py16 面向对象深入
Posted wlx97e6
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了py16 面向对象深入相关的知识,希望对你有一定的参考价值。
类的继承
什么是继承:
在python中,新建的类可以继承一个或多个父类,通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”。
python中类的继承分为:单继承和多继承
class ParentClass1: #定义父类
pass
class ParentClass2: #定义父类
pass
class SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类是SubClass
pass
class SubClass2(ParentClass1,ParentClass2): #python支持多继承,用逗号分隔开多个继承的类
pass
查看继承
>>> SubClass1.__bases__ #__base__只查看从左到右继承的第一个子类,__bases__则是查看所有继承的父类 (<class ‘__main__.ParentClass1‘>,) >>> SubClass2.__bases__ (<class ‘__main__.ParentClass1‘>, <class ‘__main__.ParentClass2‘>)
经典类与新式类
1.只有在python2中才分新式类和经典类,python3中统一都是新式类 2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类 3.在python2中,显式地声明继承object的类,以及该类的子类,都是新式类 3.在python3中,无论是否继承object,都默认继承object,即python3中所有类均为新式类
提示:如果没有指定基类,python的类会默认继承object类,object是所有python类的基类,它提供了一些常见方法(如__str__)的实现
>>> ParentClass1.__bases__ (<class ‘object‘>,) >>> ParentClass2.__bases__ (<class ‘object‘>,)
继承的实现原理
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如
>>> F.mro() #等同于F.__mro__ [<class ‘__main__.F‘>, <class ‘__main__.D‘>, <class ‘__main__.B‘>, <class ‘__main__.E‘>, <class ‘__main__.C‘>, <class ‘__main__.A‘>, <class ‘object‘>]
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
- 子类会先于父类被检查
- 多个父类会根据它们在列表中的顺序被检查
- 如果对下一个类存在两个合法的选择,选择第一个父类
在Java和C#中子类只能继承一个父类,而Python中子类可以同时继承多个父类,如果继承了多个父类,那么属性的查找方式有两种,分别是:深度优先和广度优先
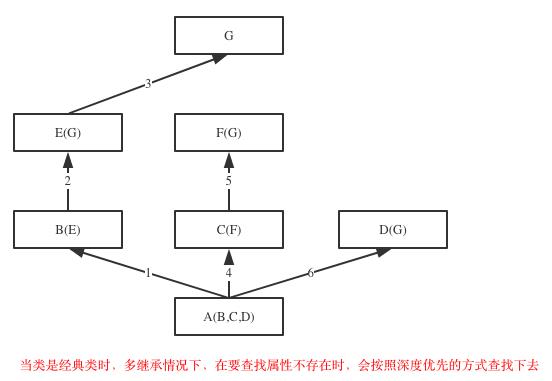
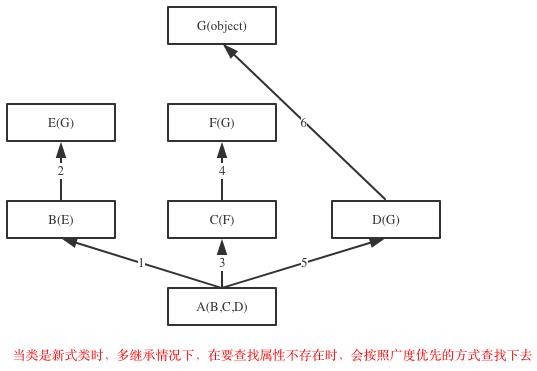
示范代码
class A(object):
def test(self):
print(‘from A‘)
class B(A):
def test(self):
print(‘from B‘)
class C(A):
def test(self):
print(‘from C‘)
class D(B):
def test(self):
print(‘from D‘)
class E(C):
def test(self):
print(‘from E‘)
class F(D,E):
# def test(self):
# print(‘from F‘)
pass
f1=F()
f1.test()
print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性
#新式类继承顺序:F->D->B->E->C->A
#经典类继承顺序:F->D->B->A->E->C
#python3中统一都是新式类
#pyhon2中才分新式类与经典类
在子类中调用父类的方法
在子类派生出的新方法中,往往需要重用父类的方法,我们有两种方式实现
方式一:指名道姓,即父类名.父类方法() 注意:这种调用需要在参数中加self
class Vehicle: #定义交通工具类
