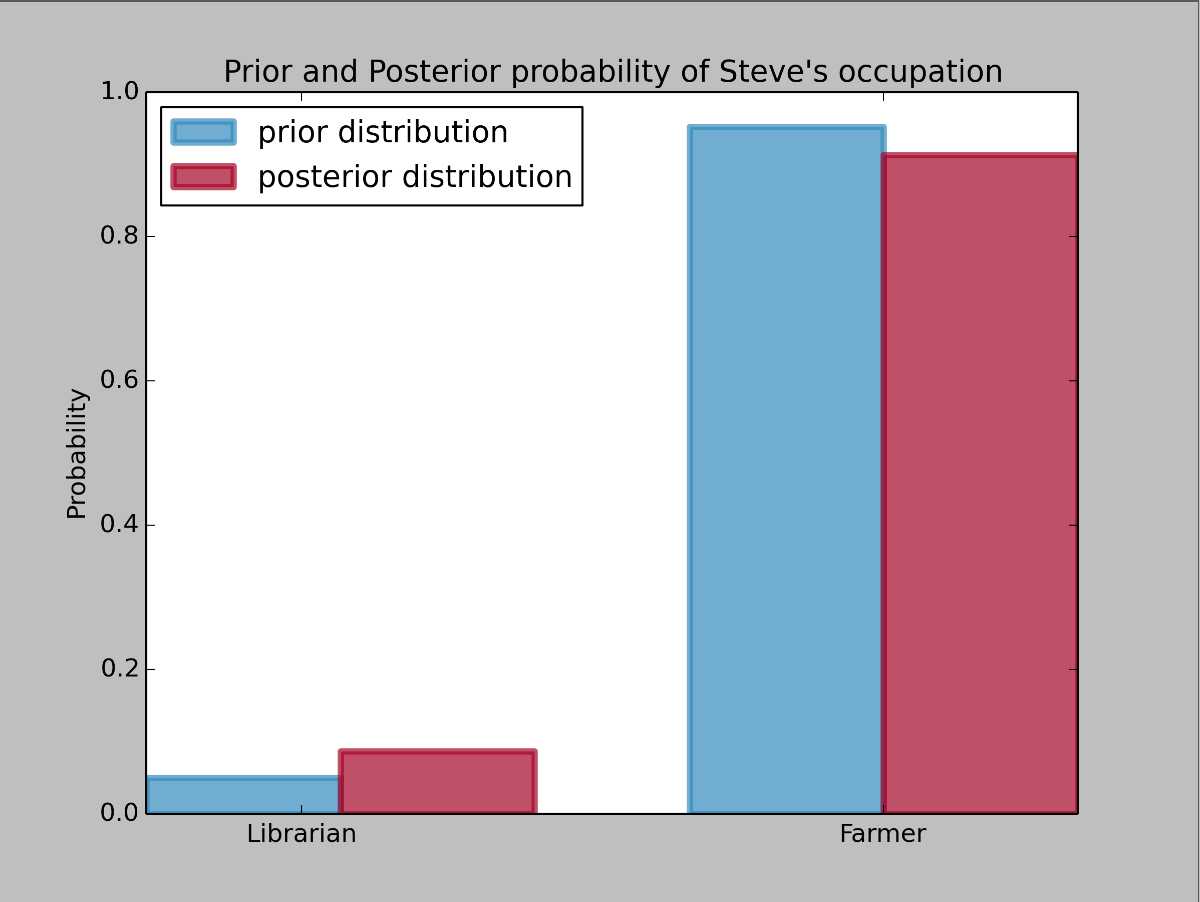
可以看到,在得到 X 的观测值之后,史蒂文为图书管理员的后台概率增加了。同时,农民的后验概率降低了。
但同时也看到,史蒂文为图书管理员的后验概率增加的并不是很多,史蒂文是农民的可能性依旧很大。
这表明,先验概率对贝叶斯推断影响是很大的,例如我们假设一台服务器平时不会被黑客攻陷(IOC),但是如果观测到一系列的异常事件,被攻陷的后验概率就会不断增大,但这取决于观测到的现象的数量和强度。
3. 一个从短信数据推断行为模式的例子 - 使用计算机执行贝叶斯推断
0x1:场景描述 - 我们的数据是什么样的?
下面的直方图显示了一段时间内的短信数量的统计。
# -*- coding: utf-8 -*- import numpy as np from matplotlib import pyplot as plt count_data = np.loadtxt("data/txtdata.csv") n_count_data = len(count_data) plt.bar(np.arange(n_count_data), count_data, color="#348ABD") plt.xlabel("Time (days)") plt.ylabel("count of text-msgs received") plt.title("Did the user‘s texting habits change over time?") plt.xlim(0, n_count_data) plt.show()
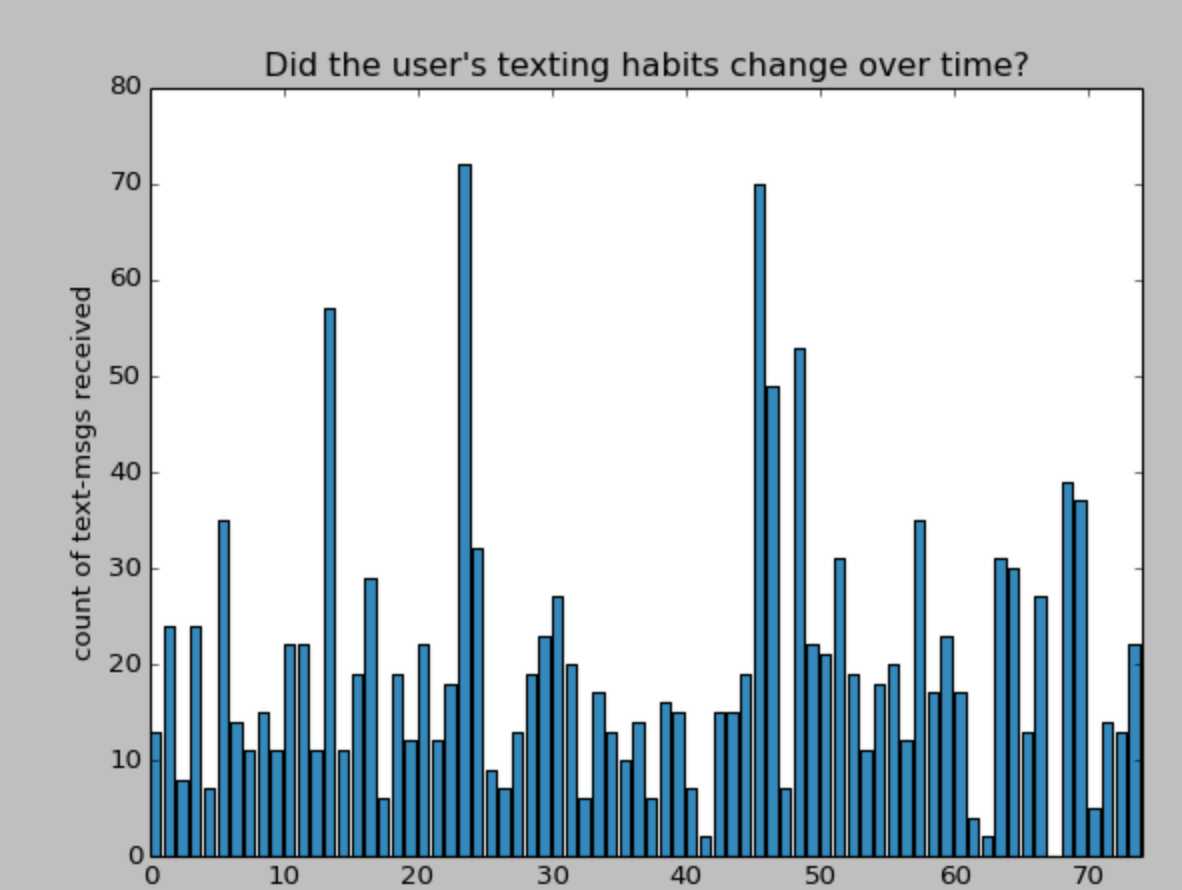
数据集下载链接。
0x2:问题定义 - 我们要从数据中挖掘出什么东西?
