分布式事务最终一致看这篇“大白话”的实践
Posted xuejiaming
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务最终一致看这篇“大白话”的实践相关的知识,希望对你有一定的参考价值。
我们都知道微服务现在很火热,那么我们将业务才开后随之而来的数据一致性问题也很棘手,这篇博客我将阐述一下我是如何通过实践加理论来完成最终一致的高可用并且讲述一下dotnetcore下的cap是如何实现的,话不多说直接上问题。
1我们在编写代码的时候是否有过如下经历的转变:
//原先的业务
begin tran
update table set column=x where id = y;
update table2 set column = x where id = y;
commit
//进化后的业务需要调用第三方接口通知其完成方法:OtherService.Complete()
方法1:
OtherService.Complete();
begin tran
update table set column=x where id = y;
update table2 set column = x where id = y;
commit
方法2:
begin tran
OtherService.Complete();
update table set column=x where id = y;
update table2 set column = x where id = y;
commit
方法3:
begin tran
update table set column=x where id = y;
OtherService.Complete();
update table2 set column = x where id = y;
commit
方法4:
begin tran
update table set column=x where id = y;
update table2 set column = x where id = y;
OtherService.Complete();
commit
方法5:
begin tran
update table set column=x where id = y;
update table2 set column = x where id = y;
commit
OtherService.Complete();
