B-Tree和B+Tree
Posted oldma
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了B-Tree和B+Tree相关的知识,希望对你有一定的参考价值。
首先,介绍一下什么是树(tree)
树,就是一种顺序。我们有从小到大,从大到小的顺序,也自然会有“树”这种顺序。
那么,树,是一个怎么样的顺序呢?
对于一列数,只能保持两种状态:①无序②有序
而这两者最大的区别就是:查找的方式不同
面对无序数列,我们只能依次比较,去寻找目标值。(顺序查找)
而对于有序数列,我们可以通过某种规矩去推演目标所在的位置。
而“树”,就是我们推理的规则。
一、二叉树(有序二叉查找树)
规定:在一组数列中选择一个值作为“根节点”,数列中剩下的值大于它的全部放在右侧,小于它的值全部放在左边,且所有节点最多有左右两个子节点。
1、任意一个不为空的左子树节点,则左子树的值均小于根节点的值;
2、任意一个不为空的右子数节点,则右子树的值均大于于根节点的值;
3、任意节点的左右子树也分别是二叉查找树;
4、没有键值相等的节点;
查询方式:比较节点值和目标值,目标较大往右,较小则往左,等于则找到。
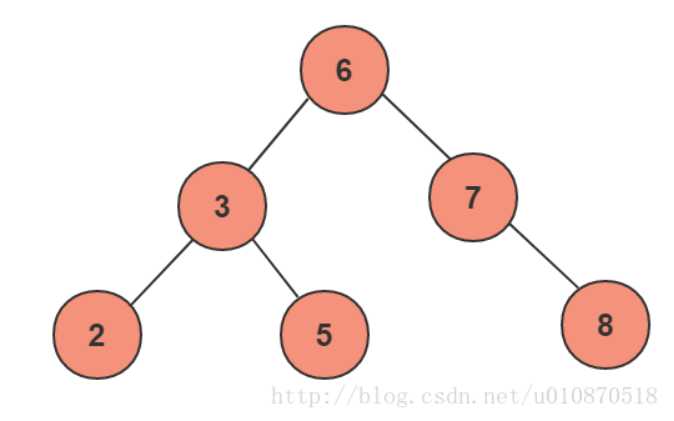
以图中为例:
我们想要查找“5”这个目标值,需要6→3→5三步。
而如果是“3“、”7”这两个目标值,就只需两步。
所以,平均下来就是(3+3+3+2+2+1)/6 = 2.3
然后,我们在跟无序数列的依次查找作比较:
从最好到最坏情况:(1+2+3+4+5+6)/6 = 3.3