我们的问题是:这段时间内用户的行为出现了什么变化吗?或者是说,这段时间内是否出现了异常的行为模式,又具体是几号发生的?
这特别像安全攻防领域经常面对的一个问题,即在一段日志中进行数据挖掘,从中找出是否存在异常行为模式(即入侵IOC)。
通常来说,一个直观的想法可能会是这样,我们通过ngram或者定长的时间窗口进行日志聚合,然后通过人工经验聚合中抽取一系列的特征,并希望借助有监督或者无监督的方法直接得到一个 0/1 判断,即这个窗口期间内是否存在异常点。这是一种典型的端到端判断场景。
但是其实我觉得应该更灵活地理解算法,不一定每一个场景都适合使用判别式模型进行二分或者多分判断,有时候,我们其实可以尝试使用生成式模型,基于训练数据,得到一个或多个概率分布生成式。而多个生成式模型之间的分界点,很可能就是代表了一种模式跃迁,即行为异常。
0x3:使用什么生成式模型进行数据拟合?
1. 二项分布?正态分布?泊松分布?
二项分布,正态分布,泊松分布这3个都是对自然界的事物在一定时间内的发生次数进行泛化模拟的分布模型。实际上,它们3个之间相差并不是很大。
如果忽略分布是离散还是连续的前提(二项分布和泊松分布一样都是离散型概率分布,正态分布是连续型概率分布),二项分布与泊松分布以及正态分布至少在形状上是十分接近的,也即两边低中部高。
当 n 足够大,p 足够小(事件间彼此独立,事件发生的概率不算太大,事件发生的概率是稳定的),二项分布逼近泊松分布,λ=np;
一个被广泛接受的经验法则是如果 n≥20,p≤0.05,可以用泊松分布来估计二项分布值。
至于正态分布是一个连续分布 当实验次数 n 再变大,几乎可以看成连续时二项分布和泊松分布都可以用正态分布来代替。
2. 单位时间内随机事件发生的次数趋近于一个相对固定值 - 选泊松分布
在日常生活中,大量事件我们可以预见其在时间窗口内的总数,但是无法准确知道具体某个时刻发生的次数。例如
1. 某医院平均每小时出生3个婴儿; 2. 某公司平均每10分钟接到1个电话; 3. 某超市平均每天销售4包 xx 牌奶粉; 4. 某网站平均每分钟有2次访问;
这些事件的特点就是,我们可以预估这些事件的总数,但是没法具体知道发生时间。例如医院具体下一小时的前10分钟出现几个婴儿,有可能前10分钟出现1个,也可能一下子出生3个。
泊松分布就是描述某段时间内,事件具体的发生概率。
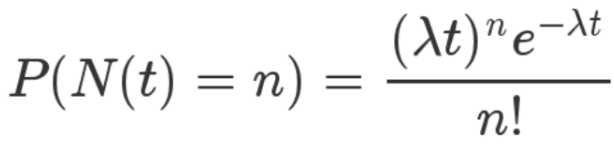
P 表示概率,N 表示某种函数关系,t 表示时间,n 表示数量,λ 表示事件的频率。
从公式上看,我们得到几个泊松分布的基本判断:
1. 单位时间内发生 n 次数的概率随着时间 t 变化;
2. 概率受发生次数 n 的影响;
3. λ 相当于这件事的先验属性,在整个时间周期内都影响了最终的概率,λ 被称为此分布的一个超参数,它决定了这个分布的形式。
λ 可以位任意正数,随着 λ 的增加,得到大值的概率会增大。相反地,当 λ 减小时,得到小值的概率会增大。λ 可以被称为 Poisson分布的强度。
接下来两个小时,一个婴儿都不出现的概率是(已知 λ = 3):
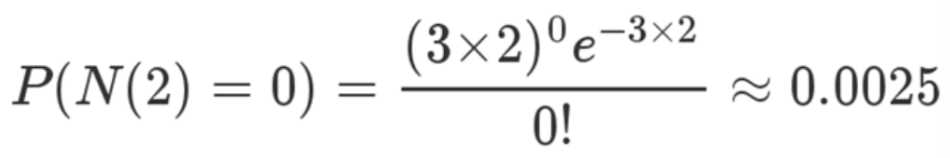
基本不可能发生。
接下来一个小时,至少出现两个婴儿的概率是:
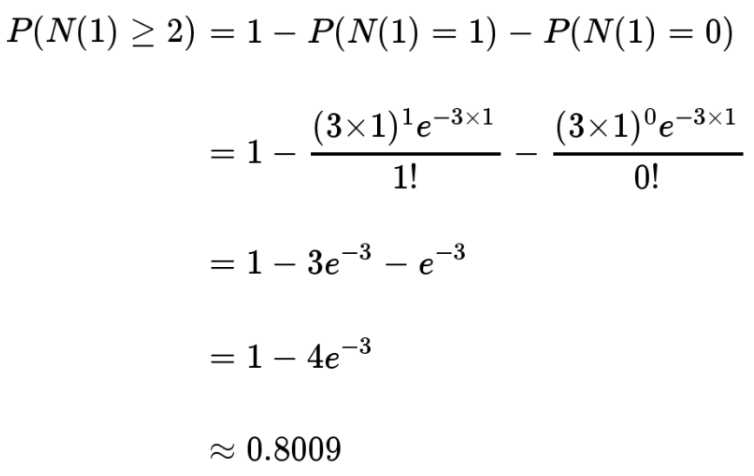
即 80%。
泊松分布的图像大概是这样的:
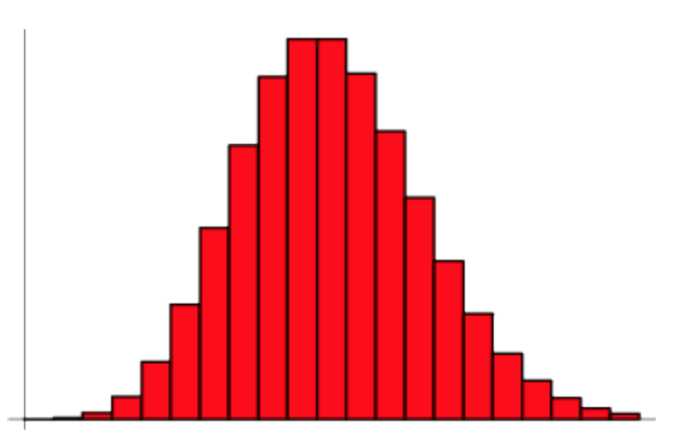
可以看到,在频率附近,事件发生的概率最高,然后向两边对称下降。每小时出生 3 个婴儿,这是最可能的结果,出生得越多或越少,就越不可能。