我们可以发现业务的进化是不可阻挠的,但是如何来确保本地事务的成功外加远程调用的成功呢,首先我们排除业务逻辑上的,就是说如果不存在网络问题那么一定是会成功的只要他执行了,那么根据aop我们会发现每个方法都会有6个切面:

谁也没法保证在哪个切面会发生网络或者断电等异常,大家可以思考一下关于上述5种方法的任何切面出现问题会有什么影响哪些切面出问题是不会有数据不一致的:
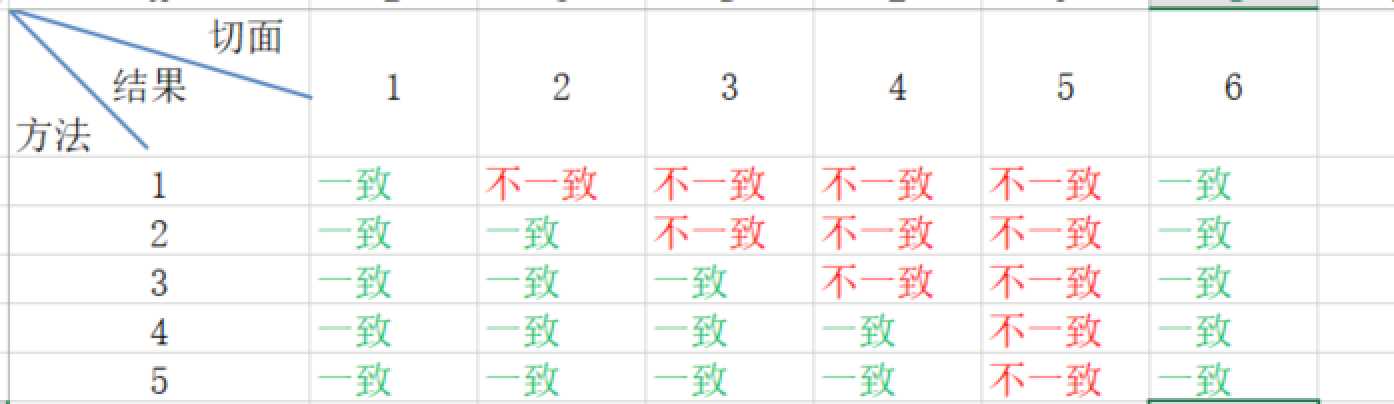
通过上面我可以看到只有4-5方法出现了一个不一致,但是方法5不排除本身调用失败,所以我们一般选择的方法4,因为在所有这么多方法中只有方法4可以称之为“伪事务”,这边可以发现只要远程调用出错那么事务会回滚可以极大的保障数据一致性,但是也不排除切面5发生错误,一旦切面5发生错误那么数据就会不一直,除非手工的去处理。有人会说了我们用mq啊,mq有特殊机制可以确定后再去除消息(rabbitmq的ack机制。)那么我们再来看下这一系列的问题。假设基于方法4的前提下将方法调用改成mq的消息机制,我们来看:
