Solr02-solrconfig.xml文件详细说明
Posted shoufeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr02-solrconfig.xml文件详细说明相关的知识,希望对你有一定的参考价值。
目录
1 solrconfig.xml文件详细说明
solrconfig.xml文件位于SolrCore的conf目录下, 通过solrconfig.xml可以配置SolrCore实例的相关信息, 可不作修改.
企业项目开发中需要修改三个常用的标签: lib标签、datadir标签、requestHandler标签.
1.1 lib标签配置扩展jar包
solrconfig.xml中可以加载一些扩展的jar包.
扩展步骤:
首先要扩展的jar包复制到指定目录, 这里将其复制到SolrHome同级目录, 防止项目移动时遗忘了这些jar包, 导致项目出错(当然若有多个SolrHome, 可将这些jar包放置在SolrHome的上级目录, 如此就不必在每个SolrHome中添加这些jar包了, 从而下述路径也就无需修改了);
复制solr解压文件中的contrib和dist目录到work目录下(与SolrHome同级, 为了后期搭建集群时共用这些Jar包, 而不用每次都添加);
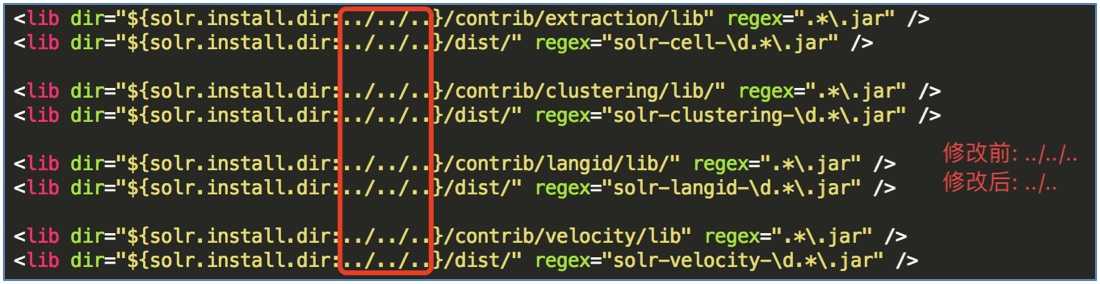
修改solrconfig.xml文件, 加载扩展的jar包:
solr.install.dir表示${SolrCore}的目录位置, 这里即为collection1内部; ./ 表示当前目录; ../ 表示上一级目录. 需作如下修改:
1.2 dataDir标签指定data目录
配置SolrCore的data目录.
data目录用来存放SolrCore的索引文件和tlog日志文件.
solr.data.dir表示${SolrCore}/data的目录位置.
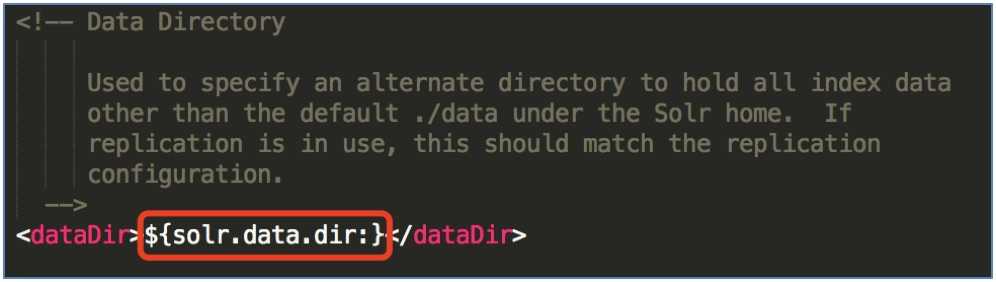
建议不作修改, 否则配置多个SolrCore时容易出错.
1.3 indexConfig标签配置索引
索引配置很多都使用了默认配置, 其中mainIndex定义了Solr处理索引的一些选项:
? (1) useCompoundFile: 通过将很多Lucene内部文件整合到一个文件, 来减少使用Lucene内部文件的数量, 这有助于减少Solr使用文件句柄的数目, 代价是降低了性能. 除非应用程序用完了文件句柄, 否则默认值false就可以了;
? (2) mergeFacor: 决定Lucene段被合并的频率, 值越小(最小为2)频率越低使用的内存较少但导致的索引时间也更慢; 较大的值可使索引时间变快但会牺牲较多的内存(典型的时间与空间的平衡配置);
? (3) maxBufferedDocs: 在合并内存中文档和创建新段之前, 定义所需索引的最小文档数. 段是用来存储索引信息的Lucene文件, 较大的值可使索引时间变快但会牺牲较多内存;
? (4) maxMergeDocs: 控制可由Solr合并的Document的最大数量, 较小的值(<10,000)最适合于具有大量更新的应用程序;
? (5) maxFieldLength: 对给定的Document, 控制可添加到Field的最大条目数, 进而截断该文档. 如果文档很大, 就需要增加这个数值. 该值设置得过高会导致内存不足异常;
? (6) unlockOnStartup: 告知Solr忽略在多线程环境中用来保护索引的锁定机制. 某些情况下, 索引可能会由于不正确的关机或其他错误而一直被锁定, 这将妨碍添加和更新操作. 将其设置为true可以禁用启动索引, 进而允许进行添加和更新.