Poisson分布的一个重要性质是:它的期望值等于它的参数。即:E[Z|λ] = λ。
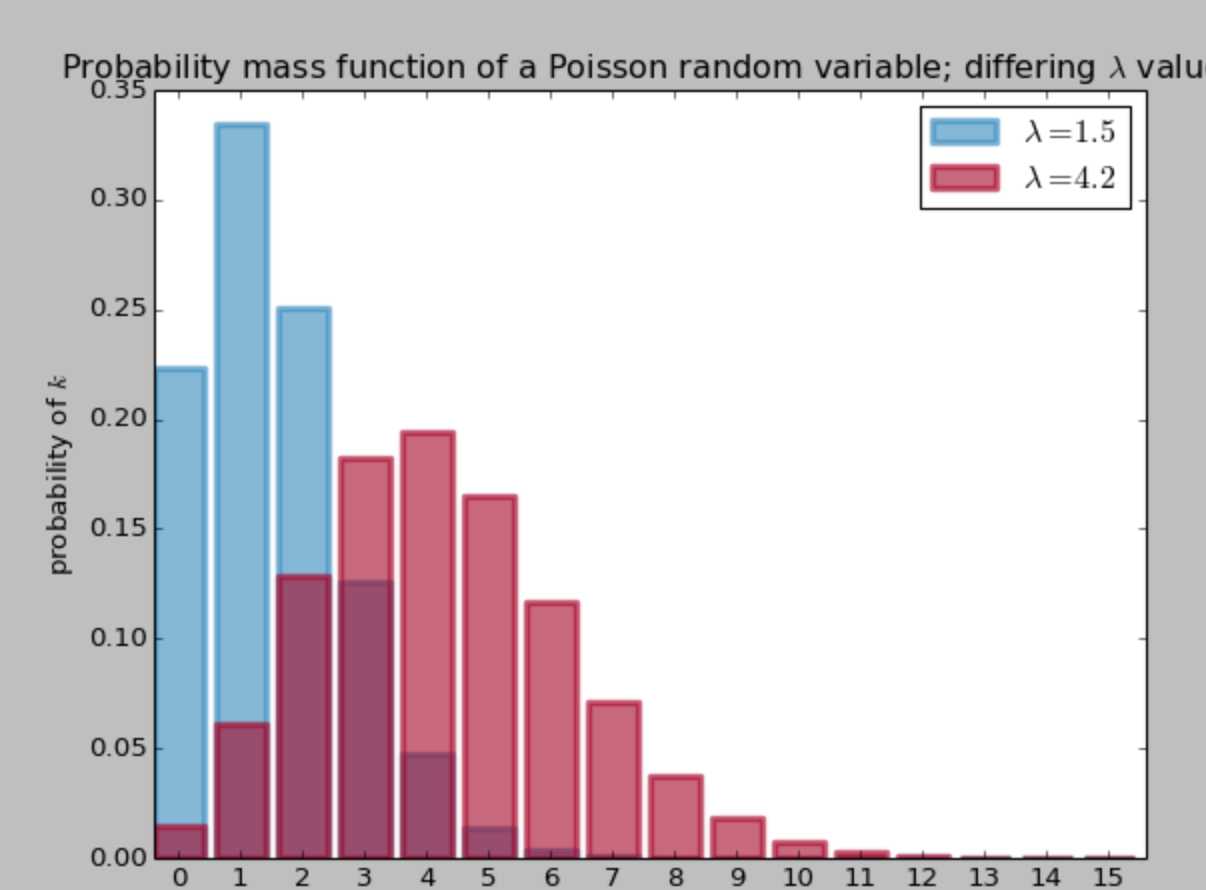
下图展示了不同 λ 取值下的概率质量分布,可以看到,随着 λ 的增加,取到大值的概率会增加。
# -*- coding: utf-8 -*- import numpy as np from matplotlib import pyplot as plt import scipy.stats as stats a = np.arange(16) poi = stats.poisson lambda_ = [1.5, 4.25] colours = ["#348ABD", "#A60628"] plt.bar(a, poi.pmf(a, lambda_[0]), color=colours[0], label="$lambda = %.1f$" % lambda_[0], alpha=0.60, edgecolor=colours[0], lw="3") plt.bar(a, poi.pmf(a, lambda_[1]), color=colours[1], label="$lambda = %.1f$" % lambda_[1], alpha=0.60, edgecolor=colours[1], lw="3") plt.xticks(a + 0.4, a) plt.legend() plt.ylabel("probability of $k$") plt.xlabel("$k$") plt.title("Probability mass function of a Poisson random variable; differing $lambda$ values") plt.show()
3. 用单个泊松分布就足够拟合数据集了吗?
好!我们现在已经确定要使用泊松分布来对数据集进行拟合。接下来的问题是,我们是不是只要用单个泊松分布就足够对这份数据集进行完美拟合了呢?
我们再来看看我们的问题场景。
我们这里通过观察数据,我们认为在某个时间段,发生了一个行为模式的突变,即在后期,收到短信的频率好像提高了。
实际上,这已经进入到异常检测的范畴内了,我们可以基于泊松分布混合模型对这个数据集进行拟合。
4. 怎么形式化描述泊松分布参数 λ 的阶跃情况?
我们不能确定参数 λ 的真实取值,但是可以猜测在某个时段 λ 增加了(λ取大值时,更容易得到较大的结果值),也即一天收到的短信条数比较多的概率增大了。
我们怎么形式化地描述这个现象呢?假设在某一个时间段内(用τ表示)(τ可能也无法准确定义到具体的某一天),参数??突然变大。
所以??可以取两个值,在时段τ之前有一个,在τ时段之后有另一个。这种突然发生变化的情况称之为转换点。
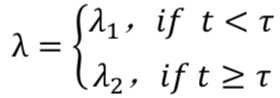
我们以贝叶斯推断的思想来看待这个问题:
1. 首先,存在一个 λ 阶跃点只是一个先验假设。事实上,可能并不存在这样一个 λ 阶跃点。 2. 第二,具体的阶跃点 τ 是什么时间呢?可能我们无法准确知道时间点,只能得到一个时间区间的概率分布。
1)确定泊松分布参数 λ 的先验分布
如果实际中 λ 没有变化,则 ![]() ,那么 λ 的先验概率是相等的。
,那么 λ 的先验概率是相等的。
在贝叶斯推断下,我们需要对不同可能取值的 λ 分配相应的先验概率。那具体什么样的先验概率对![]() 来说才是最有可能的呢?
来说才是最有可能的呢?