Country=‘China‘
def __init__(self,name,speed,load,power):
self.name=name
self.speed=speed
self.load=load
self.power=power
def run(self):
print(‘开动啦...‘)
class Subway(Vehicle): #地铁
def __init__(self,name,speed,load,power,line):
Vehicle.__init__(self,name,speed,load,power)
self.line=line
def run(self):
print(‘地铁%s号线欢迎您‘ %self.line)
Vehicle.run(self)
line13=Subway(‘中国地铁‘,‘180m/s‘,‘1000人/箱‘,‘电‘,13)
line13.run()
方式二:super() 注意:这种调用不用在参数中加self
class Vehicle: #定义交通工具类
Country=‘China‘
def __init__(self,name,speed,load,power):
self.name=name
self.speed=speed
self.load=load
self.power=power
def run(self):
print(‘开动啦...‘)
class Subway(Vehicle): #地铁
def __init__(self,name,speed,load,power,line):
#super(Subway,self) 就相当于实例本身 在python3中super()等同于super(Subway,self)
super().__init__(name,speed,load,power)
self.line=line
def run(self):
print(‘地铁%s号线欢迎您‘ %self.line)
super(Subway,self).run()
class Mobike(Vehicle):#摩拜单车
pass
line13=Subway(‘中国地铁‘,‘180m/s‘,‘1000人/箱‘,‘电‘,13)
line13.run()
这两种方式的区别是:方式一是跟继承没有关系的,而方式二的super()是依赖于继承的,并且即使没有直接继承关系,super仍然会按照mro继续往后查找
#A没有继承B,但是A内super会基于C.mro()继续往后找
class A:
def test(self):
super().test()
class B:
def test(self):
print(‘from B‘)
class C(A,B):
pass
c=C()
c.test() #打印结果:from B
print(C.mro())
#[<class ‘__main__.C‘>, <class ‘__main__.A‘>, <class ‘__main__.B‘>, <class ‘object‘>]
组合与继承
组合就是把一个对象传给另一个类作为类的参数,或者把对象添加到另一个对象中
>>> class Equip: #武器装备类
... def fire(self):
... print(‘release Fire skill‘)
...
>>> class Riven: #英雄Riven的类,一个英雄需要有装备,因而需要组合Equip类
... camp=‘Noxus‘
... def __init__(self,nickname):
... self.nickname=nickname
... self.equip=Equip() #用Equip类产生一个装备,赋值给实例的equip属性
...
>>> r1=Riven(‘锐雯雯‘)
>>> r1.equip.fire() #可以使用组合的类产生的对象所持有的方法
release Fire skill
class People:
def __init__(self,name,age,sex):
self.name=name
self.age=age
self.sex=sex
class Course:
def __init__(self,name,period,price):
self.name=name
self.period=period
self.price=price
def tell_info(self):
print(‘<%s %s %s>‘ %(self.name,self.period,self.price))
class Teacher(People):
def __init__(self,name,age,sex,job_title):
People.__init__(self,name,age,sex)
self.job_title=job_title