很明显,以“树”这种顺序查找,要比依次查找快好多。
但是,我们说这有一种局限性,就是如果根节点没有选择“6”,而是选择了最小的“2”,那么树就会变成这样:
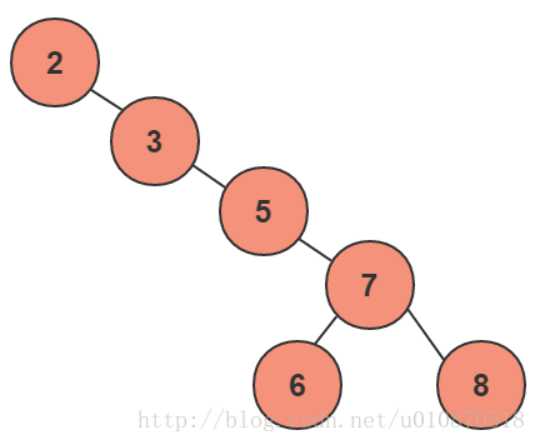
当树变成这样时,我们在来查找就会
(1+2+3+4+5+5)/6 = 3.16
这与“顺序查找”几乎一样,所以树的建立异常重要。
二、AVL树(平衡二叉树——Balance Tree)
在普通二叉树的基础上,AVL树严格要求了:
所有节点的左右子树高度差不超过1
也就是,刚开始演示的那棵“树”。
如果,左右子树的高度超出了要求,那么就要用到“旋转”
旋转重排序
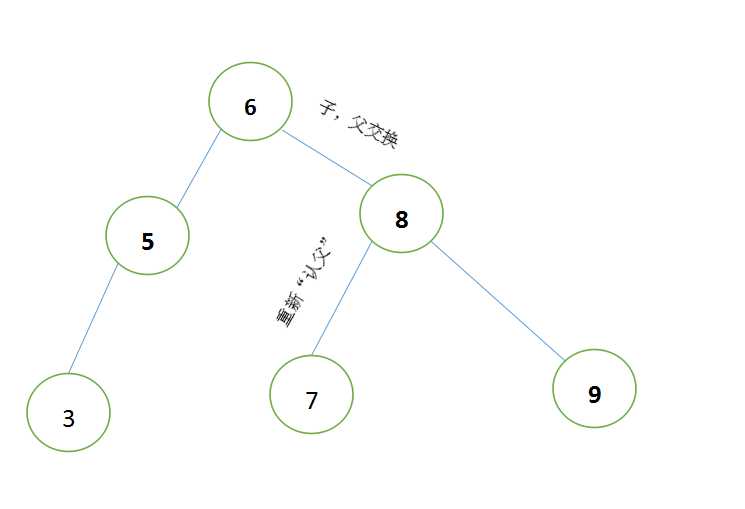
口诀:子、父换位,重新“认父”,叶子不动
来看下图理解:
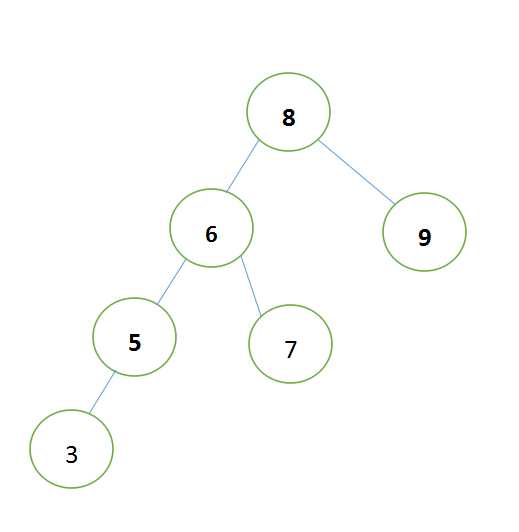
上图就是常说的LL型,但我个人觉得讨论这些“型”没有任何意义。
第一步:找到哪两个节点相差2,图中为“3”与“9”;
第二步:找到在“3”这条分支上与“9”同级的节点,图中为“6”;
第三步:将子节点与父节点换位,图中为“6”与“8”
第四步:将多出来的节点,按照二叉树的规定重新分配,图中为‘7’变更为“8”的子节点。
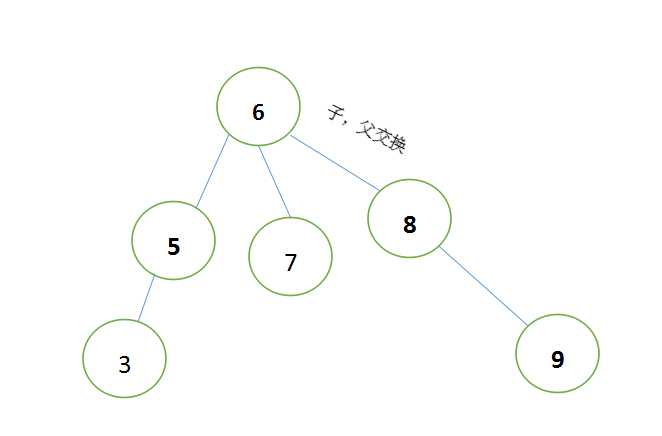
按照,此方不论是LR、RL、RR 都能够轻易翻转:
如下图的RL:
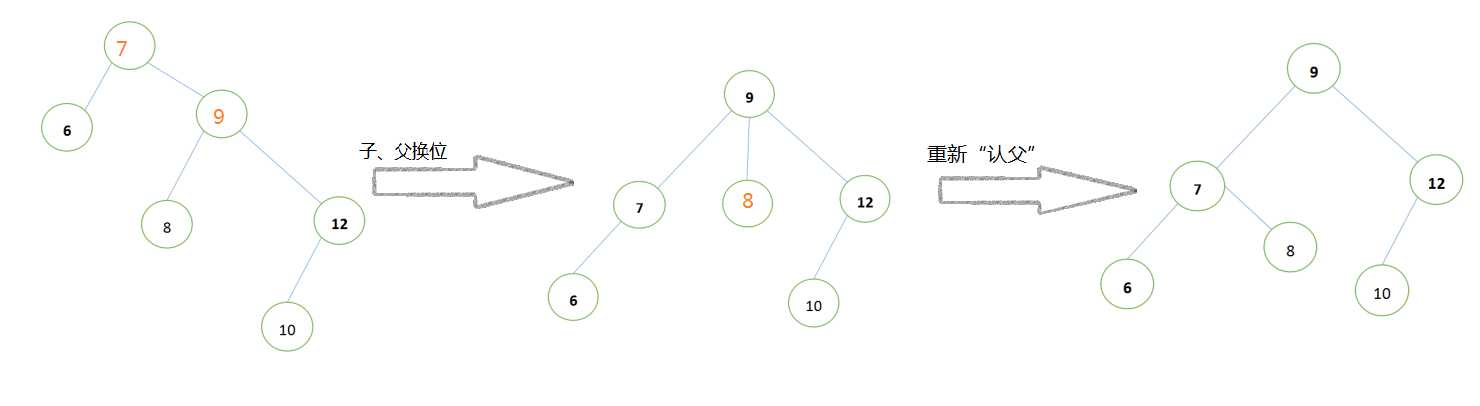