严格来说,我们对这件事几乎没有任何先验知识,因为我们可能对这个数据集的属主用户行为模式一无所知。
注意到 λ 可以取任意正数,所以我们可以用指数分布来表示 λ 的先验分布,因为指数分布对任意正数都存在一个连续密度函数,这对模拟 λ 来说是一个很好的选择。但是,指数分布本身也有它自己的参数,所以这个参数也需要包括在我们的模型公式里面。我们称它为 α。不同的 α 决定了该指数分布的形状。
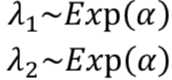
α 称之为超参数。该参数能够影响其他参数。按照最大熵算法的原理,我们不希望对这个参数赋予太多的主观色彩。
注意到我们计算样本中计算平均值的公式:![]() ,它正好就是我们要估计的超参数 α 的逆,所以,超参数 α 可以直接根据观测样本的计算得到。
,它正好就是我们要估计的超参数 α 的逆,所以,超参数 α 可以直接根据观测样本的计算得到。
2)确定阶跃点 τ 的先验分布
我们对于参数τ,由于受到噪声数据的影响,很难为它选择合适的先验。所以还是依照最大熵原理,我们假定每一天的先验估计都是一致的。即:
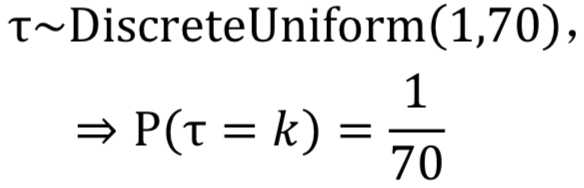
在不知道任何先验知识的情况下,等概论被证明是一种最好的先验假设。
0x4:使用PyMC进行贝叶斯推断
Cronin对概率编程有一段激动人心的描述:
换一种方式考虑这件事件,跟传统的编程仅仅向前运行不同的是,概率编程既可以向前也可以向后运行。它通过向前运行来计算其中包含的所有关于世界的假设结果(例如对模型空间的描述),但它也从数据中向后运行,以约束可能的解释。
在实践中,许多概率编程系统将这些向前和向后的操作巧妙地交织在一起,以给出有效的最佳解释。
1. 声明模型中的随机变量
按照前面我们的讨论,α 取样本中计算平均值的逆,而泊松分布的的参数 λ 由 α决定。对阶跃点先验估计的 τ 参数,使用等概率估计(最大熵原理)。
# -*- coding: utf-8 -*- import numpy as np from matplotlib import pyplot as plt import pymc as pm count_data = np.loadtxt("data/txtdata.csv") n_count_data = len(count_data) plt.bar(np.arange(n_count_data), count_data, color="#348ABD") plt.xlabel("Time (days)") plt.ylabel("count of text-msgs received") plt.title("Did the user‘s texting habits change over time?") plt.xlim(0, n_count_data) alpha = 1.0 / count_data.mean() # Recall count_data is the # variable that holds our txt counts lambda_1 = pm.Exponential("lambda_1", alpha) lambda_2 = pm.Exponential("lambda_2", alpha) tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data) print("Random output:", tau.random(), tau.random(), tau.random())
代码输出的结果为:(‘tau Random output:‘, array(36), array(57), array(38))
表明我们的阶跃点 τ 参数是等概率随机生成的。
参数 λ 受参数 τ 影响,所以在阶跃点两边的不同的泊松分布参数 λ 也是随机的,它根据 τ 随机生成。
我们希望PyMC收集所有变量信息,以及观测数据,并从中产生一个model。PyMC可以借助一个叫马尔科夫链蒙特卡洛(MCMC)的算法。得到参数 λ1,λ2,τ 的后验估计
2. 利用MCMC根据观测数据得到对模型参数的极大后验估计结果
# -*- coding: utf-8 -*- import numpy as np from matplotlib import pyplot as plt import pymc as pm count_data = np.loadtxt("data/txtdata.csv") n_count_data = len(count_data) plt.bar(np.arange(n_count_data), count_data, color="#348ABD") plt.xlabel("Time (days)") plt.ylabel("count of text-msgs received") plt.title("Did the user‘s texting habits change over time?") plt.xlim(0, n_count_data) alpha = 1.0 / count_data.mean() # Recall count_data is the # variable that holds our txt counts lambda_1 = pm.Exponential("lambda_1", alpha) lambda_2 = pm.Exponential("lambda_2", alpha) tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data) @pm.deterministic def lambda_(tau=tau, lambda_1=lambda_1, lambda_2=lambda_2): out = np.zeros(n_count_data) out[:tau] = lambda_1 # lambda before tau is lambda1 out[tau:] = lambda_2 # lambda after (and including) tau is lambda2 return out print("tau Random output:", tau.random(), tau.random(), tau.random()) #print("lambda distribution:", lambda_(tau, lambda_1, lambda_2)) observation = pm.Poisson("obs", lambda_, value=count_data, observed=True) model = pm.Model([observation, lambda_1, lambda_2, tau]) mcmc = pm.MCMC(model) mcmc.sample(40000, 10000, 1) lambda_1_samples = mcmc.trace(‘lambda_1‘)[:] lambda_2_samples = mcmc.trace(‘lambda_2‘)[:] tau_samples = mcmc.trace(‘tau‘)[:] # histogram of the samples: ax = plt.subplot(311) ax.set_autoscaley_on(False) plt.hist(lambda_1_samples, histtype=‘stepfilled‘, bins=30, alpha=0.85, label="posterior of $lambda_1$", color="#A60628", normed=True) plt.legend(loc="upper left") plt.title(r"""Posterior distributions of the variables $lambda_1,;lambda_2,; au$""") plt.xlim([15, 30]) plt.xlabel("$lambda_1$ value") ax = plt.subplot(312) ax.set_autoscaley_on(False) plt.hist(lambda_2_samples, histtype=‘stepfilled‘, bins=30, alpha=0.85, label="posterior of $lambda_2$", color="#7A68A6", normed=True) plt.legend(loc="upper left") plt.xlim([15, 30]) plt.xlabel("$lambda_2$ value") plt.subplot(313) w = 1.0 / tau_samples.shape[0] * np.ones_like(tau_samples) plt.hist(tau_samples, bins=n_count_data, alpha=1, label=r"posterior of $ au$", color="#467821", weights=w, rwidth=2.) plt.xticks(np.arange(n_count_data)) plt.legend(loc="upper left") plt.ylim([0, .75]) plt.xlim([35, len(count_data) - 20]) plt.xlabel(r"$ au$ (in days)") plt.ylabel("probability") plt.show()
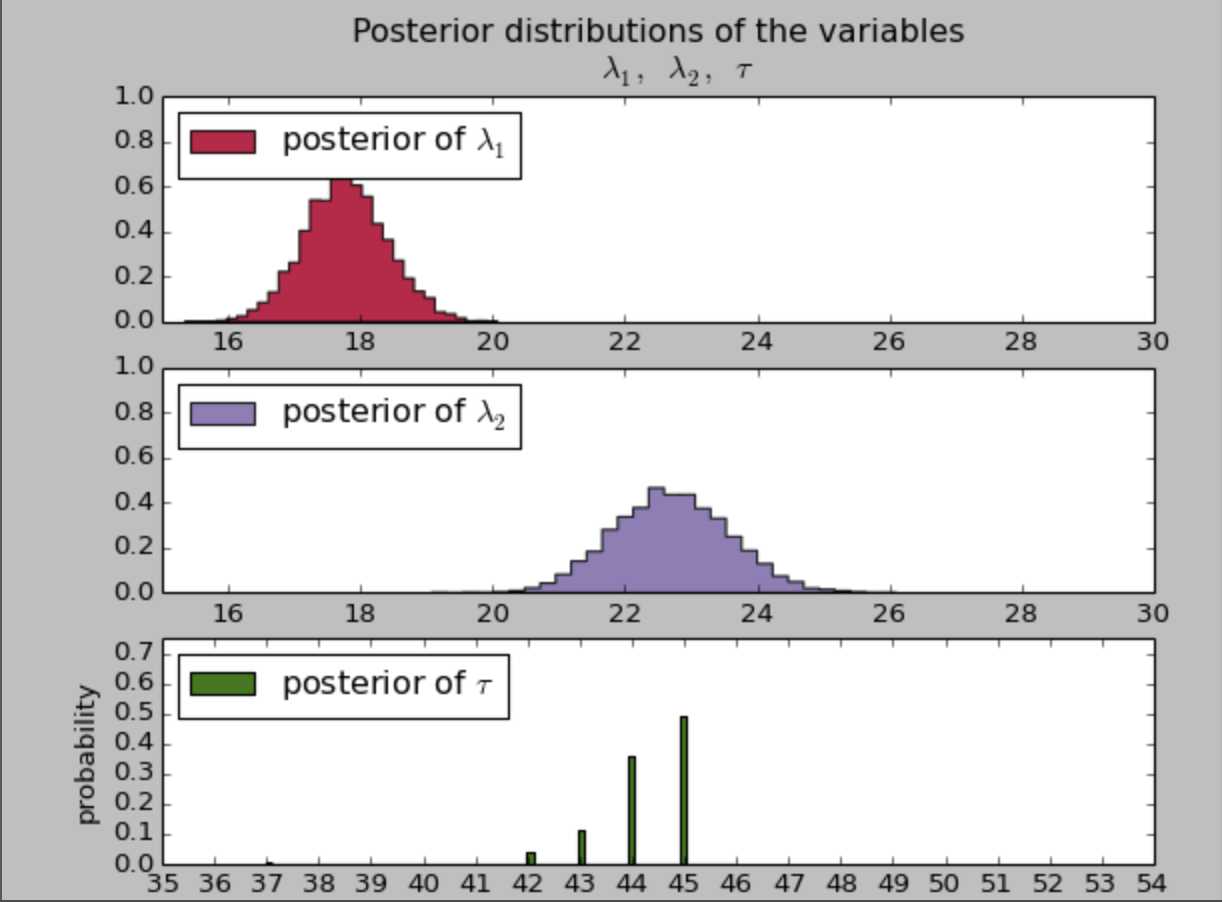
0x5:得到的模型参数后验分布结果说明了什么?
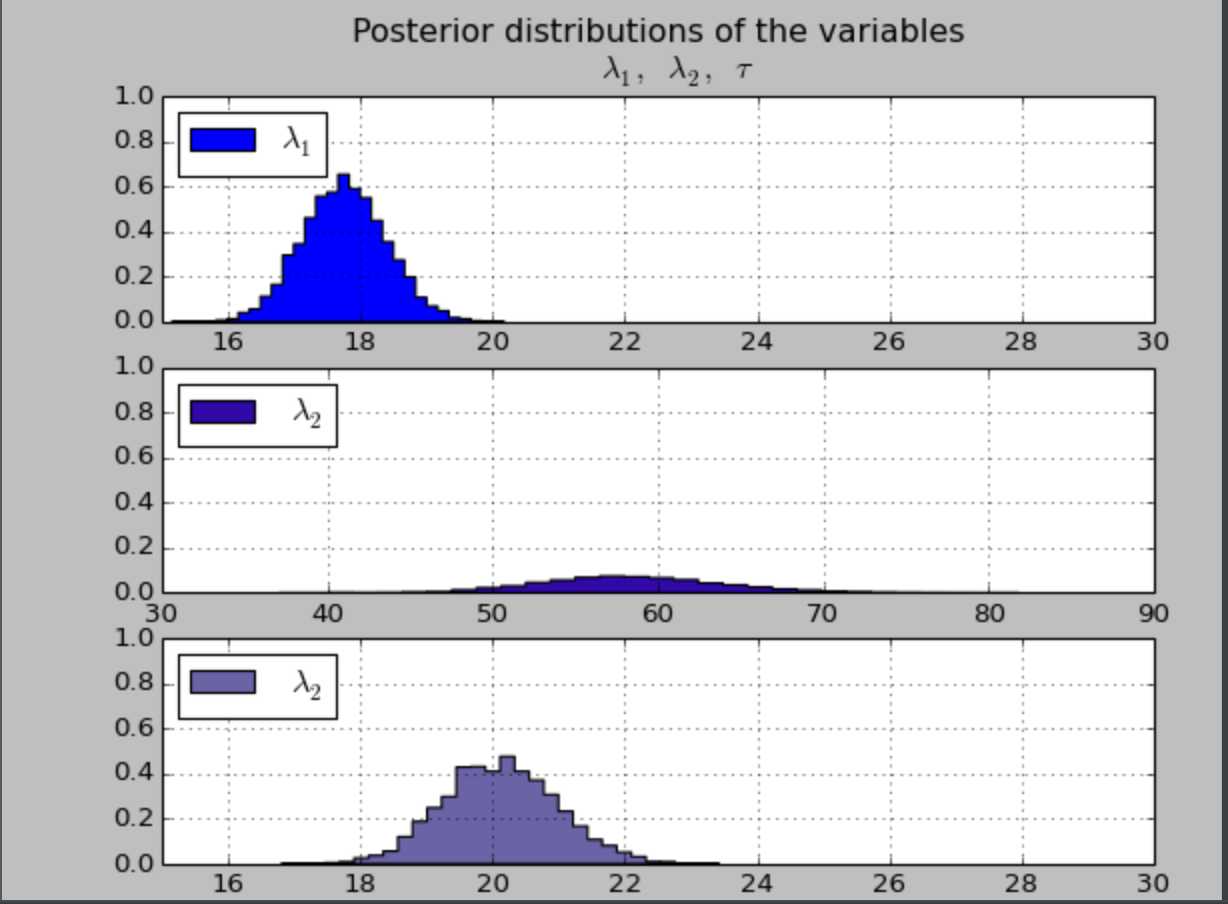
首先,我们可以看到,贝叶斯推断得到的是一个概率分布,不是一个准确的结果。我们使用分布描述位置的 λ 和 τ。
分布越广,我们的后验概率越小
1. 有很大概率存在异常行为模式的突变
我们也可以看到参数的合理值:λ1 大概是18,λ2 大概是23。这两个 λ 的后验分布明显是不同的,这表明该用户接受短信的行为确实发生了变化。
2. 后验分布是我们假设的指数分布吗?
