1.re模块
Posted wjs521
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1.re模块相关的知识,希望对你有一定的参考价值。
在python中使用正则表达式
转义符 : 在正则中的转义符也是在python中的转义符
‘(‘ 表示匹配小括号
[()+*?/$.] 在字符组中一些特殊的字符会现出原形
所有的w d s( , , ) W D S 都表示它原有的意义
[-] 只有写在字符组的首位的时候表示普通的减号
写在其他位置的时候表示范围[1-9]
如果想匹配减号[1-9] 就这样写
re模块常用的方法
findall ***** 匹配所有符合的字符串
ret = re.findall("d+‘,1994wjs521‘)
print(ret) 参数 返回值类型 : 列表 返回值个数 : 1 返回值内容 : 所有匹配上的项


search ***** 只要匹配上了就不再进行匹配
ret = re.search("d+","@$1994wjs521")
print(ret) 返回值类型 : 正则匹配结果的对象 返回值个数 : 1 如果匹配上了就返回对象 没有匹配上就返回None
print(ret.group()) 返回的对象通过group来获取匹配到的第一个结果


match ** 只要第一个字符不符合就不再继续匹配,并返回None
ret = re.match("d+","@!1994wjs521")
print(ret)
print(ret.group) 匹配不到时,用group()会报错


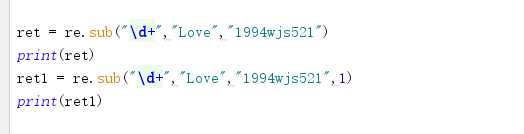
sub *** 替换 可以控制想替换的个数
ret = re.sub("d+","Love","1994wjs521"1)
print(ret)

subn *** 也是替换 也可以控制替换的次数,并且会返回替换的次数是一个元祖.
ret = re.subn("d+","Love","1994wjs521",1)
print(ret)


split *** 切割
ret = re.split("d+","1994wjs521")
print(ret)


进阶方法----爬虫自动化开发
compile ***** 时间效率 节省时间 : 只有在多次使用某一个相同的正则表达式的时候, 这个compile才会帮助我们提高程序的效率
ret = re.compile("d+") 制定了一个正则表达式
ret1 = ret.search("1994wjs521")
print(ret1.group)

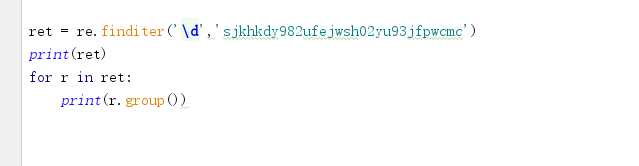
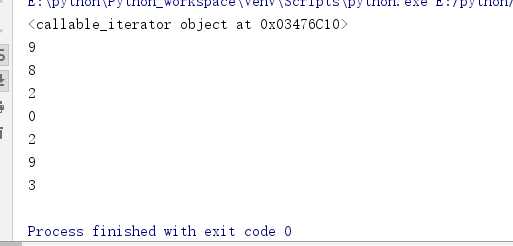
finditer ***** 空间效率
ret = re.finditer("d+","1994wjs521")
for i in ret:
print(i.group())
以上是关于1.re模块的主要内容,如果未能解决你的问题,请参考以下文章