很显然,这种二叉树一旦变动,就相当麻烦,所以人们就又发明了一个条件不那么苛刻的树。
三、红黑树
由于,它也是一种二叉树,所以它在具备普通二叉树的条件外,新增:
1、每个结点要么是红的要么是黑的
2、根节点是黑色的
3、每个叶节点(叶节点即树尾端NIL指针或NULL结点)都是黑的
4、如果一个结点时红的,那么它的两个儿子都是黑的
5、对于任意结点而言,其到叶节点树尾端NIL指针的每条路径都包含相同数目的黑结点。
为什么,它能比AVL树相对来说宽松一些呢?
我说下,一个困扰我很久的问题:就是"红"、“黑”到底代表什么?
这个其实很简单,就是将数列分成两组数来保持平衡,红、黑只是记号,你要想叫“蓝”、“白”树也随你。
那怎么来保持平衡呢?这种平衡怎么就比AVL松了呢?
我们,先抛开“树”不谈,我们先讲一个小学知识—间隔插入
规定:公路上种了5棵树,头尾不能站人,人后面必须跟着一棵树,两树之间可以不站人。
问,这5棵树中最少、最多能站多少人?
这不很简单吗,最少 = 0人 , 最多 = (5-1)4人
那么,在“红黑树”的概念上,0人平衡于4人。这就比AVL宽松多了。
关于,红黑树的插入、删除会有专门一篇来分析。
四、B-Tree(Branches Tree 多路查找树)
首先,强调一些“术语”:“高度”——从叶节点到目标节点的长度、“深度”——从根节点到目标节点的长度、“阶数”——节点的最大儿子(分支)个数
网上找的例子:
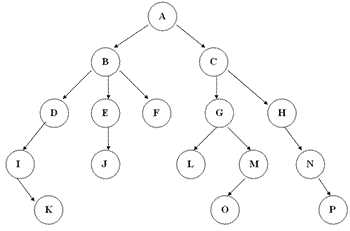
拿"G"节点举例,设根、叶节点深、高度为 0 ,“G”的深度 =2、高度 = 2、该树阶数 = 3.