我们还注意到,λ 的后验分布并不是我们在模型建立时假设的指数分布,事实上,λ 的后验分布并不是我们能从原始模型中可以辨别的任何分布。
但是这恰恰就是概率编程的好处所在,我们借助计算机绕开了复杂的数学建模过程。
3. 阶跃点时间点
我们的分析结果返回了一个 τ 的一个概率分布。在很多天中,τ 不太好确定,总体来说,我们可以认为在3~4天内可以认为是潜在的阶跃点。
我们可以看到,在45天左右,有50%的把握可以说用户的行为是有所改变的。这个点的概率分布突然出现了一个峰值,我们可以推测产生这种情况的原因是:短信费用的降低,天气提醒短信的订阅,或者是一段感情的开始。
0x6:根据模型参数得到后验样本
在开始讨论后验样本之前。首先需要明白的是,模型的后验样本并不是真实存在的事实,它更多地像是我们基于已经得到的概率分布得到的一个期望值。因为很显然,我们的模型不能很好地表达出真实物理中的随机分布以及噪音的影响。我们能得到的只能是一个对整体情况的概括。
我们用后验样本来回答一下下面这个问题:
在第 t (0 <= t <= 70)天中,期望收到多少条短信?
显然,这个问题要求我们给出一个概括统计,即求每天短信数量的期望。
Poisson分布的期望值等于它的参数 λ。因此,问题相当于:在时间 t 中,参数 λ 的期望值是多少?
# -*- coding: utf-8 -*-
import numpy as np
from matplotlib import pyplot as plt
import pymc as pm
count_data = np.loadtxt("data/txtdata.csv")
n_count_data = len(count_data)
plt.bar(np.arange(n_count_data), count_data, color="#348ABD")
plt.xlabel("Time (days)")
plt.ylabel("count of text-msgs received")
plt.title("Did the user‘s texting habits change over time?")
plt.xlim(0, n_count_data)
alpha = 1.0 / count_data.mean() # Recall count_data is the
# variable that holds our txt counts
lambda_1 = pm.Exponential("lambda_1", alpha)
lambda_2 = pm.Exponential("lambda_2", alpha)
tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data)
@pm.deterministic
def lambda_(tau=tau, lambda_1=lambda_1, lambda_2=lambda_2):
out = np.zeros(n_count_data)
out[:tau] = lambda_1 # lambda before tau is lambda1
out[tau:] = lambda_2 # lambda after (and including) tau is lambda2
return out
print("tau Random output:", tau.random(), tau.random(), tau.random())
#print("lambda distribution:", lambda_(tau, lambda_1, lambda_2))
observation = pm.Poisson("obs", lambda_, value=count_data, observed=True)
model = pm.Model([observation, lambda_1, lambda_2, tau])
mcmc = pm.MCMC(model)
mcmc.sample(40000, 10000, 1)
lambda_1_samples = mcmc.trace(‘lambda_1‘)[:]
print "lambda_1_samples"
print lambda_1_samples
lambda_2_samples = mcmc.trace(‘lambda_2‘)[:]
print "lambda_2_samples"
print lambda_2_samples
tau_samples = mcmc.trace(‘tau‘)[:]
print "tau_samples"
print tau_samples
# tau_samples, lambda_1_samples, lambda_2_samples contain
# N samples from the corresponding posterior distribution
N = tau_samples.shape[0]
expected_texts_per_day = np.zeros(n_count_data)
for day in range(0, n_count_data):
# ix is a bool index of all tau samples corresponding to
# the switchpoint occurring prior to value of ‘day‘
ix = day < tau_samples # 如果天数在转折点tau之前,取值lambda_1,否则取lambda_2,然后在取平均值
# Each posterior sample corresponds to a value for tau.
# for each day, that value of tau indicates whether we‘re "before"
# (in the lambda1 "regime") or
# "after" (in the lambda2 "regime") the switchpoint.
# by taking the posterior sample of lambda1/2 accordingly, we can average
# over all samples to get an expected value for lambda on that day.
# As explained, the "message count" random variable is Poisson distributed,
# and therefore lambda (the poisson parameter) is the expected value of
# "message count".
print "lambda_1_samples[ix]"
print lambda_1_samples[ix]
print "lambda_2_samples[~ix]"
print lambda_2_samples[~ix]
expected_texts_per_day[day] = (lambda_1_samples[ix].sum() # 这个期望值我们假设是服从泊松分布的,分布的期望值=参数lambda。
+ lambda_2_samples[~ix].sum()) / N
plt.plot(range(n_count_data), expected_texts_per_day, lw=4, color="#E24A33",
label="expected number of text-messages received")
plt.xlim(0, n_count_data)
plt.xlabel("Day")
plt.ylabel("Expected # text-messages")
plt.title("Expected number of text-messages received")
plt.ylim(0, 60)
plt.bar(np.arange(len(count_data)), count_data, color="#348ABD", alpha=0.65,
label="observed texts per day")
plt.legend(loc="upper left");
plt.show()
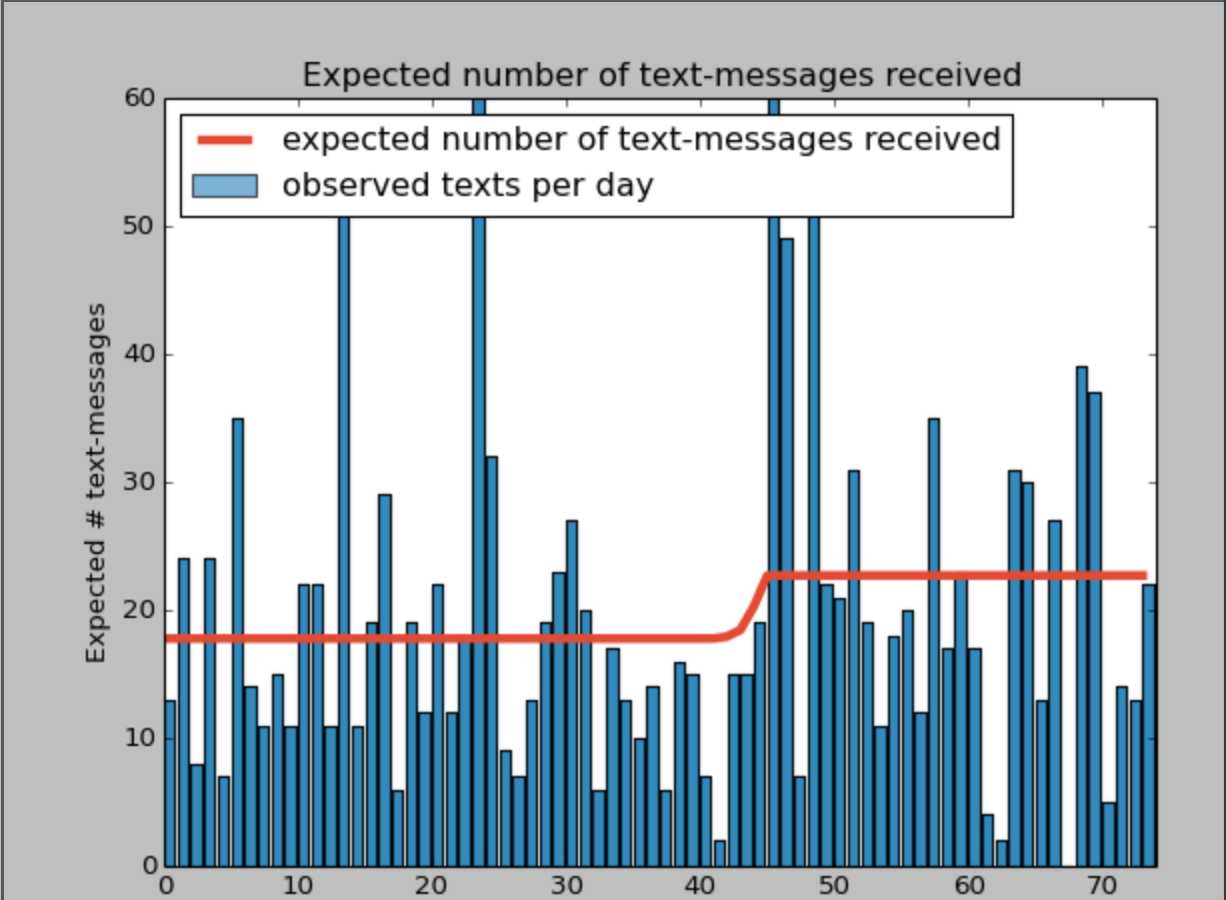
在代码中可以看到,给定某天 t,我们对所有可能的 λ 求均值。
1. 基于后验样本,从统计学上确定两个 λ 是否真的不一样
我们基于参数 λ 的后验分布得到一个结论,λ 存在阶跃点。但是如果这不是真相呢?有一部分分布其实是重合的呢?这个可能性有多大呢?怎么量化地评估这个可能性呢?
