Python 文件目录比较工具filecmp和difflib
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 文件目录比较工具filecmp和difflib相关的知识,希望对你有一定的参考价值。
在一些运维场景中,常常需要比较两个环境中的应用目录结构(是否有文件/目录层面上的增删)以及比较两个环境中同名文件内容的不同(即文件层面上的改)。Python自带了两个内建模块可以很好地完成这个工作,filecmp和difflib。前者主要用于比较目录结构上的不同以及笼统的文件内容比较;后者用于比较两个文件具体内容上的不同。综合使用两个模块可以比较完备地做一次比较。
【filecmp】
filecmp提供一些方法可以很方便地进行对比两个目录在结构上的不同以及笼统的文件内容上的异同。比如
filecmp.cmp(f1,f2[,shallow]) 用于笼统地比较两个文件内容是否相同,shallow可以指定True或者False,当为True的时候这个方法会把文件的属性(os.stat方法调用看到的信息)也作为比较依据的一部分。整个方法最后返回True或者False告诉调用者两个文件的比较结果。
filecmp.cmpfiles(d1,d2,common[,shallow]) 用于比较两个目录下同名的那些文件是否都相同,common接受一个list或者tuple来表示比较哪些同名的文件。
除了上面了两个模块的静态方法之外,filecmp中还有一个dircmp类用于更加完备的比较处理工作。
dircmp类的定义是这么描述的:
dircmp(a,b,ignore=None,hide=None)
A and B are directories.
IGNORE is a list of names to ignore,
defaults to [‘RCS‘, ‘CVS‘, ‘tags‘].
HIDE is a list of names to hide,
defaults to [os.curdir, os.pardir].
在构造完一个dircmp类对象之后,可以调用下面这几个方法来输出对比的信息
d.report() 只比较当前目录的内容,不涉及当前目录下子目录中内容是否相同。输出的结果是类似于下面这样的样子:
diff testdir1 testdir2
Only in testdir1 : [‘subdir1‘]
Only in testdir2 : [‘subdir2‘]
Identical files : [‘same.txt‘]
Differing files : [‘file.txt‘]
上面的结果中涉及到了只在目录A中、只在目录B中以及同名内容一致(identical)和同名内容不同(differing)四种类别的结果。其实除此之外还有可能得到同名子目录、因为某些问题而无法直接对比内容的文件(比如文件的内容无法hash)等结果。
d.report_partial_closure() 比较当前目录以及往下一级子目录的内容
d.report_full_closure() 递归比较当前目录下所有子目录,里面的内容。返回的格式化输出中,会按照各个子目录的不同分别列出对比情况。
上面的三个方法都是filecmp模块帮助我们格式化好的输出。如果需要获取第一手的比较结果,则应该调用dircmp类的一些其他属性。比如:
left_list 目录A中的子目录和文件列表,相当于os.listdir
right_list 目录B中的子目录和文件列表
left/right_only 仅存在于目录A/B中的子目录和文件
common 两目录中同名的子目录和文件
common_files 两目录中同名的子文件,内容不一定相同
common_dirs 两目录中同名的子目录,内容不一定相同
common_funny 两目录中同名的不可比较文件
same_files 两目录中同名且内容相同的子文件
diff_files 两目录中同名但内容不相同的子文件
funny_files 两目录中同名但无法比较的子文件
以上所有属性都是返回了一个List,其中是各个文件/目录的名字
需要注意的是dircmp类默认只对比当前目录层级,对于想要深入递归地对比后辈目录的话就需要采取一些手段。可以使用dircmp的subdirs这个属性