self.course=[]
self.students=[]
class Student(People):
def __init__(self,name,age,sex):
People.__init__(self,name,age,sex)
self.course=[]
egon=Teacher(‘egon‘,18,‘male‘,‘沙河霸道金牌讲师‘)
s1=Student(‘牛榴弹‘,18,‘female‘)
python=Course(‘python‘,‘3mons‘,3000.0)
linux=Course(‘python‘,‘3mons‘,3000.0)
#为老师egon和学生s1添加课程
egon.course.append(python)
egon.course.append(linux)
s1.course.append(python)
#为老师egon添加学生s1
egon.students.append(s1)
#使用
for obj in egon.course:
obj.tell_info()
抽象类和接口
首先看java为什么有接口,因为java的类不能多继承,接口用来实现多继承,且java接口中方法都为抽象方法。
java中抽象类和接口的区别:抽象类由abstract关键字来修饰,接口由interface关键字来修饰。抽象类中除了有抽象方法外,也可以有数据成员和非抽象方法;而接口中所有的方法必须都是抽象的,接口中也可以定义数据成员,但必须是常量。
接口
在python中根本就没有一个叫做interface的关键字,如果非要去模仿接口的概念
可以借助第三方模块:http://pypi.python.org/pypi/zope.interface
在python中实现抽象类
#一切皆文件
import abc #利用abc模块实现抽象类
class All_file(metaclass=abc.ABCMeta):
all_type=‘file‘
@abc.abstractmethod #定义抽象方法,无需实现功能
def read(self):
‘子类必须定义读功能‘
pass
@abc.abstractmethod #定义抽象方法,无需实现功能
def write(self):
‘子类必须定义写功能‘
pass
# class Txt(All_file):
# pass
#
# t1=Txt() #报错,子类没有定义抽象方法
class Txt(All_file): #子类继承抽象类,但是必须定义read和write方法
def read(self):
print(‘文本数据的读取方法‘)
def write(self):
print(‘文本数据的读取方法‘)
class Sata(All_file): #子类继承抽象类,但是必须定义read和write方法
def read(self):
print(‘硬盘数据的读取方法‘)
def write(self):
print(‘硬盘数据的读取方法‘)
class Process(All_file): #子类继承抽象类,但是必须定义read和write方法
def read(self):
print(‘进程数据的读取方法‘)
def write(self):
print(‘进程数据的读取方法‘)
wenbenwenjian=Txt()
yingpanwenjian=Sata()
jinchengwenjian=Process()
#这样大家都是被归一化了,也就是一切皆文件的思想
wenbenwenjian.read()
yingpanwenjian.write()
jinchengwenjian.read()
print(wenbenwenjian.all_type)
print(yingpanwenjian.all_type)
print(jinchengwenjian.all_type)
封装和类中各种特殊方法
封装
在python中用双下划线开头的方式将属性隐藏起来(设置成私有的)
【非特殊调用情况下,子类和实例化的对象不能继承,重写,使用该方法或属性。特殊调用都可以,原因在下面代码里】
#其实这仅仅这是一种变形操作,在解释器解析class时自动变形
#类中所有双下划线开头的名称如__x都会自动变形成:_类名__x的形式:
#由于只有在解析class定义时才会变形,所以只要是本类外的类或对象都无法访问原形式
class A:
__N=0 #类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N
def __init__(self):
self.__X=10 #变形为self._A__X
def __foo(self): #变形为_A__foo
print(‘from A‘)
def bar(self):
self.__foo() #只有在类内部才可以通过__foo的形式访问到.