所以,规定B-Tree 需满足:
1.一个M阶的B-树,每个非叶子节点最多只有M个儿子
2、根结点的儿子数为[2, M];
3、除根结点以外的非叶子结点的儿子数为[M/2, M];
4、每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5、非叶子结点的关键字个数=指向儿子的指针个数-1;
6、非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7、非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8、所有叶子结点位于同一层;
由于,B-Tree的关键字不再像二叉树那样内个节点只有一个,那么我们就不能简单的:大于往右,小于往左了。
假设,一个节点中有 5 | 7 | 10 这三个关键字,那么就是:大于10的向“最右”,大于7小于10的向“次右” ......等于关键字就取到,以此类推。
网上找的图片:
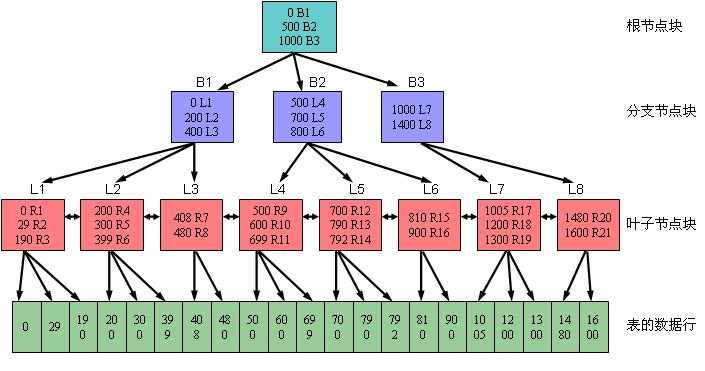
下面来看下,B-Tree的插入删除
插入:
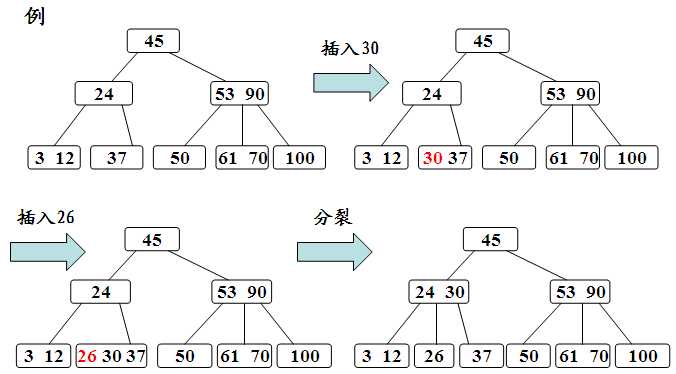
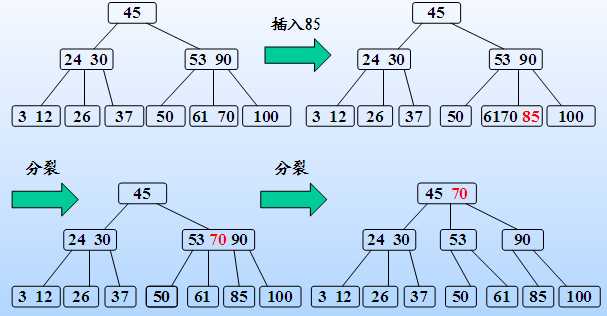
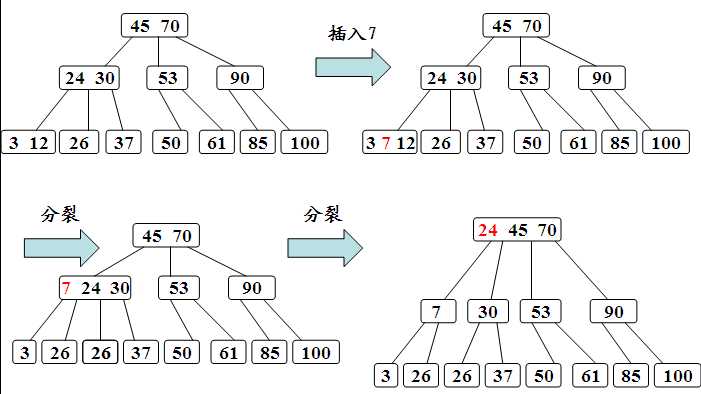
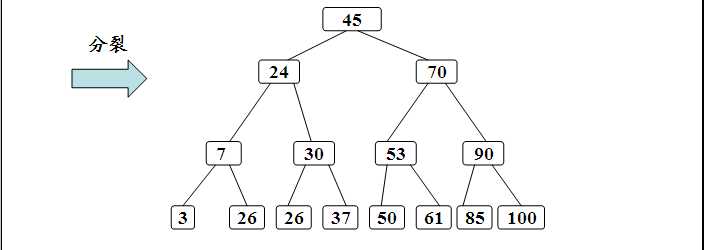
删除:
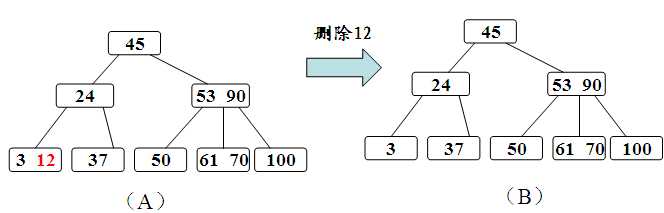
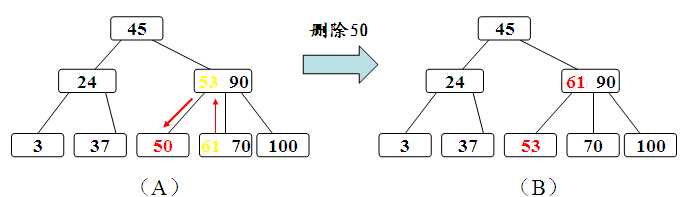
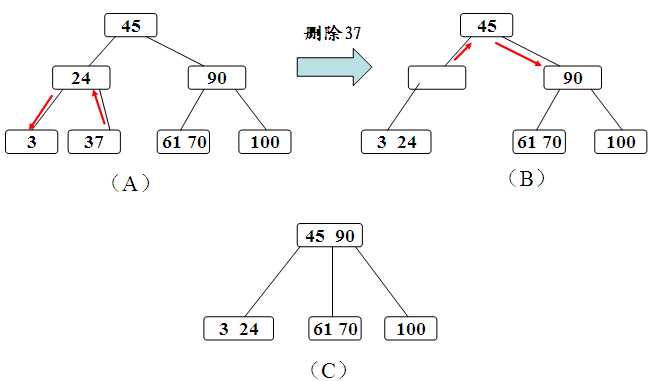
B+树
为什么要B+树
