verilog乘法器的设计
Posted dinging006
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了verilog乘法器的设计相关的知识,希望对你有一定的参考价值。
在verilog编程中,常数与寄存器变量的乘法综合出来的电路不同于寄存器变量乘以寄存器变量的综合电路。知乎里的解释非常好https://www.zhihu.com/question/45554104,总结乘法器模块的实现https://blog.csdn.net/yf210yf/article/details/70156855
乘法的实现是移位求和的过程
乘法器模块的实现主要有以下三种方法
1.串行实现方法
占用资源最多,需要的时钟频率高些,但是数据吞吐量却不大
两个N位二进制数x、y的乘积用简单的方法计算就是利用移位操作来实现。
其框图如下:
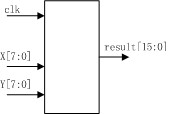
其状态图如下:
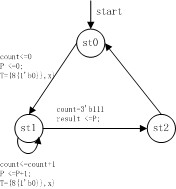
代码:
module multi_CX(clk, x, y, result); 02 03 input clk; 04 input [7:0] x, y; 05 output [15:0] result; 06 07 reg [15:0] result; 08 09 parameter s0 = 0, s1 = 1, s2 = 2; 10 reg [2:0] count = 0; 11 reg [1:0] state = 0; 12 reg [15:0] P, T; 13 reg [7:0] y_reg; 14 15 always @(posedge clk) begin 16 case (state) 17 s0: begin 18 count <= 0; 19 P <= 0; 20 y_reg <= y; 21 T <= {{8{1‘b0}}, x}; 22 state <= s1; 23 end 24 s1: begin 25 if(count == 3‘b111) 26 state <= s2; 27 else begin 28 if(y_reg[0] == 1‘b1) 29 P <= P + T; 30 else 31 P <= P; 32 y_reg <= y_reg >> 1; 33 T <= T << 1; 34 count <= count + 1; 35 state <= s1; 36 end 37 end 38 s2: begin 39 result <= P; 40 state <= s0; 41 end 42 default: ; 43 endcase 44 end 45 46 endmodule
慢速信号处理中常用到的。
2.并行流水线实现方法
将操作数的N位并行提交给乘法器,这种方法并不是最优的实现架构,在FPGA中进位的速度远大于加法的速度,因此将相临的寄存器相加,相当于一个二叉树的结构,实际上对于n位的乘法处理,需要logn级流水来实现。
一个8位乘法器,其原理图如下图所示:
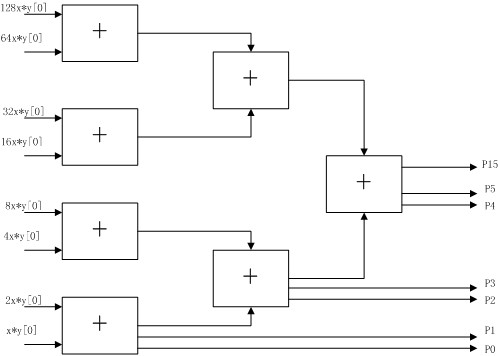
其实现的代码如下:
module multi_4bits_pipelining(mul_a, mul_b, clk, rst_n, mul_out); input [3:0] mul_a, mul_b; input clk; input rst_n; output [15:0] mul_out; reg [15:0] mul_out; reg [15:0] stored0; reg [15:0] stored1; reg [15:0] stored2; reg [15:0] stored3; reg [15:0] stored4; reg [15:0] stored5; reg [15:0] stored6; reg [15:0] stored7; reg [15:0] mul_out01; reg [15:0] mul_out23; reg [15:0] add01; reg [15:0] add23; reg [15:0] add45; reg [15:0] add67; always @(posedge clk or negedge rst_n) begin if(!rst_n) begin mul_out <= 0; stored0 <= 0; stored1 <= 0; stored2 <= 0; stored3 <= 0; stored4 <= 0; stored5 <= 0; stored6 <= 0; stored7 <= 0; add01 <= 0; add23 <= 0; add45 <= 0; add67 <= 0; end else begin stored0 <= mul_b[0]? {8‘b0, mul_a} : 16‘b0; stored1 <= mul_b[1]? {7‘b0, mul_a, 1‘b0} : 16‘b0; stored2 <= mul_b[2]? {6‘b0, mul_a, 2‘b0} : 16‘b0; stored3 <= mul_b[3]? {5‘b0, mul_a, 3‘b0} : 16‘b0; stored4 <= mul_b[0]? {4‘b0, mul_a, 4‘b0} : 16‘b0; stored5 <= mul_b[1]? {3‘b0, mul_a, 5‘b0} : 16‘b0; stored6 <= mul_b[2]? {2‘b0, mul_a, 6‘b0} : 16‘b0; stored7 <= mul_b[3]? {1‘b0, mul_a, 7‘b0} : 16‘b0; add01 <= stored1 + stored0; add23 <= stored3 + stored2; add45 <= stored5 + stored4; add67 <= stored7 + stored6; mul_out01 <= add01 + add23; mul_out23 <= add45 + add67; mul_out <= mul_out01 + mul_out23; end end endmodule
流水线乘法器比串行乘法器的速度快很多很多,在非高速的信号处理中有广泛的应用。至于高速信号的乘法一般需要利用FPGA芯片中内嵌的硬核DSP单元来实现。
3.booth算法
看了原文献,有基2和基4两种实现
最常用的主要还是基2实现也就是用被除数的每两位做编码,Booth算法对乘数从低位开始判断,根据两个数据位的情况决定进行加法、减法还是仅仅移位操作。判断的两个数据位为当前位及其右边的位(初始时需要增加一个辅助位0),移位操作是向右移动。
代码
module booth( start_sig, a, b, done_sig , product) wire [1:0] start_sig; wire [7:0] a; wire [7:0] b; wire [15:0] product; /********************************/ reg[3:0] i; reg[7:0] ra; reg[7:0] rs; reg[16:0] rp; reg[3:0] x; reg isdone; always @(posedge clk or negedge rst_n) if(!rst_n) begin i<=4‘d0; ra<=8‘d0; rs<=8‘d0; rp<=17‘d0; x<=4‘d0; isdone<=1‘b0; end else if(start_sig) case(i) 0: begin ra<=a; rs<=(~a+1); rp<={8‘d0,b,1‘b0}; i<=i+1; end 1: if(x==8) begin x<=4‘d0; i<=i+2; end else if(rp[1:0]==2‘b01) begin rp<={rp[16:9]+ra,rp[8:0]}; i<=i+1; end else if(rp[1:0]==2‘b10) begin rp<={rp[16:9]+rs,rp[8:0]}; i<=i+1; end else i<=i+1; 2: begin rp<={rp[16],rp[16:1]}; x<=x+1;//返回去检测对应寄存器值的方法 i<=i-1; end 3: begin isdone<=1‘b1; i<=i+1; end 4: begin isdone<=1‘b0; i<=4‘d0; end endcase assign product=rp[16:1]; assign done_sig=isdone; endmodule
以上是关于verilog乘法器的设计的主要内容,如果未能解决你的问题,请参考以下文章