MapReduce-shuffle过程详解
Posted enzodin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce-shuffle过程详解相关的知识,希望对你有一定的参考价值。
Shuffle
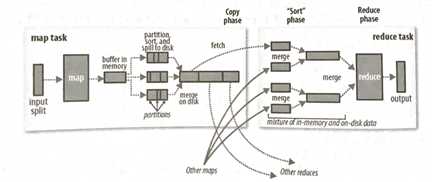
map端
map函数开始产生输出时,并不是简单地将它写到磁盘。这个过程很复杂,它利用缓冲的方式写到内存并出于效率的考虑进行预排序。
每个map任务都有一个环形内存缓冲区用于存储任务输出。在默认情况下,缓冲区的大小为100MB,辞职可以通过io.sort.mb属性来调整。一旦缓冲内容达到阈值(io.sort.spill.percent,默认是0.8),一个后台线程便开始把内容溢出(spill)到磁盘。在溢出写到磁盘过程中,map输出继续写到缓冲区,但如果在此期间缓冲区被填满,map会被阻塞知道写磁盘过程完成。
溢出写过程按轮询方式将缓冲区中的内容写到mapred.local.dir属性指定的作业特定子目录中的目录中。
在写磁盘之前,线程首先根据数据最终要传的reducer把数据划分成相应的分区(partition).在每个分区中,后台线程按键进行内排序,如果有一个combiner,它就在排序后的输出上运行。运行combiner使得map输出结果更紧凑,因此减少写到磁盘的数据和传递给reducer的数据。
每次内存缓冲区达到溢出阈值,就会新建一个溢出文件(spill file),因此在map任务写完其最后一个输出记录之后,会有几个溢出文件。在任务完成之前,溢出文件被合并成一个已分区且已排序的输出文件。配置属性io.sort.factor控制着一次最多能合并多少流,默认值是10.
如果至少存在3个溢出文件(通过min.num.spills.for.combine属性设置)时,则combiner就会在输出文件写到磁盘之前再次运行。Combiner可以在输入上反复运行,但并不影响最终结果。如果只有一两个溢出文件,那么对map输出的减少方面不值得调用combiner,不会为该map输出再次运行combiner。
在将压缩map输出写到磁盘的过程中对它进行压缩是个不错的主意,因为这样写磁盘的速度更快,节约磁盘空间,并且减少传给reducer的数据量。在默认情况下,输出是不压缩的,但只要将mapred.compress.map.output设置为true,就可以轻松启用此功能。使用的压缩库由mapred.map.output.compression.codec指定
reducer通过HTTP方式得到输出文件的分区。用于文件分区的工作线程的数量由任务的tracker.http.threads属性控制,此设置针对的是每一个tasktracker,而不是针对每个map任务槽。默认值是40,在运行大型作业的大型集群上,辞职可以根据需要而增加。在MapReduce2中,该属性是不适用的,因为使用的最大线程数是基于机器的处理器数量自动设定的。MapReduce2使用netty,默认情况下允许值为处理器数量的两倍。
reduce端
map输出文件位于运行map任务的tasktracker的本地磁盘(注意,尽管map输出经常写到map tasktracker的本地磁盘,但reduce输出并不这样),现在tasktracker需要为分区文件运行reduce任务。而且,reduce任务需要集群上若干个map任务的map输出作为其特殊的分区文件。每个map任务的完成时间可能不同,因此只要有一个任务完成,reduce任务就开始复制其输出。这就是reduce任务的复制阶段。Reduce任务有少量复制线程,因此能够并行取得map输出。默认是5个线程,但这个默认值可以通过设置mapred.reduce.parallel.copies属性来改变。
Reduce如果知道要从哪台几区取得map输出?
Map任务成功完成后,它们会通知其父tasktracker状态已更新,然后tasktracker今儿通知jobtracker.(在MapReduce2中,任务直接通知其应用程序master。)这些通知在心跳通信机制中传输。因此,对于指定作业,jobtracker(或应用程序master)知道map输出和tasktracker之间的映射关系。Reducer中的一个线程定期询问jobtracker以便获取map输出的位置,知道获得所有输出位置。
由于第一个reducer可能失败,因此tasktracker并没有在第一个reducer检索到map输出时就立即从磁盘上删除它们。相反,tasktracker会等待,直到jobtracker告知它删除map输出,这是作业完成后执行的。
如果map输出相对小,会被复制到reduce任务JVM的内存(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,指定用于此用途的堆空间的百分比),否则,map输出被复制到磁盘。一旦内存缓冲区达到阈值大小(由mapred.job.shuffle.merge.percent决定)或达到map输出阈值(mapred.inmem.merge.threshold控制),则合并后溢出写到磁盘中。如果指定combiner,则在合并期间运行它以降低写入硬盘的数据量。
随着磁盘上复本增多,后台线程会将它们合并为更大的,排好序的文件。这会为后面的合并节省一些时间。注意,为了合并,压缩的map输出(通过map任务)都必须在内存中被解压缩。
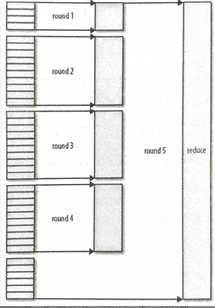
复制完所有map输出后,reduce任务进入排序阶段(更恰当的说法是合并阶段,因为排序是在map端进行的),这个阶段将合并map输出,维持其顺序排序。这是循环进行的。比如,如果有50个map输出,而合并因子是10(默认是10,由io.sort.factor属性设置,与map的合并类似),合并将进行5此,每次将10个文件合并成一个文件,因此最后有5个中间文件。
在最后阶段,即reduce阶段,直接把数据输入reduce函数,从而省略了一次磁盘往返进程,并没有将这5个文件合并成一个已排序的文件作为最后一趟。最后的合并可以来自内存和磁盘片段。
在reduce阶段,对已排序输出中的每个键调用reduce函数。此阶段的输出直接写到输出文件系统,一般为HDFS。如果采用HDFS,由于tasktracker节点(或节点管理器)也运行数据节点,所以第一块复本将被写到本地磁盘。
每次合并的文件数实际上比举例中的有所不同。目标是合并最小数量的文件以便满足最后一次的合并系数。因此,如果有40个文件,并不会在四次合并中每次合并10个文件而得到4个文件。相反,第一次只合并4个文件,随后的三次合并所有10个文件。在最后一次合并中,4个已合并的文件和余下的6个(未合并的)文件合计10个文件。
注意,这并没有改变合并次数,只是一个优化措施,目的是尽量减少写到磁盘的数据量,因为最后一次总是直接合并到reduce
以上是关于MapReduce-shuffle过程详解的主要内容,如果未能解决你的问题,请参考以下文章