xpath的基本使用
Posted yinjiangchong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了xpath的基本使用相关的知识,希望对你有一定的参考价值。
xpath和lxml类库
1. 为什么要学习xpath和lxml
lxml是一款高性能的 Python html/XML 解析器,我们可以利用XPath,来快速的定位特定元素以及获取节点信息
2. 什么是xpath
XPath (XML Path Language) 是一门在 HTMLXML 文档中查找信息的语言,可用来在 HTMLXML 文档中对元素和属性进行遍历。
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
3. 认识xml
3.1 html和xml的区别

3.2 xml的树结构
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
4. xpath的节点关系
4.1 xpath中的节点是什么
每个XML的标签我们都称之为节点,其中最顶层的节点称为根节点。
4.2 xpath中节点的关系

5. xpath中节点选择的工具
- Chrome插件 XPath Helper
- 下载地址:https://pan.baidu.com/s/1UM94dcwgus4SgECuoJ-Jcg 密码:337b
- Firefox插件 XPath Checker
注意: 这些工具是用来学习xpath语法的,他们都是从elements中匹配数据,elements中的数据和url地址对应的响应不相同,所以在代码中,不建议使用这些工具进行数据的提取.
6. xpath语法
6.1 选取节点
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
使用chrome插件选择标签时候,选中时,选中的标签会添加属性class="xh-highlight"