1.4 query标签配置查询处理
query标记段中与缓存无关的特性:
? (1) maxBooleanClauses: 定义可组合在一起形成一个查询的子句数量的上限, 1024已经足够. 如果应用程序大量使用了通配符或范围查询, 增加这个限制能避免当值超出时的TooMangClausesException异常;
? (2) enableLazyFieldLoading: 如果应用程序只会检索Document上少数几个Field, 就可将这个属性设置为true. 懒加载大都发生在应用程序返回一些列的搜索结果时, 用户常常会单击其中的一个来查看存储在此索引中的原始文档, 初始往往只需要显示很短的一段信息. 若检索大型的Document, (除非必需)应该避免加载整个文档.
query部分负责定义与在Solr中发生的时间相关的选项:
? Solr(实际是Lucene)使用称为Searcher的Java类来处理Query实例, 该类将与索引相关的数据加载到内存中, 根据索引、CPU及内存的大小, 这个过程可能需要较长的一段时间. 要改进这一设计和显著提高性能, Solr引入了一种”预热”策略, 即把这些新的Searcher联机以便为现场用户提供查询服务之前, 先对它们进行"热身".
? 可使用newSearcher和firstSearcher等事件来指定在实例化newSearcher或firstSearcher时应该执行的查询. 如果应用程序期望请求某些特定的查询, 在创建newSearcher或firstSearcher时就应该反注释这些部分并执行适当的查询.
query中的智能缓存:
? (1) filterCache: 通过存储一个匹配给定查询文档的id的无序集合, 过滤器能有效提高Solr的查询性能. 缓存这些过滤器, Solr重复调用时将会在缓存的结果集中快速查找. 更常见的场景是缓存一个过滤器, 然后再发起后续的精确查询, 这种查询能使用过滤器来限制要搜索的文档数;
? (2) queryResultCache: 为查询、排序条件和所请求文档的数量缓存文档id的有序集合;
? (3) documentCache: 缓存Lucene Document, 使用内部Lucene文档的id(以便和Solr的id相区分). 由于Lucene的内部Document id会因索引操作而更改, 这种缓存不能自热;
? (4) Named caches: 命名缓存是用户定义的缓存, 可被 Solr定制插件所使用.
其中filterCache、queryResultCache、Named caches(如果实现了 org.apache.solr.search.CacheRegenerator)可以自热.
每个缓存声明都只接受最多四个属性:
class: 缓存实现的Java全限定名;
size: 最大的条目数;
initialSize: 缓存的初始大小;
autoWarmCount: 是取自旧缓存以预热新缓存的条目数, 条目多就意味着缓存的hit会更多, 需要更长的预热时间.
对所有缓存模式而言, 在设置缓存参数时, 都有必要在内存、CPU和磁盘访问之间进行均衡. 统计信息管理页(管理员界面的Statistics)对分析缓存的hit-to-miss比例以及微调缓存大小等统计数据都非常有用.
并非所有应用程序都会从缓存受益, 实际上一些应用程序反而会由于”将某个永远用不到的条目存储在缓存中”这一额外步骤而受到影响.
1.5 requestHandler标签
requestHandler请求处理器, 定义了索引和搜索的访问方式.
通过 /select 搜索索引:
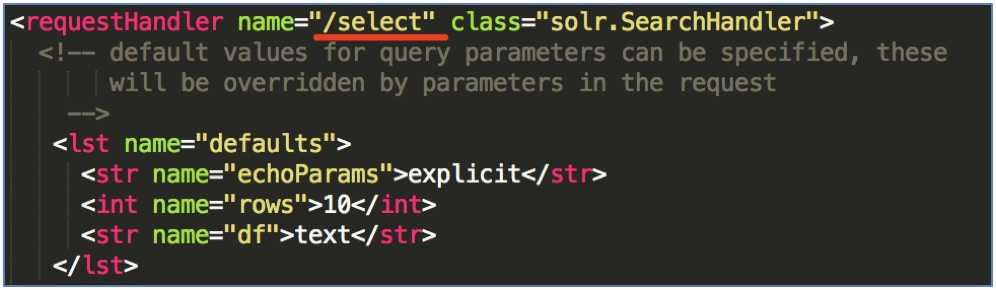
设置搜索参数完成搜索. 搜索参数也可以设置默认值, 如下:<requestHandler name="/select" class="solr.SearchHandler"> <!-- 设置默认的参数值, 可在请求地址中修改这些参数 --> <lst name="defaults"> <str name="echoParams">explicit</str> <int name="rows">10</int> <!-- 显示数量 --> <str name="wt">json</str> <!-- 显示格式 --> <str name="df">text</str> <!-- 默认搜索字段 --> </lst> </requestHandler>通过 /update 维护索引, 可以完成索引的添加、修改、删除操作.
版权声明
作者: ma_shoufeng(马瘦风)
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但未经博主同意必须保留此段声明, 且在文章页面明显位置给出原文链接, 否则博主保留追究法律责任的权利.
以上是关于Solr02-solrconfig.xml文件详细说明的主要内容,如果未能解决你的问题,请参考以下文章
详细分析Solr的CVE-2019-0193以及velocity模板注入新洞