语言模型
Posted pinking
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语言模型相关的知识,希望对你有一定的参考价值。
一、什么是语言模型
假设,对于一个观测值:“yuyanmoxing”,可能是由“语言模型”、“寓言模型”、“语言魔性” ... 等得到的,但是要想得到究竟是哪一个,通常需要计算它们的概率,譬如:P("语言模型"|"yuyanmoxing") > P("寓言模型"|"yuyanmoxing") > ... ,(P(I|O)),则可以确定为“语言模型”。如何对这个概率进行计算呢?从数学的角度来看:
![]()
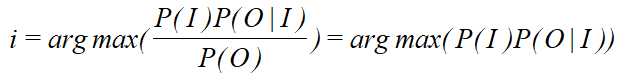
如果我们直接用第一种方法,即为判别式模型,如果用第二种方法,即为生成式模型。当采用生成式模型的话,需要计算这个语句序列出现的概率即为P(I)的概率,如何计算P(I)的概率呢?
计算一个文本序列w = { w1 ,w2 ... wn}的概率,需要知道他们之间的关系,我们对这个关系的建模即为语言模型。
二、统计语言模型
1.1 统计语言模型
要计算一个语言序列的概率,关键是看这些词的排序的关系,我们可以利用马尔科夫假设,即当前词只与当前n-1个词有关。譬如,对于序列种一个词wi,我们需要知道w1w2 ... wi-1出现时,wi发生的概率。然后根据联合概率公式即可得到句子的概率。假设句子为S,p(S)=p(w1,w2,w3,w4,w5,…,wn) =p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)。
在实际操作中,如果文本较长,则p(wn|w1,w2,...,wn-1)的计算是很困难的,假设P个词,则需要计算的概率有Pn个,作比较得到最大的。因此,推出了n-gram模型。 当n取1、2、3时,n-gram模型分别称为unigram、bigram和trigram语言模型。模型的参数估计也称为模型的训练,一般采用最大似然估计(Maximum Likelihood Estimation,MLE)的方法对模型的参数进行估计:
![]()
C(X)表示X在训练语料中出现的次数。如给定句子:
如给定句子集“<s> I am Sam </s>
<s> Sam I am </s>
<s> I do not like green eggs and ham </s>”
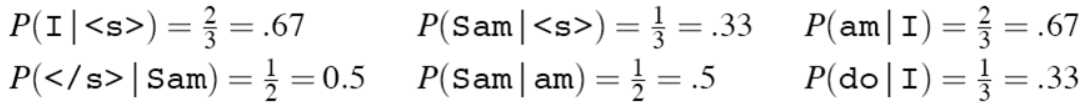
1.2 bigram与HMM
HMM就是bigram语言模型,可以利用HMM的学习问题、概率计算问题、预测问题来解决相关的问题。当然也可以通过上面利用MLE进行估计等进行计算。参考:https://www.cnblogs.com/pinking/p/8531405.html
三、神将网络语言模型
n-gram模型将词看作符号,不能很好的计算词与词之间的内在联系,泛化能力较差,后得到神将网络模型(Neural n-gram),通过对样本进行训练获得计算概率的模型,而不是通过统计的方法求概率,如图:
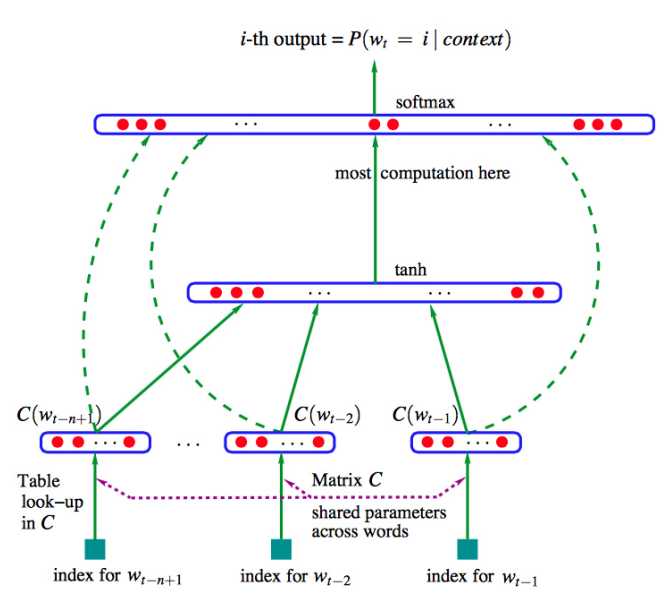
神经网络模型的架构如图,输入为n-1个词的one-hot向量,包含一个隐层,神经网络的输出为softmax后每个词出现的概率,然后根据真实语料库种真实的下一个词的one-hot向量通过最小化交叉熵训练模型。
neural n-gram模型可以捕获词之间的关系,但是利用的词有限,只能利用前n-1个词,无法捕获长期依赖,模型效果与n的选择有关。
四、循环神经网络语言模型
RNN模型可以捕获更长时间的信息,对于语料库的单词进行one-hot编码,增加句子开始/结束标志,其主要过程为:
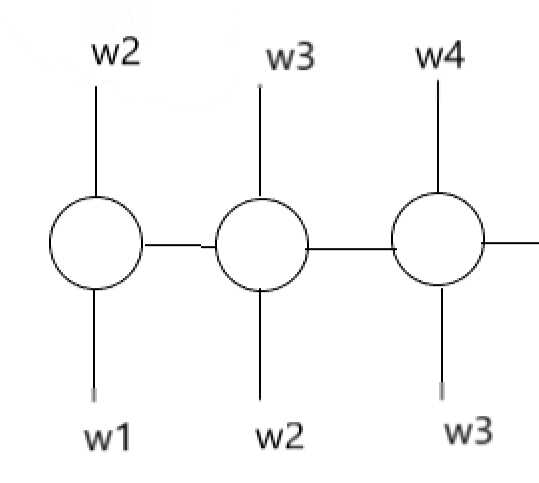
如上神经网络的输出w4即为,P(w4|w1,w2,w3),若要得到一个序列的概率,将上面输出进行连乘即可。
以上是关于语言模型的主要内容,如果未能解决你的问题,请参考以下文章