机器学习之激励函数
Posted chihaoyuisnothere
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之激励函数相关的知识,希望对你有一定的参考价值。
1、sigmoid

sigmod函数曾经是比较流行的,它可以想象成一个神经元的放电率,在中间斜率比较大的地方是神经元的敏感区,在两边斜率很平缓的地方是神经元的抑制区。当然,流行也是曾经流行,这说明函数本身是有一定的缺陷的:
1) 当输入稍微远离了坐标原点,函数的梯度就变得很小了,几乎为零。在神经网络反向传播的过程中,我们都是通过微分的链式法则来计算各个权重w的微分的。当反向传播经过了sigmod函数,这个链条上的微分就很小很小了,况且还可能经过很多个sigmod函数,最后会导致权重w对损失函数几乎没影响,这样不利于权重的优化,这个问题叫做梯度饱和,也可以叫梯度弥散。
2) 函数输出不是以0为中心的,这样会使权重更新效率降低。对于这个缺陷,在斯坦福的课程里面有详细的解释。
3) sigmod函数要进行指数运算,这个对于计算机来说是比较慢的。
2、tanh
3、Relu
(1)当输入是负数的时候,ReLU是完全不被激活的,这就表明一旦输入到了负数,ReLU就会死掉。这样在前向传播过程中,还不算什么问题,有的区域是敏感的,有的是不敏感的。但是到了反向传播过程中,输入负数,梯度就会完全到0,后面的参数就会不更新(使用合适的学习率会减弱这种情况)这个和sigmod函数、tanh函数有一样的问题。
(2) 我们发现ReLU函数的输出要么是0,要么是正数,这也就是说,ReLU函数也不是以0为中心的函数。
4.ELU函数
ELU函数公式和曲线如下图
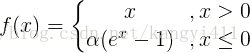
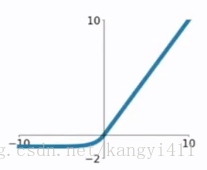
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。
5.PReLU函数
PReLU函数公式和曲线如下图
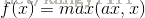
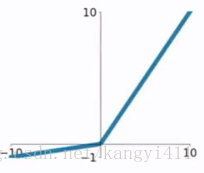
PReLU也是针对ReLU的一个改进型,在负数区域内,PReLU有一个很小的斜率,这样也可以避免ReLU死掉的问题。相比于ELU,PReLU在负数区域内是线性运算,斜率虽然小,但是不会趋于0,这算是一定的优势吧。我们看PReLU的公式,里面的参数α一般是取0~1之间的数,而且一般还是比较小的,如零点零几。当α=0.01时,我们叫PReLU为Leaky ReLU,算是PReLU的一种特殊情况吧。
总体来看,这些激活函数都有自己的优点和缺点,没有一条说法表明哪些就是不行,哪些激活函数就是好的,所有的好坏都要自己去实验中得到。
以上是关于机器学习之激励函数的主要内容,如果未能解决你的问题,请参考以下文章