一个方法就是计算出 P(λ1 < λ2 | data),即在获得观察数据的前提下,λ1 的真实值比 λ2 小的概率。
print (lambda_1_samples < lambda_2_samples).mean() 0.999933333333
很显然,有99.93%的概率说这两个值是不相等的。
可以看到,这本质上是计算在 λ1 和 λ2 后验概率分布的重合程度。
0x7:扩充至两个阶跃点 - 能否借助贝叶斯推理自动挖掘潜在的规律?
我们在章节的一开始就作出一个假设,即认为我们的数据集中蕴含了一个现象,即用户的行为模式在某个时间点发生了突变。
但是是否存在可能说这个转折点不只一个呢?
假设现在我们对一个转折点表示很怀疑,我们现在认为用户的行为发生了两次改变.扩充之后,用户的行为分为三个阶段,三个泊松分布对应三个λ1,λ2,λ3,两个转折点τ1,τ2。

# -*- coding: utf-8 -*- import numpy as np from matplotlib import pyplot as plt import pymc as pm count_data = np.loadtxt("data/txtdata.csv") n_count_data = len(count_data) plt.bar(np.arange(n_count_data), count_data, color="#348ABD") plt.xlabel("Time (days)") plt.ylabel("count of text-msgs received") plt.title("Did the user‘s texting habits change over time?") plt.xlim(0, n_count_data) alpha = 1.0 / count_data.mean() # Recall count_data is the # variable that holds our txt counts lambda_1 = pm.Exponential("lambda_1", alpha) lambda_2 = pm.Exponential("lambda_2", alpha) lambda_3 = pm.Exponential("lambda_3", alpha) tau_1 = pm.DiscreteUniform("tau_1", lower=0, upper=n_count_data-1) tau_2 = pm.DiscreteUniform("tau_2", lower=tau_1, upper=n_count_data) @pm.deterministic def lambda_(tau_1=tau_1, tau_2=tau_2, lambda_1=lambda_1, lambda_2=lambda_2, lambda_3=lambda_3): out = np.zeros(n_count_data) out[:tau_1] = lambda_1 # lambda before tau is lambda1 out[tau_1:tau_2] = lambda_2 # lambda after (and including) tau is lambda2 out[tau_2:] = lambda_3 # lambda after (and including) tau is lambda2 return out observation = pm.Poisson("obs", lambda_, value=count_data, observed=True) model = pm.Model([observation, lambda_1, lambda_2, lambda_3, tau_1, tau_2]) mcmc = pm.MCMC(model) mcmc.sample(40000, 10000) lambda_1_samples = mcmc.trace(‘lambda_1‘)[:] lambda_2_samples = mcmc.trace(‘lambda_2‘)[:] lambda_3_samples = mcmc.trace(‘lambda_3‘)[:] tau_1_samples = mcmc.trace(‘tau_1‘)[:] tau_2_samples = mcmc.trace(‘tau_2‘)[:] # histogram of the samples: # lambda_1 ax = plt.subplot(311) ax.set_autoscaley_on(False) plt.hist(lambda_1_samples, histtype=‘stepfilled‘, bins=30, label="$lambda_1$", normed=True) plt.legend(loc="upper left") plt.grid(True) plt.title(r"""Posterior distributions of the variables $lambda_1,;lambda_2,; au$""") # x轴坐标范围 plt.xlim([15, 30]) plt.xlabel("$lambda_1$ value") # lambda_2 ax = plt.subplot(312) ax.set_autoscaley_on(False) plt.hist(lambda_2_samples, histtype=‘stepfilled‘, bins=30, label=" $lambda_2$",color=‘#3009A6‘,normed=True) plt.legend(loc="upper left") plt.grid(True) plt.xlim([30, 90]) plt.xlabel("$lambda_2$ value") # lambda_3 ax = plt.subplot(313) ax.set_autoscaley_on(False) plt.hist(lambda_3_samples, histtype=‘stepfilled‘, bins=30, label=" $lambda_2$",color=‘#6A63A6‘,normed=True) plt.legend(loc="upper