实例
在下面的表格中,我已列出了一些路径表达式以及表达式的结果

下来我们听过豆瓣电影top250的页面来练习上述语法:https://movie.douban.com/top250
- 选择所有的h1下的文本
//h1/text()
- 获取所有的a标签的href
//a/@href
- 获取html下的head下的title的文本
/html/head/title/text()
- 获取html下的head下的link标签的href
/html/head/link/@href
6.2 查找特定的节点
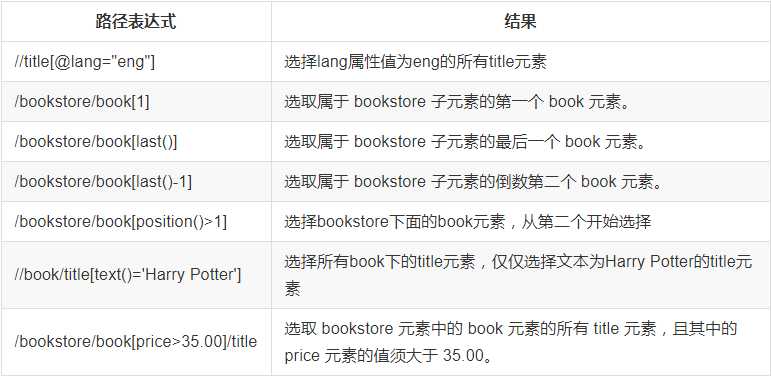
注意点: 在xpath中,第一个元素的位置是1,最后一个元素的位置是last(),倒数第二个是last()-1
6.3 选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
* 匹配任何元素节点
@* 匹配任何属性节点
node() 匹配任何类型的节点
实例
/bookstore/* 选取 bookstore 元素的所有子元素。
//* 选取文档中所有的元素
//title[@*] 选取带有属性的title元素
6.4 选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
//book/title | //book/price 选取 book 元素的所有 title 和 price 元素。
//title | //price 选取所有的title或者price元素
/bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。
lxml模块的学习
1. lxml的认识
在前面学习了xpath的语法,那么在代码中我们如何使用xpath呢,对应的我们需要lxml
安装方式:pip install lxml
2. lxml的使用
2.1 lxml模块的入门使用
-
导入lxml 的 etree 库 (导入没有提示不代表不能用)
`from lxml import etree` -
利用etree.HTML,将字符串转化为Element对象,Element对象具有xpath的方法,返回结果的列表,能够接受bytes类型的数据和str类型的数据
html = etree.HTML(text) ret_list = html.xpath("xpath字符串") -
把转化后的element对象转化为字符串,返回bytes类型结果
etree.tostring(element)
假设我们现有如下的html字符换,尝试对他进行操作
<div> <ul>
<li class="item-1"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签
</ul> </div>
from lxml import etree
text = ‘‘‘ <div> <ul>
<li class="item-1"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul> </div> ‘‘‘
html = etree.HTML(text)
print(type(html))
handeled_html_str = etree.tostring(html).decode()
print(handeled_html_str)
输出为
<class ‘lxml.etree._Element‘>
<html><body><div> <ul>
<li class="item-1"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul> </div> </body></html>
可以发现,lxml确实能够把确实的标签补充完成,但是请注意lxml是人写的,很多时候由于网页不够规范,或者是lxml的bug,即使参考url地址对应的响应去提取数据,仍然获取不到,这个时候我们需要使用etree.tostring的方法,观察etree到底把html转化成了什么样子,即根据转化后的html字符串去进行数据的提取。
2.2 lxml的深入练习
接下来我们继续操作,假设每个class为item-1的li标签是1条新闻数据,如何把这条新闻数据组成一个字典
from lxml import etree
text = ‘‘‘ <div> <ul>
<li class="item-1"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul> </div> ‘‘‘
html = etree.HTML(text)
#获取href的列表和title的列表
href_list = html.xpath("//li[@class=‘item-1‘]/a/@href")
title_list = html.xpath("//li[@class=‘item-1‘]/a/text()")
#组装成字典
for href in href_list:
item = {}
item["href"] = href
item["title"] = title_list[href_list.index(href)]
print(item)
输出为:
{‘href‘: ‘link1.html‘, ‘title‘: ‘first item‘} {‘href‘: ‘link2.html‘, ‘title‘: ‘second item‘} {‘href‘: ‘link4.html‘, ‘title‘: ‘fourth item‘}
2.3 lxml模块的进阶使用
前面我们取到属性,或者是文本的时候,返回字符串
但是如果我们取到的是一个节点,返回的是element对象,可以继续使用xpath方法,对此我们可以在后面的数据提取过程中:先根据某个标签进行分组,分组之后再进行数据的提取
from lxml import etree
text = ‘‘‘ <div> <ul>
<li class="item-1"><a>first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul> </div> ‘‘‘
html = etree.HTML(text)
li_list = html.xpath("//li[@class=‘item-1‘]")
print(li_list)
可以发现结果是一个element对象,这个对象能够继续使用xpath方法,先根据li标签进行分组,之后再进行数据的提取.
from lxml import etree
text = ‘‘‘ <div> <ul>
<li class="item-1"><a>first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul> </div> ‘‘‘
#根据li标签进行分组
html = etree.HTML(text)
li_list = html.xpath("//li[@class=‘item-1‘]")
#在每一组中继续进行数据的提取
for li in li_list:
item = {}
item["href"] = li.xpath("./a/@href")[0] if len(li.xpath("./a/@href"))>0 else None
item["title"] = li.xpath("./a/text()")[0] if len(li.xpath("./a/text()"))>0 else None
print(item)
以上提取数据的方式:先分组再提取,都会是我们进行数据的提取的主要方法.
3. 动手
用XPath来做一个简单的爬虫,爬取某个贴吧里的所有帖子,获取每个帖子的标题,连接和帖子中图片
思路分析:
-
推荐使用极速版的页面,响应不包含js,elements和url地址对应的响应一样
-
获取所有的列表页的数据即连接和标题
2.1. 确定url地址,确定程序停止的条件
url地址的数量不固定,不能够去构造url列表,需要手动获取下一页的url地址进行翻页.
2.2. 确定列表页数据的位置
由于没有js,可以直接从elements中进行数据的提取.
-
获取帖子中的所有数据
3.1 确定url地址url详情页的规律和列表页相似.
3.2 确定数据的位置
代码如下:
# coding=utf-8
import requests
from lxml import etree
class TieBaSpider:
def __init__(self,tieba_name):
#1. start_url
self.start_url= "http://tieba.baidu.com/mo/q---C9E0BC1BC80AA0A7CE472600CDE9E9E3%3AFG%3D1-sz%40320_240%2C-1-3-0--2--wapp_1525330549279_782/m?kw={}&lp=6024".format(tieba_name)
self.headers = {"User-Agent": "Mozilla/5.0 (Linux; android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36"}
self.part_url = "http://tieba.baidu.com/mo/q---C9E0BC1BC80AA0A7CE472600CDE9E9E3%3AFG%3D1-sz%40320_240%2C-1-3-0--2--wapp_1525330549279_782"
def parse_url(self,url): #发送请求,获取响应
print(url)
response = requests.get(url,headers=self.headers)
return response.content
def get_content_list(self,html_str): #3. 提取数据
html = etree.HTML(html_str)
div_list = html.xpath("//body/div/div[contains(@class,‘i‘)]")
content_list = []
for div in div_list:
item = {}
item["href"] = self.part_url+div.xpath("./a/@href")[0]
item["title"] = div.xpath("./a/text()")[0]
item["img_list"] = self.get_img_list(item["href"],[])
content_list.append(item)
#提取下一页的url地址
next_url = html.xpath("//a[text()=‘下一页‘]/@href")
next_url =self.part_url+ next_url[0] if len(next_url)>0 else None
return content_list,next_url
def get_img_list(self,detail_url,img_list):
#1. 发送请求,获取响应
detail_html_str = self.parse_url(detail_url)
#2. 提取数据
detail_html = etree.HTML(detail_html_str)
img_list += detail_html.xpath("//img[@class=‘BDE_Image‘]/@src")
#详情页下一页的url地址
next_url = detail_html.xpath("//a[text()=‘下一页‘]/@href")
next_url =self.part_url+ next_url[0] if len(next_url)>0 else None
if next_url is not None: #当存在详情页的下一页,请求
return self.get_img_list(next_url,img_list)
#else不用写
img_list = [requests.utils.unquote(i).split("src=")[-1] for i in img_list]
return img_list
def save_content_list(self,content_list):#保存数据
for content in content_list:
print(content)
def run(self): #实现主要逻辑
next_url = self.start_url
while next_url is not None:
#1. start_url
#2. 发送请求,获取响应
html_str = self.parse_url(next_url)
#3. 提取数据
content_list,next_url = self.get_content_list(html_str)
#4。保存
self.save_content_list(content_list)
#5.获取next_url,循环2-5
if __name__ == ‘__main__‘:
tieba = TieBaSpider("李毅")
tieba.run()
以上是关于xpath的基本使用的主要内容,如果未能解决你的问题,请参考以下文章