subdirs 是一个字典,字典的键是当前dircmp类对象对比的两个目录下同名的子目录(也就是说subdirs.keys()等于是common_dirs),每个键对应的值是另一dircmp对象,而这对象对比的就是两个同名子目录的下的内容了。也就是说不断地调取subdirs这个属性就可以实现递归比较了。虽然在这次应用中我没有采取用subdirs而是稍微麻烦一点采用了判断common_dirs的办法,但是两者原理是一样的。我的尝试待会儿写在下面
【difflib】
difflib深入到文件内部,不仅仅给出“文件内容不相同”级别的提示,而是具体说明了哪些地方不相同。常用于文本文件的比较。可以看出,使用difflib还是需要被对比的文件是可以被hash的。下面的说明将基于文本文件的对比来。
既然涉及到了详细的文件内容,那么就需要有一种表示给人看的,呈现文件内容对比结果的方式。字符界面上比较常见的方法,是像linux中的diff命令的结果那样。比如:
[[email protected] tmp]# cat file1 this is file1 my name is takanashi today is a little bit cold tomorrow is holiday [[email protected] tmp]# cat file2 this is file2 my name is Takanashi today is a little bit cold i wouldnt work tomorrow [[email protected] tmp]# diff file1 file2 1,2c1,2 < this is file1 < my name is takanashi --- > this is file2 > my name is Takanashi 4c4 < tomorrow is holiday --- > i wouldnt work tomorrow
关于字符提示的详细说明这里就不多提了,可以参看linux篇的介绍。这里提到主要是想说明,difflib这个模块的一些方法也是会输出这样形式的对比结果的。
difflib模块给出了一些用于比较文本的类,最简单的一种是Differ
■ Differ类
Differ类有compare方法用于直接比较两段文本,比较的结果是通过类似上面那种表现形式来呈现。比如上面的file1和file2两个文件,通过这样一个脚本来比较:
import difflib d = difflib.Differ() with open(‘file1‘,‘r‘) as file1: content1 = file1.read().splitlines() with open(‘file2‘,‘r‘) as file2: content2 = file2.read().splitlines() print ‘\\n‘.join(d.compare(content1,content2))
可以注意到,Differ类处理的对象并不是一块文本(或者说字符串)而是一个列表,列表是根据文本字符串通过\\n split出来的,这一点也适用于difflib其他一些工具类。所以说difflib其实是基于行的比较。
compare方法返回的是一个生成器,里面是各行比较的结果。运行上面代码输出是:
- this is file1
? ^
+ this is file2
? ^
- my name is takanashi
? ^
+ my name is Takanashi
? ^
today is a little bit cold
- tomorrow is holiday
+ i wouldnt work tomorrow
两文件的前两句有所不同,比较结果前有‘-‘号的表示left_only,‘+‘号表示right_only,此外对于类似的行difflib会做进一步比较找出变更的地方。在相关行下方额外添加一行?开头的行,这行中的^号标识出变更发生的位置。两文件第三行是相同的,所以只输出了一遍,行前空格是为了和上下行对齐。后面两行因为差别较大,被认为是各自独特的行所以没有?开头的那行了。
另外,如果是B文件中某一行比A文件中的行增加或减少了一些字符,那么在?开头那行里会用-和+来表示增减字符是哪些。比如:
- this a file12 ? - + this is a file2 ? +++
■ unified_diff方法
上面说Differ类会把相同的行打印一次。如果两文件相同部分很多,只有一点不同,那么把相同的行都显示出来,即使只打印一遍也还是有点不好的。而difflib.unified_diff方法可以解决这一个问题。
