第4章 图像分类(image classification)基础
Posted paladinzxl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第4章 图像分类(image classification)基础相关的知识,希望对你有一定的参考价值。
第4章 图像分类基础
一张图片胜过千言万语。我们不断地攫取视觉内容,解释它的含义,并且存储它们以备后用。
但是,对于计算机要解释一张图片的内容是很难的,因为计算机看到的图片是一个大的数字矩阵,它对图像传递的思想、知识和意义一无所知。
为了理解图像的内容,我们必须应用图像分类(image classification),这是使用计算机视觉和机器学习算法从图像中抽取意义的任务。这个操作可以简单的为一张图像分配一个标签,如猫、狗还是大象,或者也可以高级到解释图像的内容并且返回一个人类可读的句子。
图像分类是一个非常大的研究领域,包括各种各样的技术,随着深度学习的普及,它还在继续发展。
现在,是时候来驾驭深度学习与图像分类的浪潮了!
图像分类和图像理解是目前(并将继续是)未来十年最受欢迎的计算机视觉子领域。
在本章中,我将提供图像分类的高级概述,以及图像分类算法必须克服的许多挑战。我们还会复习与图像分类和机器学习相关的三种不同学习类型。最后,我们将通过讨论四个步骤来总结本章,这四个步骤是如何训练一个用于图像分类的深度学习网络,以及这四个步骤是如何与传统的手工设计的特征提取管道进行比较的。
1 图像分类是什么?
图像分类,核心是从给定的分类集合中给图像分配一个标签的任务。实际上,这意味着我们的任务是分析一个输入图像并返回一个将图像分类的标签。标签总是来自预定义的可能类别集。
示例:我们假定一个可能的类别集categories = {dog, cat, panda},之后我们提供一张图片(图1)给分类系统:

图1 图像分类目标是根据输入图片且根据预定义类别分配标签
这里的目标是根据输入图像,从类别集中分配一个类别,这里为dog。
我们的分类系统也可以根据概率给图像分配多个标签,如dog:95%,cat:4%,panda:1%。
更一般的,给定三个通道的W*H像素,我们的目标是取W*H*3=N个像素且找出正确分类图像内容的方法。
1.1 关于术语的说明
当执行机器学习和深度学习时,数据集(dataset)是我们尝试提取知识的地方。在数据集中的每个例子/条目(可能使图像数据、文本数据、语音数据)称为数据点(data point)。
图2 数据集是数据点的集合
我们的目标是应用机器学习和深度学习算法来发现在数据集中的潜在模式,使我们能够正确的分类我们的算法还没有遇到的数据点(即泛化性能)。现在考虑下面的术语:
(1) 在图像分类方面,我们的数据集就是图像的集合;
(2) 因此,每个图像就是一个数据点。
注意:在后续过程中,我们将图像和数据点交替使用,可认为是同一个意义。
1.2 语义上的差异
看图3上部的左右图像,我们能够很容易的分辨出猫和狗,但是对于所有计算机来说看到的则是对应于图3下部左右的大的像素矩阵。

图3 上:人类认知图片的方式 下:计算机看到图片以矩阵方式
考虑到计算机看到的是大的像素矩阵,我们引入语义差异(semantic gap)问题。语义差距是人对图像内容的感知方式与计算机能够理解图像过程的表现方式之间的差异。
再次,人类可以快速揭示出图3上部两幅图的差异,但是计算机却不知道图中有动物存在。为了更清晰解释,看图4:

图4 当描述图片内容时,我们可能关注空间层次、颜色、质地传递的内容——计算机视觉算法也是同样关注这些
我们可能描述图像如下:
(1) 空间:天空在图像上部,沙滩和海洋在底部;
(2) 颜色:天空是深蓝色,海水颜色比天空浅,而沙子是黄色的;
(3) 质地:天空比较均匀,沙子较粗糙
那么,我们怎么编码这些信息使得计算机能够理解?答案就是应用特征提取(feature extraction)来量化图像的内容。特征提取是输入一副图像、实施一个算法、且获得量化我们图像的一个特征向量(feature vector)(例如,一系列数字)的过程。