#A._A__N是可以访问到的,即这种操作并不是严格意义上的限制外部访问,仅仅只是一种语法意义上的变形
这种自动变形的特点:
- 类中定义的__x只能在内部使用,如self.__x,引用的就是变形的结果。
- 这种变形其实正是针对外部的变形,在外部是无法通过__x这个名字访问到的。
- 在子类定义的__x不会覆盖在父类定义的__x,因为子类中变形成了:_子类名__x,而父类中变形成了:_父类名__x,即双下滑线开头的属性在继承给子类时,子类是无法覆盖的。
这种变形需要注意的问题是:
1、这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:_类名__属性,然后就可以访问了,如a._A__N
2、变形的过程只在类的定义是发生一次,在定义后的赋值操作,不会变形
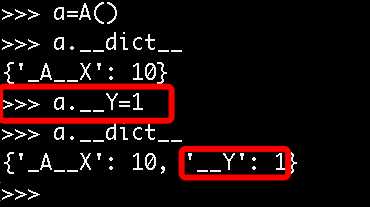
3、在继承中,父类如果不想让子类覆盖自己的方法,可以将方法定义为私有的
#正常情况 >>> class A: ... def fa(self): ... print(‘from A‘) ... def test(self): ... self.fa() ... >>> class B(A): ... def fa(self): ... print(‘from B‘) ... >>> b=B() >>> b.test() from B #把fa定义成私有的,即__fa >>> class A: ... def __fa(self): #在定义时就变形为_A__fa ... print(‘from A‘) ... def test(self): ... self.__fa() #只会与自己所在的类为准,即调用_A__fa ... >>> class B(A): ... def __fa(self): ... print(‘from B‘) ... >>> b=B() >>> b.test() from A
封装的意义
1:封装数据,将数据隐藏起来这不是目的。隐藏起来然后对外提供操作该数据的接口才是目的
class Teacher:
def __init__(self,name,age):
self.__name=name
self.__age=age
def tell_info(self):
print(‘姓名:%s,年龄:%s‘ %(self.__name,self.__age))
def set_info(self,name,age):
if not isinstance(name,str):
raise TypeError(‘姓名必须是字符串类型‘)
if not isinstance(age,int):
raise TypeError(‘年龄必须是整型‘)
self.__name=name
self.__age=age
t=Teacher(‘egon‘,18)
t.tell_info()
t.set_info(‘egon‘,19)
t.tell_info()
2:封装方法:目的是隔离复杂度
#取款是功能,而这个功能有很多功能组成:插卡、密码认证、输入金额、打印账单、取钱
#对使用者来说,只需要知道取款这个功能即可,其余功能我们都可以隐藏起来,很明显这么做
#隔离了复杂度,同时也提升了安全性
class ATM:
def __card(self):
print(‘插卡‘)
def __auth(self):
print(‘用户认证‘)
def __input(self):
print(‘输入取款金额‘)
def __print_bill(self):
print(‘打印账单‘)
def __take_money(self):
print(‘取款‘)
def withdraw(self):
self.__card()
self.__auth()
self.__input()
self.__print_bill()
self.__take_money()
a=ATM()
a.withdraw()
各种特殊方法:classmethod,staticmethod,property
staticmethod
在类的方法定义语句上方写上@staticmethod代表其为静态方法,该方法与类的联系不大,静态方法没有默认的self参数,和普通函数一样,当然也可以给他传self(对象名)
classmethod
把类中的函数定义成类方法,使self.参数无法访问对象的参数,只能访问类里的同名参数
class Role:
name = "我是类name"
def __init__(self, name, role, weapon):
self.name = name
self.role = role
self.weapon = weapon
@staticmethod
def stamethod(a,self):
print(self.name)
print(a)
@classmethod
def clsmethod(cls): # def clsmethod(self):
print(cls.name) # print(self.name)
r1 = Role(‘Chenronghua‘, ‘police‘, ‘AK47‘)
r1.clsmethod()
r1.stamethod(‘没有默认参数,self需要自己传‘, r1)
###############
我是类name
Chenronghua
没有默认参数,self需要自己传
property
将一个类的函数定义成特性以后,对象再去使用的时候obj.name,根本无法察觉自己的name是执行了一个函数然后计算出来的,这种特性的使用方式遵循了统一访问的原则