unified_diff方法接受n这个参数表名只显示发现不同处上下各n行的内容。相似的方法还有context_diff。不太用所以不详细展开了
■ SequenceMatcher类
这个类首先可以用于指定忽略一些字符的比较。在其构造方法中指定第一个参数是函数对象。这个函数接受一个字符并且经过一定判断后返回True或False。根据这个返回结果类将判断要不要把这个字符计入比较结果。比如s = SequenceMatcher(lambda x : x == ‘ ‘,‘some string A‘,‘ some string B‘)。
上面这个s可以调用方法s.find_longest_match(ab,ae,bb,be)。这个方法返回的是元组(i,j,k),表示上面比较的字符串A,B中A[ab:ae]与B[bb:be]两部分中可以找到最长公共部分A[i:i+k]和B[j:j+k]。
这个类另一个NB的地方在于不仅仅可以对比字符串,而可以对比任何序列。比如两个列表的对比,也可以通过它来实现。此时构造方法的第一个参数那个函数对象,接受的就不是一个字符而是一个序列中的元素了。
■ htmlDiff类
这个类是我用的,它在Differ类的基础上将原先字符界面的结果呈现改成了更加友好的html界面显示。一目了然
构造方法:__init__(tabsize=8, wrapcolumn=None, linejunk=None, charjunk=IS_CHARACTER_JUNK)
tabsize是在html中显示的制表符的空格数量,默认是8但是我觉得太大了,改成2或者4更好看一些。wrapcolumn指定界面上的比较栏中文字最大宽度,超过此宽度会自动换行。默认是None也就是不换行,在碰到有很长的行的时候,页面宽度就会很大。linejunk和charjunk就是和ndiff方法中的相关参数差不多的,两个都是函数对象,用于指出怎么样的行或者怎么样的字符不计入比较。
HtmlDiff类主要用两个方法,make_table和make_file,两者参数类似,只不过前者返回的是可以组成一个独立html文件的html代码(带<html><head>等标签),而后者是生成一个html表格的代码(从<table>开始)。以make_file为例,其参数是make_file(fromlines, tolines [, fromdesc][, todesc][, context][, numlines])。fromlines和tolines是承载比较内容的两个列表,如上面所说,不是字符串是字符串经过‘\\n‘split过的列表。然后fromdesc和todesc用于指定生成的html中对比栏目中抬头的文字。context参数默认是False,如果设置为True,那么html中只会显示有变化的行上线numlines行数的内容,大部分相同的内容就不重复显示了。
讲了半天,下面是我对HtmlDiff类的一个使用:
def check_diff(self, index, wrapcolumn): file1, file2 = self.differing[index] with open(file1, ‘r‘) as f: content1 = f.read().splitlines() with open(file2, ‘r‘) as f: content2 = f.read().splitlines() htmlDiff = HtmlDiff(tabsize=2,wrapcolumn=wrapcolumn) with open(‘tmp.html‘, ‘w‘) as f: f.write(htmlDiff.make_file(content1, content2, fromdesc=self.dir1, todesc=self.dir2)) webbrowser.open(‘tmp.html‘)
这是部分代码,结合了webbrowser模块之后,可以把生成的HTML对比文件立刻打开,得到的HTML界面大概长这样:
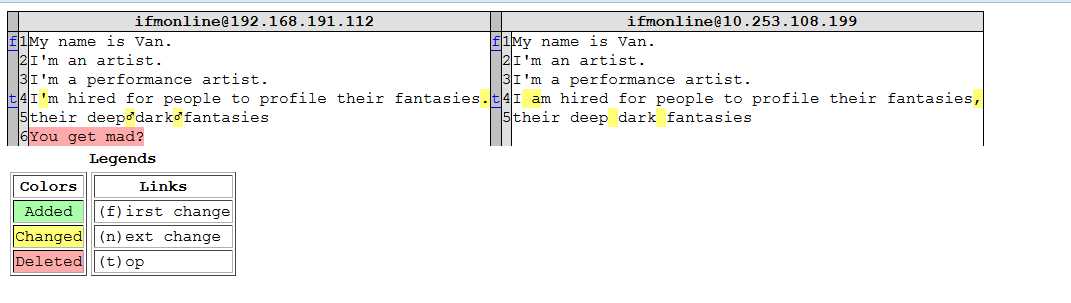
可以看到是比较友好的界面。
以上是关于Python 文件目录比较工具filecmp和difflib的主要内容,如果未能解决你的问题,请参考以下文章
filecmp (File & Directory Access) – Python 中文开发手册
python---filecmp 实现文件,目录,遍历子目录的差异对比功能。