假设前面执行一切正常但是在执行ack确认完成mq清除掉消息后(channel.BasicAck(ea.DeliveryTag, false);)网络异常本地客户端没有得到正常的response那么一样等于切面4报错还是会产生消息不一致,那么说了这么多我们到底该如何才能保证消息不丢失呢。假设我们改造下mq,我先发一个消息给mq告诉他我等会会让你干什么事,如果过了多少秒我还没告诉你你来问我到底这件事还做不做了,这样我们就可以保证我们发给mq的消息不丢失,我们来看一张图
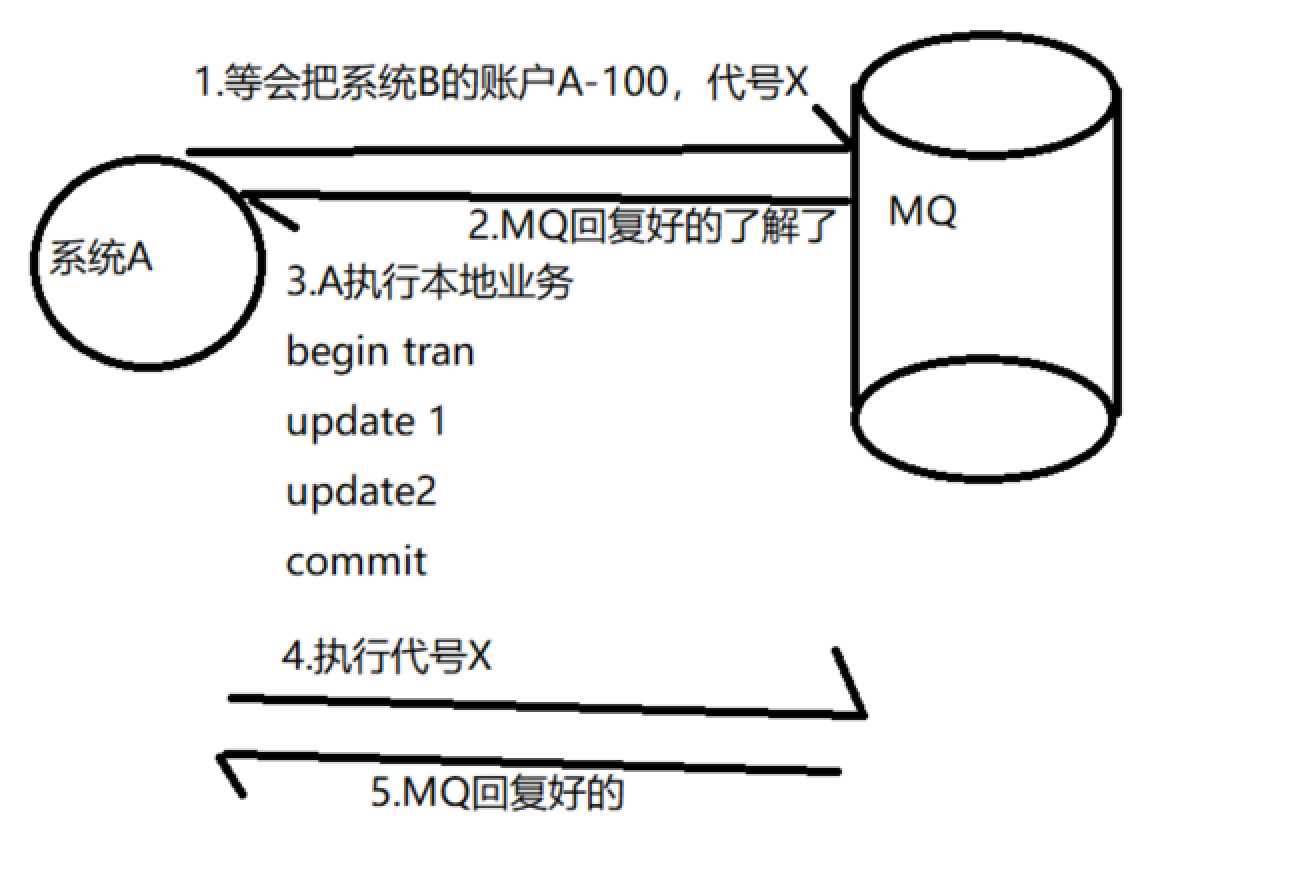
这个改进后我们发现其实还是有问题如果4-5步骤出问题了还是数据不一致,那么我们就需要再进一步改进
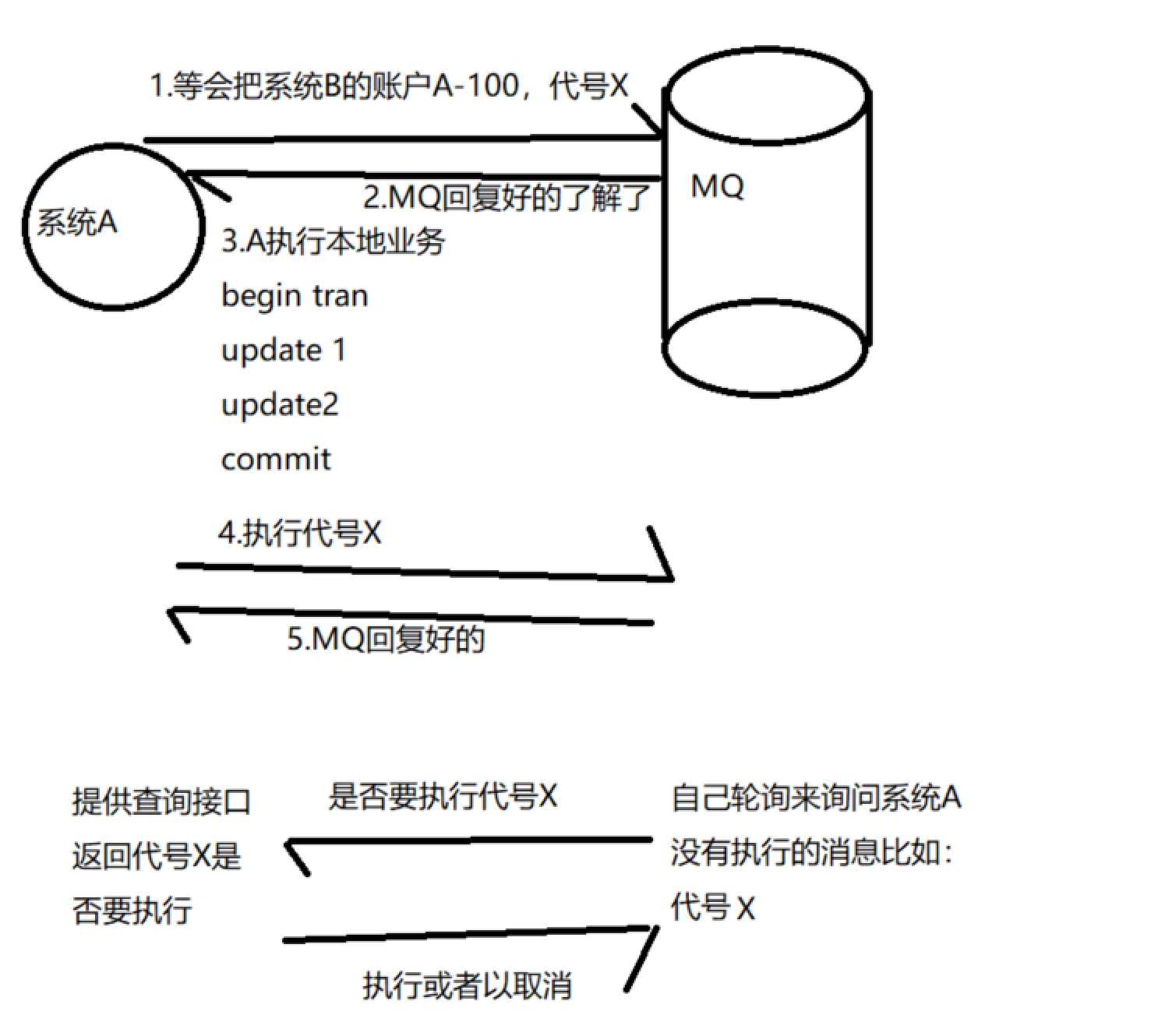
这样我们就可以保证消息准确无误的抵达系统B并且可以执行完成,但是这么做需要有一个强业务类型逻辑校验,保证除了网络等不可抗拒因素以外都要成功。但是有人要说了,就我们的水平不是人人都是bat里的怎么可能改进mq系统让他支持,改源码毕竟还是不太现实,那么接下来我就给大家带来2种解决方案,而且其中一种就是cap的实现。
方案1
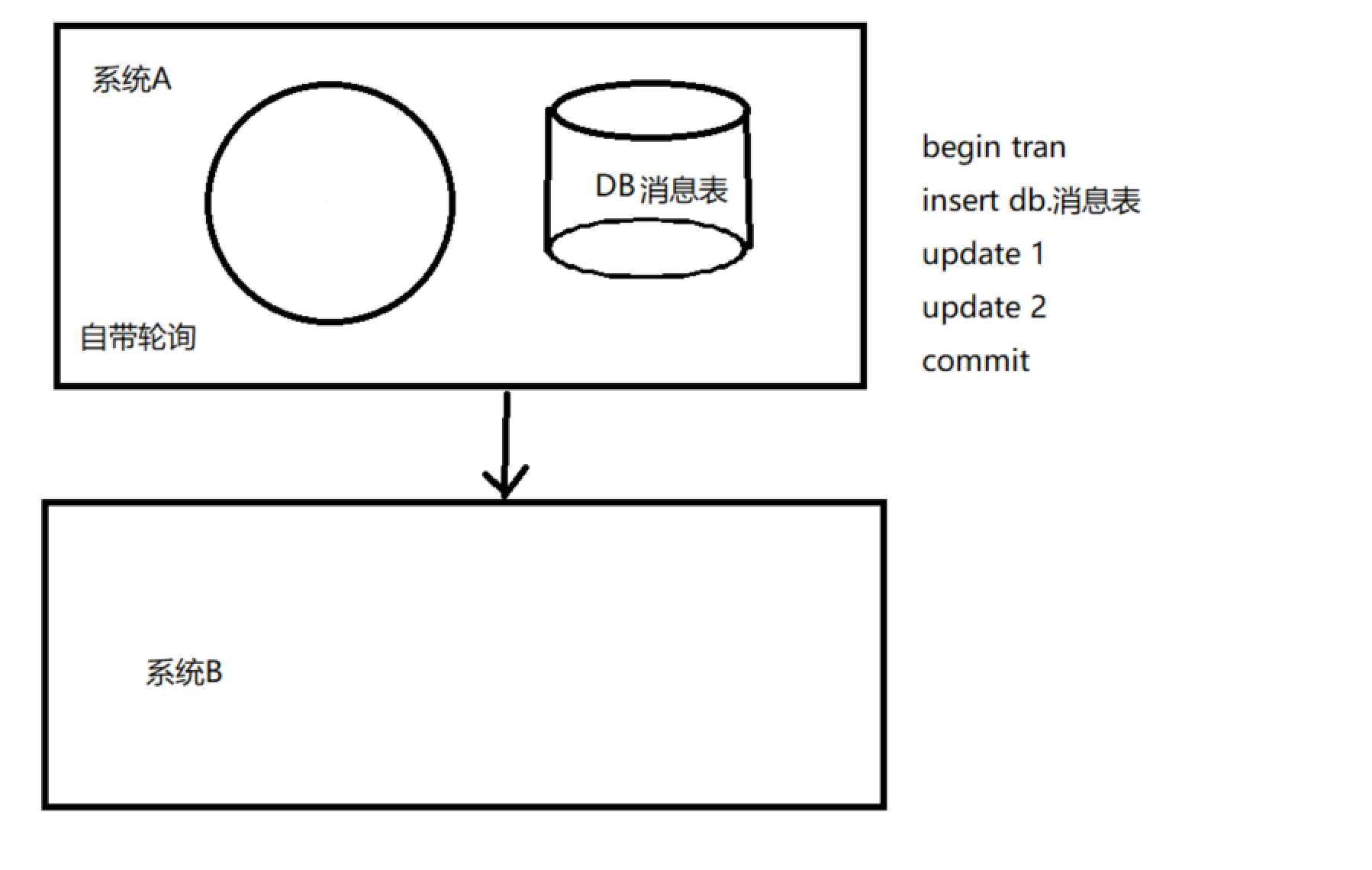