为了完成这个过程,我们可以考虑使用手工设计的功能,如HOG、LBPs或其它传统方法来度量图像。而本书中采用的是另一种方法,即应用深度学习来自动学习一系列特征,这些特征可以用来度量且最终标记图像本身的内容。
但是,一旦我们开始检查真实世界的图像,我们将面临很多很多的挑战。
1.3 挑战
如果语义差异还不是一个大问题,那么我们还要处理图像或对象的变化因素(factors of variation)。图5显示了不同的变化因素:

图5 我们需要认识到物体是如何在不同的视点、光照条件、遮挡和尺度等等下出现的。
首先,我们看视点变化(viewpoint variation),即物体对应于是如何被拍照或获取的造成是原始还是多维度旋转的图像,但不管怎么视点变化,树莓派还是树莓派如图5左上所示。
我们还将面对缩放变化(scale variation),如图5的scale variation所示,无论如何缩放除了大小size不同,它们是同样的东西。图像分类方法必须适应这种变化。
最困难的则是变形(deformation),如图5的deformation所示,所有这些图像都包含了图像的特性,但是它们之间都是弹性、扭曲、动态变化的。
图像分类还应当处理闭合变化(occlusions variation),即如图5的occlusion variation所示,两幅图中都是狗,但是右图被隐藏在其它图像之下,图像分类应当能够处理这种情况。
就像变形和闭合的挑战一样,我们还要面临光照变化(illumination variation),如图5所示,我们应当能够分类出同样得到咖啡杯,但是由于光照使得他们看起来很不同。
我们还要处理背景杂乱(background clutter),如图5所示,当我们需要在杂乱背景下要分类出图像的特定物体时,对于我们都是困难的,何况是电脑了。
最后,我们还要处理类内变化(intra-class variation),如图5所示,同样的椅子确有不同的种类,而我们的图像分类算法必须能够识别出所有正确的种类。
有没有感到一点困难?更困难的是,图像分类器不仅仅是面对上述单个的变化,往往面临着多个变化的联合。
那么,我们该如何处理如此多的变化呢?一般来说,尽最大努力去做。我们对图像的内容和希望容忍的变化做出假定,我们也考虑项目的最终目的是什么?以及我们尝试去构建什么样的系统?
部署到现实世界中的成功的计算机视觉、图像分类和深度学习系统,在编写一行代码之前,要做出谨慎的假设和考虑。如果你的方法过于宽泛,如我想对厨房里的每一件物品进行分类,那么你的分类系统很可能不是很好。但是如果你把问题缩小,如我想对火炉和冰箱进行分类,那么你的分类系统更容易获得较高的准确率。
这里的关键是要始终考虑图像分类器的范围。尽管深度学习和CNNs在不同的挑战下具有极大的鲁棒性和分类能力,但是你仍然要关注项目的范围尽可能紧致且定义明确。
深度学习不是魔法,它有时是很有力的工具但是如果使用不当也是很危险的。在这本书的其余部分,我将指导你的深度学习之旅,并帮助你指出什么时候你应该使用这些强力的工具,什么时候你应该使用更简单的方法(或者提到是否一个问题用图像分类来解决是不合理的)。
2 学习的类型
在深度学习和机器学习领域主要有三种学习类型:监督学习、非监督学习和半监督学习。本书主要关注深度学习背景下的监督学习。这里将简要描述三种类型。
2.1 监督学习
监督学习是机器学习中研究最广泛的一类。给定训练数据,创建一个训练过程的模型(分类器),这个模型对输入数据做出预测且预测不准确时将进行纠正。持续这个训练过程直到达到一些期望的停止准则,如较低的错误率或达到最大的训练次数等。
常见的监督学习算法包括Logistic Regression、Support Vector Machines(SVMs)、Random Forests和ANN。
在图像分类的背景下,我们假定图像数据集包括图像本身和对应的分类标签(class labels),分类标签用于训练机器学习分类器将每个种类看起来像什么。如果分类器做出了错误预测,则可以运用一些方法来纠正错误。
即监督学习中,每个数据点都由标签、特征向量构成。
2.2 非监督学习
与监督学习对应,非监督学习(也称为自学)没有标签数据,只有特征向量。
