storm并发机制,通信机制,任务提交
Posted jiyukai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了storm并发机制,通信机制,任务提交相关的知识,希望对你有一定的参考价值。
一、storm的并发
(1)Workers(JVMs):在一个物理节点上可以运行一个或多个独立的JVM进程。一个Topology可以包含一个或多个worker(并行的跑在不同的物理机上),所以worker process就是执行一个topology的子集, 并且worker只能对应于一个topology
(2)Executors(threads):在一个workerJVM进程中运行着多个Java线程。一个executor线程可以执行一个或多个tasks。但一般默认每个executor只执行一个task。一个worker可以包含一个或多个executor,每个component(spout/bolt)至少对应于一个executor,所以可以说executor执行一个compenent(spout/bolt)的子集,同时一个executor只能对应于一个component(spout/bolt)。
(3)Tasks(bolt/spout instances):Task就是具体的处理逻辑对象,每一个Spout和Bolt会被当作很多task在整个集群里面执行。每一个task对应到一个线程,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。
(4)对于并发度的配置, 在storm里面可以在多个地方进行配置,在defaults.yaml,storm.yaml,topology-specific configuration,internal component-specific configuration,external component-specific configuration 中均可以对并发度进行配置
(5)worker processes的数目, 可以通过配置文件和代码中配置, worker就是执行进程, 所以考虑并发的效果, 数目至少应该大亍machines的数目
executor的数目, component的并发线程数,只能在代码中配置(通过setBolt和setSpout的参数)
(6)tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置Topology的worker数通过config设置,即执行该topology的worker(java)进程数,可以通过storm rebalance命令任意调整。
二、storm的通信机制
worker进程间消息传递机制,消息的接收和处理的大概流程如下图:
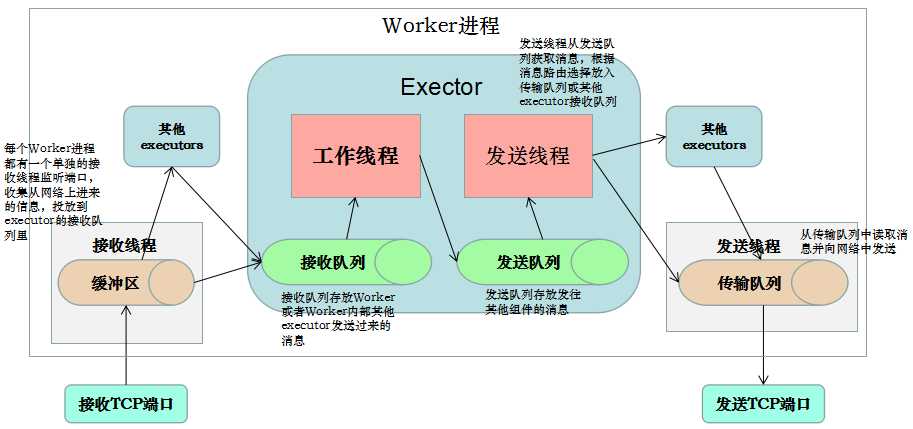
(1)对于worker进程来说,为了管理流入和传出的消息,每个worker进程有一个独立的接收线程[一个worker进程运行一个专用的接收线程来负责将外部发送过来的消息移动到对应的executor线程的incoming-queue中](对配置的TCP端口supervisor.slots.ports进行监听);
(2)对应Worker接收线程,每个worker存在一个独立的发送线程[transfer-queue的大小由参数topology.transfer.buffer.size来设置。transfer-queue的每个元素实际上代表一个tuple的集合],它负责从worker的transfer-queue中读取消息,并通过网络发送给其他worker
(3)每个executor有自己的incoming-queue[executor的incoming-queue的大小用户可以自定义配置。]和outgoing-queue[executor的outgoing-queue的大小用户可以自定义配置]。Worker接收线程将收到的消息通过task编号传递给对应的executor(一个或多个)的incoming-queues;
(4)每个executor有单独的线程分别来处理spout/bolt的业务逻辑,业务逻辑输出的中间数据会存放在outgoing-queue中,当executor的outgoing-queue中的tuple达到一定的阀值,executor的发送线程将批量获取outgoing-queue中的tuple,并发送到transfer-queue中。
(5)每个worker进程控制一个或多个executor线程,用户可在代码中进行配置。其实就是我们在代码中设置的并发度个数。
三、storm的任务提交
storm的任务提交机制大概如下图:
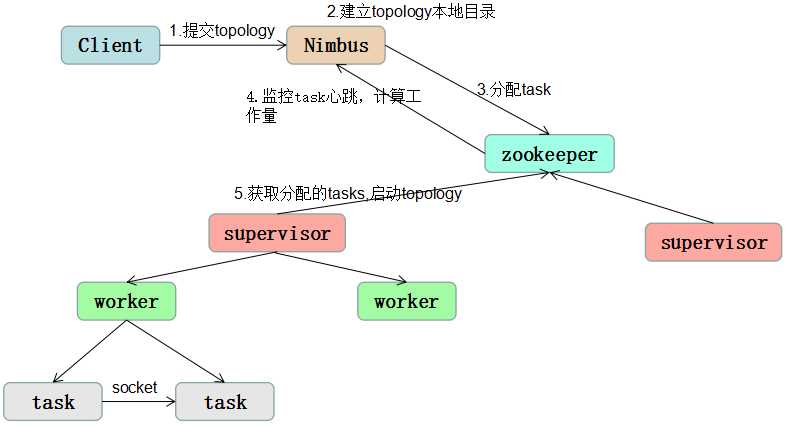
(1)客户端提交topology给nimbus
(2)提交的的jar包会上传到nimbus服务器的nimbus/inbox目录下,submitTopology方法会负责对这个topology进行处理,处理的过程包括对topology和storm的各种校验,首先检查storm的状态是否active,是否有同名的topology已经在storm中运行了(因为spout和bolt会指定id,storm会检查是否有使用了相同id的spout和bolt,注:任何一个id都不能以"_"开头,这种命名方式是系统保留的),之后nimbus还会建立topology的本地目录,nimbus/stormdist/topology-uuid,该目录包含三个文件,stormjar.jar(包含这个topology所有代码的jar包,从nimbus/inbox中移动过来),stormcode.ser(topology对象的序列化),stormconf.ser(运行这个topology的配置)
(3)完成上述检查和建立目录的工作后,nimbus根据topology定义中的parallelism hint参数,来给spout/bolt设定task数目,并且分配对应的task id,最后把分配好的task信息写入到zookeeper的/task目录下
(4)nimbus会在zookeeper上创建taskbeats目录,要求每个task每隔一段时间就要发个心跳信息
(5)nimbus将分配好的任务,写入zookeeper,同时将topology的信息写入zookeeper/storms目录
(6)supervisor定期扫描zookeeper上的storms目录,下载新的任务,根据nimbus指定的任务启动worker工作,同时supervisor还会定期删除不再运行的topology
(7)worker根据分配到的任务,根据task id分辨出哪些spout和bolt,并创建网络连接用来做消息的发送。
以上是关于storm并发机制,通信机制,任务提交的主要内容,如果未能解决你的问题,请参考以下文章