通过代码我们可以看到利用本地数据库事务特性将要对其他系统的处理消息插入本地消息表,之后再commit之后去执行并且更新消息表,自带轮询查询消息表达到数据一致,cap就是这个方式来实现的最终一致。不过这种方法需要本地存储支持事务特性,而且并发量受本地数据库性能的限制,但是特点是实现起来简单有效方便。那么第二种方案是自己实现一个独立的可靠消息中间件。
方案2:
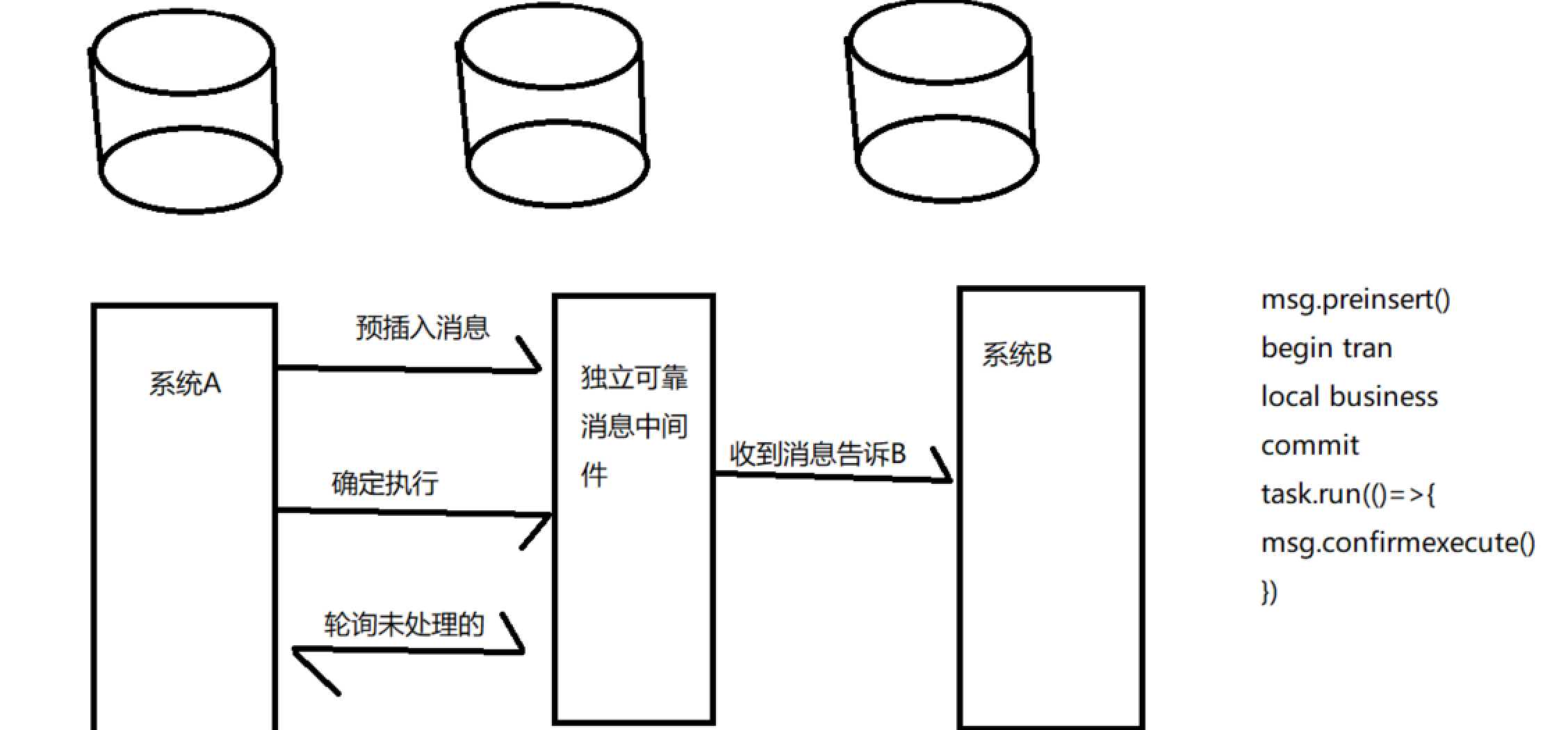
方案2这里要说的是系统a需要提供查询接口来供消息系统查询未处理的消息来确认是否要执行,系统b需要做的是提供查询接口来让消息系统来确认是否已经执行成功,因为消息系统在发消息给系统b的时候中间也会存在网络终端问题,而且这样一个消息系统就完全不存在事务的依赖关系,而且也不对原先的业务进行侵入,并发完全由消息系统自己独立控制。尤其是系统B和消息系统需要做好的是消息的重复消费要保证幂等的关系,所谓的幂等就是我同一个消息我执行一次和执行n次都只会成功一次,具体可以靠并发字段或者rowversion来保证,之后有时间我会单独写一个独立的消息中间件的demo,对了消息系统可以自身携带轮询系统,也可以有第三方的控制台程序或者其他定时程序来实现轮询
以上是关于分布式事务最终一致看这篇“大白话”的实践的主要内容,如果未能解决你的问题,请参考以下文章