ps:面向对象的封装有三种方式: 【public】 这种其实就是不封装,是对外公开的 【protected】 这种封装方式对外不公开,但对朋友(friend)或者子类(形象的说法是“儿子”,但我不知道为什么大家 不说“女儿”,就像“parent”本来是“父母”的意思,但中文都是叫“父类”)公开 【private】 这种封装对谁都不公开
python并没有在语法上把它们三个内建到自己的class机制中,在C++里一般会将所有的所有的数据都设置为私有的,然后提供set和get方法(接口)去设置和获取,在python中通过property方法可以实现
class Foo:
def __init__(self,val):
self.__NAME=val #将所有的数据属性都隐藏起来
@property
def name(self):
return self.__NAME #obj.name访问的是self.__NAME(这也是真实值的存放位置)
@name.setter # 当对name赋值时该函数被调用
def name(self,value):
if not isinstance(value,str): #在设定值之前进行类型检查
raise TypeError(‘%s must be str‘ %value)
self.__NAME=value #通过类型检查后,将值value存放到真实的位置self.__NAME
@name.deleter # 当name被删除时,该函数被调用
def name(self):
raise TypeError(‘Can not delete‘)
f=Foo(‘egon‘)
print(f.name)
# f.name=10 #赋值,调用setter,抛出异常‘TypeError: 10 must be str‘
del f.name #删除,调用deleterious,抛出异常‘TypeError: Can not delete‘
元类及元类控制类的创建,实例化过程
参考http://www.cnblogs.com/linhaifeng/articles/8029564.html
一、知识储备
exec:三个参数
参数一:字符串形式的命令 参数二:全局作用域(字典形式),如果不指定,默认为globals(),把运行中全局变量传入globals 参数三:局部作用域(字典形式),如果不指定,默认为locals(),把运行中局部变量传入locals
exec的使用
#可以把exec命令的执行当成是一个函数的执行,会将执行期间产生的名字存放于局部名称空间中
g={
‘x‘:1,
‘y‘:2
}
l={}
exec(‘‘‘
global x,z
x=100
z=200
m=300
‘‘‘,g,l)
print(g) #{‘x‘: 100, ‘y‘: 2,‘z‘:200,......}
print(l) #{‘m‘: 300}
二 、什么是元类?
首先要知道python中万物皆是对象,类也是对象,元类是类的类,是类的模板
元类是用来控制如何创建类的,正如类是创建对象的模板一样,而元类的主要目的是为了控制类的创建行为
元类的实例化的结果为我们用class定义的类,正如类的实例为对象(f1对象是Foo类的一个实例,Foo类是 type 类的一个实例)
type是python的一个内建元类,用来直接控制生成类,python中任何class定义的类其实都是type类实例化的对象
class Foo:
pass
f1=Foo() #f1是通过Foo类实例化的对象
#type函数可以查看类型,也可以用来查看对象的类,二者是一样的
print(type(f1)) # 输出:<class ‘__main__.Foo‘> 表示,obj 对象由Foo类创建
print(type(Foo)) # 输出:<class ‘type‘>
三、创建类的两种方式
第一步先看类的创建流程:
首先,要知道,解释器解释到新变量时会分配名称空间,类创建也不例外,类体定义的名字都会存放于类的名称空间中(一个局部的名称空间),然后对名称空间进行填充。
第二步调用元类来创建类。
方式一:使用class关键字
class Chinese(object):
country=‘China‘
def __init__(self,name,age):
self.name=name
self.age=age
def talk(self):
print(‘%s is talking‘ %self.name)
方式二:就是手动模拟class创建类的过程):将创建类的步骤拆分开,手动去创建
#准备工作:
#创建类主要分为三部分
1 类名
2 类的父类(元类)
3 类体
#类名
class_name=‘Chinese‘
#类的父类
class_bases=(object,)
#类体
class_body="""
country=‘China‘
def __init__(self,name,age):
self.name=name
self.age=age
def talk(self):
print(‘%s is talking‘ %self.name)
"""
步骤一(先处理类体->名称空间):类体定义的名字都会存放于类的名称空间中(一个局部的名称空间),我们可以事先定义一个空字典,然后用exec去执行类体的代码(exec产生名称空间的过程与真正的class过程类似,只是后者会将__开头的属性变形),生成类的局部名称空间,即填充字典
class_dic={}
exec(class_body,globals(),class_dic)
print(class_dic)
#{‘country‘: ‘China‘, ‘talk‘: <function talk at 0x101a560c8>, ‘__init__‘: <function __init__ at 0x101a56668>}