非监督学习是机器学习和深度学习的“圣杯”。因为现实世界中很容易获得大量无标签数据,如果我们能够从无标签数据中学的模式,那么可以不必花费大量时间和金钱来标记标签数据用于监督学习。
经典的非监督学习机器算法包括PCA和K均值。应用到神经网络,有Autoencoders、Self Organizing Maps (SOMs)和Adaptive Resonance Theory可用于非监督学习。非监督学习是一个极其活跃的、还没有解决的领域,本书将不关注非监督学习。
2.3 半监督学习
如果一部分数据有标签,另一部分没有标签,则称之为半监督学习。
半监督式学习在计算机视觉中尤其有用,因为在训练集中,给每一张图片都贴上标签通常是费时、乏味和昂贵的(至少在工时方面)。我们可以对数据中的一小部分标签,然后利用半监督学习给剩余的数据进行标签和分类。
半监督学习算法常工作在较小的数据集上在可以容忍的精确度下。即半监督学习考虑了精确度与数据大小的关系,在可容忍的限度下保持分类精确度,可以极大的降低训练的数据量大小。半监督学习常见的选择包括label spreading、label propagation、ladder networks和co-learning/co-training。
再次,我们在本书中主要研究监督学习,因为非监督和半监督学习在计算机视觉的深度学习背景下的研究仍然是非常新的领域且还没有清晰的方法可以使用。(该书是2017年出版的,那么可能写作是在2015-2016?那么现在为2018年,是否还没有清晰的方法???)
3 深度学习分类步骤
通过前两节的学习,你可能会开始觉得在构建一个图像分类器时,新的术语、考虑和看起来不可逾越的变化会给你带来一些压力,但事实是,一旦你理解了这个过程,构建一个图像分类器是相当简单的。
在本节中,我们将回顾当在深度学习工作中需要考虑的在心态方面的一个重要转变。我们将回顾在构建一个深度、基于学习的图像分类器的4个步骤,并且对比传统的基于特征的机器学习和端到端的深度学习。
3.1 心态的转变
我们可能写过成百上千的基于过程的或基于对象的函数,这些函数都有很好的定义,且很容易的验证其结果。
不幸的是,在深度学习和图像分类中不是这样的过程。
对于猫、狗的图片,我们不能简单的编写确定的语句来识别它们,因此,与其试图构建一个基于规则的系统来描述每个类别的“外观”,我们可以采用基于数据驱动的方法,提供每个类别的示例,然后教我们的算法使用这些示例识别类别之间的差异。
我们输入这些打上标签的训练数据集,在训练集中的每个数据点包括:
(1) 一张图像;
(2) 这张图像的标签或分类。
3.2 步骤一:收集数据集
构建深度学习网络的第一个部件是收集最初的数据集。我们需要图像本身和与图像相关的标签。标签应当是一个有限的类别集合。
此外,每个种类中的图像数据应当是均匀的(例如,每个类别的图像数目相同)。如果数目不同则造成类别失衡,类别失衡是机器学习的常见问题,我们在后续中来介绍不同的方法,但是注意避免类别失衡产生的学习问题的最佳方法是避免类别失衡。
3.3 步骤二:划分数据集
既然我们有了数据集,我们需要划分成两部分:
(1)训练集(training set)
(2)测试集(testing set)
我们的分类器使用训练集通过在输入数据上做出预测来“学习”每个类别看起来像什么,且当预测错误的时候分类器做出纠正。分类器完成训练之后,我们可以在测试集上评估性能。
训练集和测试集是互相独立且互不重叠,是极其重要的!!!常见的训练集和测试集划分为66.7%/33/3%,75%/25%,90%/10%,如图6所示:
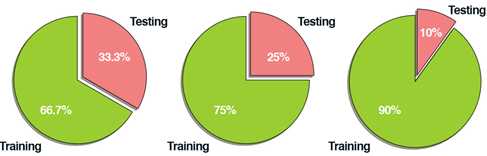
图6 常见训练集和测试集划分
这些划分是合理的,那么我们需要调整的参数是什么呢?神经网络中有一些控制参数(如学习率、衰减因子、正则化因子等)需要调整以达到网络最佳性能,这些参数我们称之为超参数(hyperparameters),它们设定的合理是极其重要的。
实际上,我们需要一堆超参数且需要识别出最佳的超参数集合。你可能想使用测试集来调整这些超参数值,再次注意:测试集仅仅用作评估网络性能!