left") plt.grid(True) plt.xlim([15, 30]) plt.xlabel("$lambda_3$ value") plt.show()
# -*- coding: utf-8 -*- import numpy as np from matplotlib import pyplot as plt import pymc as pm count_data = np.loadtxt("data/txtdata.csv") n_count_data = len(count_data) plt.bar(np.arange(n_count_data), count_data, color="#348ABD") plt.xlabel("Time (days)") plt.ylabel("count of text-msgs received") plt.title("Did the user‘s texting habits change over time?") plt.xlim(0, n_count_data) alpha = 1.0 / count_data.mean() # Recall count_data is the # variable that holds our txt counts lambda_1 = pm.Exponential("lambda_1", alpha) lambda_2 = pm.Exponential("lambda_2", alpha) lambda_3 = pm.Exponential("lambda_3", alpha) tau_1 = pm.DiscreteUniform("tau_1", lower=0, upper=n_count_data-1) tau_2 = pm.DiscreteUniform("tau_2", lower=tau_1, upper=n_count_data) @pm.deterministic def lambda_(tau_1=tau_1, tau_2=tau_2, lambda_1=lambda_1, lambda_2=lambda_2, lambda_3=lambda_3): out = np.zeros(n_count_data) out[:tau_1] = lambda_1 # lambda before tau is lambda1 out[tau_1:tau_2] = lambda_2 # lambda after (and including) tau is lambda2 out[tau_2:] = lambda_3 # lambda after (and including) tau is lambda2 return out observation = pm.Poisson("obs", lambda_, value=count_data, observed=True) model = pm.Model([observation, lambda_1, lambda_2, lambda_3, tau_1, tau_2]) mcmc = pm.MCMC(model) mcmc.sample(40000, 10000) lambda_1_samples = mcmc.trace(‘lambda_1‘)[:] lambda_2_samples = mcmc.trace(‘lambda_2‘)[:] lambda_3_samples = mcmc.trace(‘lambda_3‘)[:] tau_1_samples = mcmc.trace(‘tau_1‘)[:] tau_2_samples = mcmc.trace(‘tau_2‘)[:] # histogram of the samples: # lambda_1 # tau_1 w = 1.0 / tau_1_samples.shape[0] * np.ones_like(tau_1_samples) plt.hist(tau_1_samples, bins=count_data, alpha=1, label=r"$ au_1$",color="blue",weights=w ) plt.grid(True) plt.legend(loc="upper left") plt.xlabel(r"$ au_1$ (in days)") plt.ylabel("probability") # tau_2 w = 1.0 / tau_2_samples.shape[0] * np.ones_like(tau_1_samples) plt.hist(tau_2_samples, bins=count_data, alpha=1, label=r"$ au_2$",weights=w,color="red",) plt.xticks(np.arange(count_data)) plt.grid(True) plt.legend(loc="upper left") plt.ylim([0, 1.0]) plt.xlim([35, len(count_data) - 20]) plt.xlabel(r"$ au_2$ (in days)") plt.ylabel("probability") plt.show()
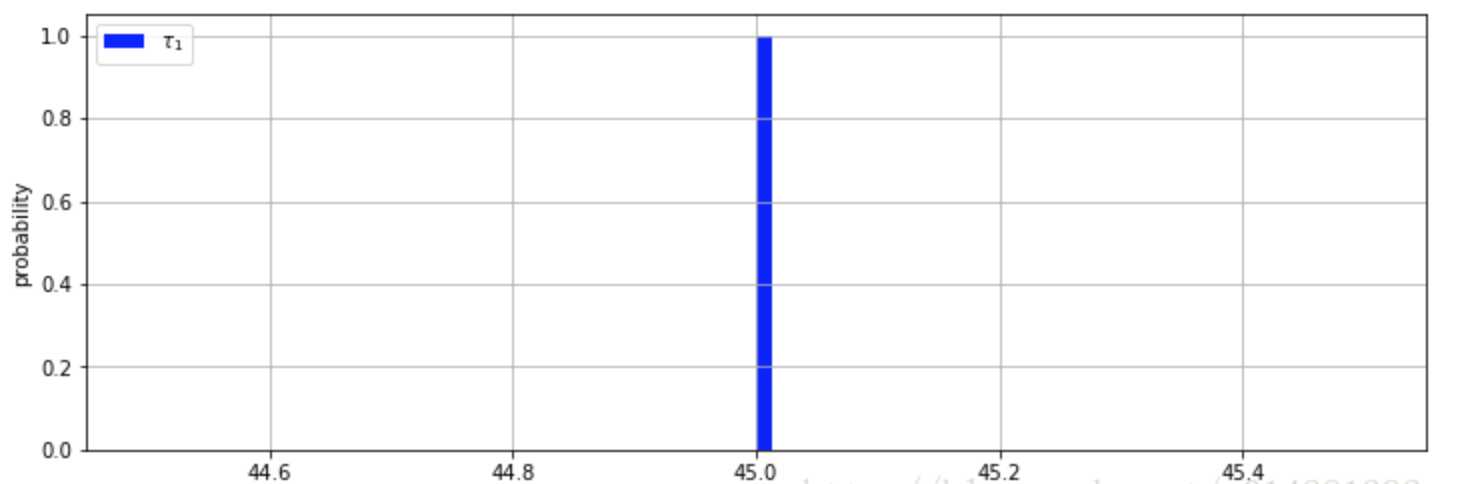
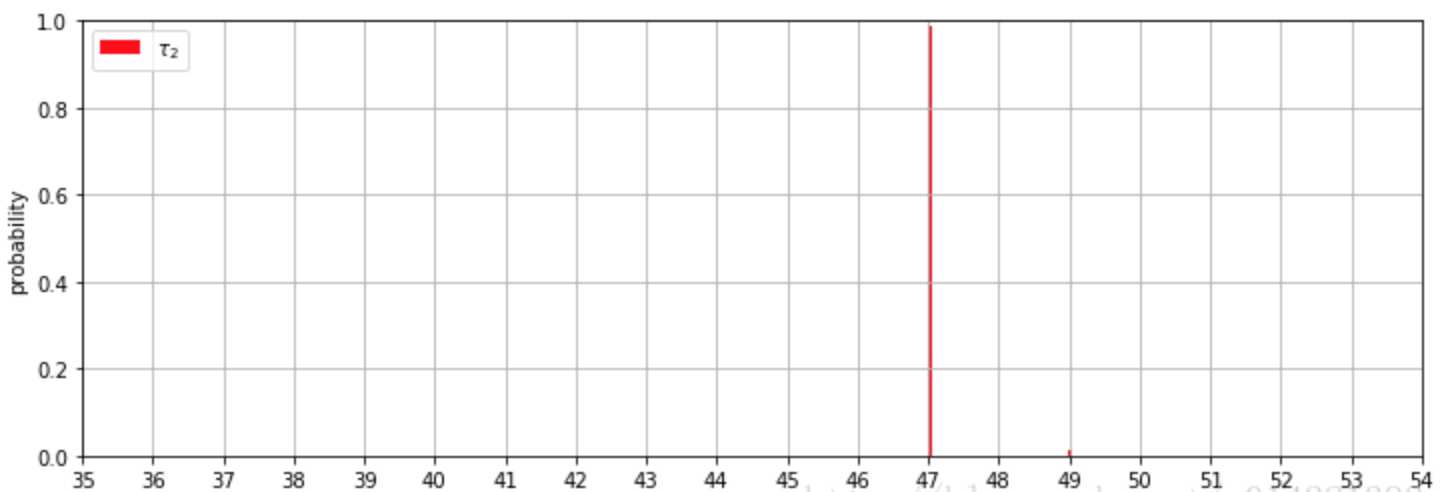
贝叶斯推理展示了5个未知数的后验推理结果。我们可以看到模型的转折点大致在第45天和第47天的时候取得。这个是真实的情况吗?我们的模型有可能过拟合了吗?
确实,我们都可能对数据中有多少个转折点抱有怀疑的态度。这意味着应该有多少个转折点可以通过设置一个先验分布,并让模型自己做决定。
这是一种非常重要的思想:我们对所有未知的变量都可以用一个先验分布来假设它,通过观测样本的训练,得到最佳的后验分布。
Relevant Link:
https://blog.csdn.net/u014281392/article/details/79330286
以上是关于贝叶斯推断 && 概率编程初探的主要内容,如果未能解决你的问题,请参考以下文章