步骤二:调用元类type(也可以自定义)来产生类Chinense
Foo=type(class_name,class_bases,class_dic) #实例化type得到对象Foo,即我们用class定义的类Foo print(Foo, Foo.country) print(type(Foo)) print(isinstance(Foo,type)) ‘‘‘ <class ‘__main__.Chinese‘> China#表示由Chinese类创建,这也是type的第一个参数的作用 <class ‘type‘> True ‘‘‘
我们看到,type 接收三个参数:
- 第 1 个参数是字符串‘Chinese’,表示类名,print(Foo)时即可看到,第一个参数和type等号左边的参数可保持一致
- 第 2 个参数是元组 (object, ),表示所有的父类
- 第 3 个参数是字典,这里是一个空字典,表示没有定义属性和方法
补充:若Foo类有继承,即class Foo(Bar):.... 则等同于type(‘Foo‘,(Bar,),{})
元类控制类的行为(类创建及实例化总流程)
知识储备:
类默认继承object,新式类不写也默认继承。
__call__方法在对象被调用时被使用,类也是对象,所以会调用父类(元类)的__call__
类实例化对象实际上经历三件事:1、产生空对象obj 2、初始化 3、返回obj
代码如下,讲解在代码下方
class Mymeta(type): #继承默认元类的一堆属性
def __init__(self,class_name,class_bases,class_dic):
if not class_name.istitle():
raise TypeError(‘类名首字母必须大写‘)
super(Mymeta,self).__init__(class_name,class_bases,class_dic)
def __call__(self, *args, **kwargs):
#self=People
print(self,args,kwargs) #<class ‘__main__.People‘> (‘egon‘, 18) {}
#1、调用self,即People下的函数__new__,在该函数内完成:1、产生空对象obj 2、初始化 3、返回obj
obj=self.__new__(self,*args,**kwargs)
#2、一定记得返回obj,因为实例化People(...)取得就是__call__的返回值
return obj
class People(object,metaclass=Mymeta):
country=‘China‘
def __init__(self,name,age):
self.name=name
self.age=age
def talk(self):
print(‘%s is talking‘ %self.name)
def __new__(cls, *args, **kwargs):
obj=object.__new__(cls)
cls.__init__(obj,*args,**kwargs)
return obj
obj=People(‘egon‘,18)
print(obj.__dict__) #{‘name‘: ‘egon‘, ‘age‘: 18}
#####调试顺序,按行号来#####
#1-2-18-19-21-25-2-3-6-33-10-13-29-30-21-22-23-31-16-34
难以理解的几个点:
1.为什么从25跳到2,因为此时People还未被调用,还没轮到__call__方法出马,此时参考第二种type创建类的方式,看看__init__的参数是不是和type参数一样?这里就是在普通类被实例化之前先调用初始化函数,初始化完成立马到33进行普通类(普通类也是对象)的调用,然后进入__call__方法。
2.进入call方法之后的13-29及以后:在33行普通类被调用后进入8行的call方法后,需要完成三个指标,1、产生空对象obj 2、初始化 3、返回obj。在元类的__call__方法里调用了普通类的__new__方法进行三步走,普通类使用object.__new__(cls)来创建空对象,然后对空对象进行初始化(30-21),最后返回对象,大功告成。
元类应用
#应用:定制元类实现单例模式
class Mymeta(type):
def __init__(self,name,bases,dic): #定义类mysql时就触发
self.__instance=None
super().__init__(name,bases,dic)
def __call__(self, *args, **kwargs): #Mysql(...)时触发
if not self.__instance:
self.__instance=object.__new__(self) #产生对象
self.__init__(self.__instance,*args,**kwargs) #初始化对象
#上述两步可以合成下面一步
# self.__instance=super().__call__(*args,**kwargs)
return self.__instance
class Mysql(metaclass=Mymeta):
def __init__(self,host=‘127.0.0.1‘,port=‘3306‘):
self.host=host
self.port=port
obj1=Mysql()
obj2=Mysql()
print(obj1 is obj2)
以上是关于py16 面向对象深入的主要内容,如果未能解决你的问题,请参考以下文章