而是,我们需要第三个划分的数据集称为验证集(validation set),这个数据集合通常来自训练集且用作“假测试数据”,用于调整超参数。仅在我们使用验证集确定了超参数值之后,我们才会在测试集上收集最终的精确度结果。
我们通常分配训练集的10%—20%用于验证。
划分数据集听起来很复杂,实际上,将在下一章将要讲到的,归功于python的scikit-learn库,我们可以使用一行代码即可划分。
3.4 步骤三:训练网络
给定图像的训练集,我们现在可以训练网络了。我们网络的目标是学习怎样识别标签数据中的每个类别。当网络做出错误预测时,它将从错误中学习且提高自己的预测能力。
那么,真实的“学习”是怎样工作的?一般来说,我们使用一种梯度下降的形式(a form of gradient descent),将在第9章中介绍。本书的剩余部分将从头来例证怎样训练神经网络,因此这里我们推迟它,直到需要时再进行详细的训练过程讨论。
3.5 步骤四:评估
最后,我们需要评估我们训练的网络。对于测试集中的每个图像,送入网络中且网络预测它认为这张图像的标签是什么。之后,我们的网络模型将测试集中对图像的预测结果列表化。
最后,这些模型预测将与测试集的真实标签结果进行比对。我们将能够计算出模型预测的正确的数目,且获得一些聚合报告,如精确度(precision)、召回率(recall)、f-度量(f-measure)等,这些参数通常用来度量整个网络性能。
3.6 图像分类:基于特征的学习VS深度学习
传统上,对于图像分类的基于特征的学习,实际上是在步骤二和步骤三中间插入一个步骤:特征提取(feature extraction)。在这一阶段,我们采用手动设计的算法如HOG、LBPs等,基于我们想编码(例如形状、颜色、质地等)的图像的特定部分来度量图像的内容。给定这些特征,我们之后执行训练网络和评估网络。
当构建CNNs网络的时候,我们实际上跳过了特征提取的步骤。原因是CNNs是一个端到端的模型。我们将原始输入数据(像素)输入网络。然后网络学习隐藏层内的过滤器,这些过滤器可以用来区分对象类。网络的输出是类别标签上的概率分布。
其中一个激动的方面是,我们可以让CNNs自动的学习特征而不需要手动设计特征。但是这种权衡是有代价的。训练CNNs是一个不平凡的过程,所以要准备好花大量的时间让自己熟悉这些经验,并做很多实验来确定什么是有效的,什么是无效的。
3.7 当预测不正确时,发生了什么?
我们训练好了网络,也在测试集上获得了良好的性能,但是当我们的网络对不在训练集也不在测试集中的其它外部未见到的图像进行预测时,获得了较差的性能,这个问题称之为泛化(generalization)。泛化是网络泛化的能力,即正确的预测即不存在训练集也不存在与测试集中的图像的类别标签的能力。
网络的泛化将在本书多次讨论,这里仅是大概介绍。当不能正确的预测图像分类时,不要沮丧,要考虑第2章中提到的变化因素。你的训练集正确的反映了这些变化因素吗?如果没有,那么你需要收集更多的训练数据(且需要读本书的剩余部分,来学习其它技术来克服泛化)。
以上是关于第4章 图像分类(image classification)基础的主要内容,如果未能解决你的问题,请参考以下文章