由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引,而B树则常用于文件索引。
简介
同样的,以一个m阶树为例:
- 根结点只有一个,分支数量范围为[2,m];
- 分支结点,每个结点包含分支数范围为[ceil(m/2), m];
- 分支结点的关键字数量等于其子分支的数量减一,关键字的数量范围为[ceil(m/2)-1, m-1],关键字顺序递增;
- 所有叶子结点都在同一层;
操作
其操作和B树的操作是类似的,不过需要注意的是,在增加值的时候,如果存在满员的情况,将选择结点中的值作为新的索引,还有在删除值的时候,索引中的关键字并不会删除,也不会存在父亲结点的关键字下沉的情况,因为那只是索引。
B树和B+树的区别
这都是由于B+树和B具有这不同的存储结构所造成的区别,以一个m阶树为例。
- 关键字的数量不同;B+树中分支结点有m个关键字,其叶子结点也有m个,其关键字只是起到了一个索引的作用,但是B树虽然也有m个子结点,但是其只拥有m-1个关键字。
- 存储的位置不同;B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
- 分支结点的构造不同;B+树的分支结点仅仅存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
- 查询不同;B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径
文章参考:
http://www.cnblogs.com/George1994/p/7008732.html
https://blog.csdn.net/wanghanlincsdn/article/details/61208273
以上是关于B-Tree和B+Tree的主要内容,如果未能解决你的问题,请参考以下文章