[翻译] 扩张卷积 (Dilated Convolution)
Posted klchang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[翻译] 扩张卷积 (Dilated Convolution)相关的知识,希望对你有一定的参考价值。
英文原文: Dilated Convolution
简单来说,扩张卷积只是运用卷积到一个指定间隔的输入.按照这个定义,给定我们的输入是一个2维图片,扩张率 k=1 是通常的卷积,k=2 的意思是每个输入跳过一个像素,k=4 的意思是跳过 3 个像素.最好看看下面这些 k 值对应的图片.
下面的图片表示了在 2 维数据上的扩张卷积.红点表示输入到此例中的 3x3 滤波器的数据点,绿色区域表示这些输入中每一个所捕获的接收域 (receptive field). 接收域是一个在初始的输入上,通过每个输入到下一层(单元)捕获的隐含区域.

扩张卷积是一种按指数规律增加接收视角(全局视角)和线性参数增长.基于这个目的,可以在更关注具有更宽上下文和和更少代价的集成知识的应用中使用.
一个普遍的用法是在图像分割中,每个像素标记为其所属的类.在这个条件下,网络输出需要与输入图片具有相同尺寸.直接的方法是应用卷积,然后增加解卷积层(deconvolution layer)进行上采样(upsample)[1].然而,它引入更多参数进行学习.而应用扩张卷积保持高输出精度.避免了上采样的需要[2][3].
扩张卷积也应用到除视觉以外的领域.一个好例子是 WaveNet[4] 文本转语音的解决方案和 ByteNet[5] 学习文本翻译.它们都使用扩张卷积以捕获具有更少参数的输入的全局视角.
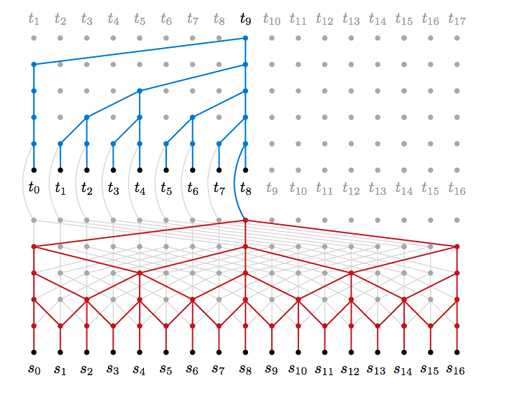
上图来自 [5]
简而言之,扩张卷积是一个简单而有效的思想.在如下两种情况下,可以考虑使用:
1. 以更高的精度处理输入,以检测好的细节;
2. 更广的输入视角以捕捉更多的上下文信息,而且具有更少的参数,更快的运行时间.
[1] Long, J., Shelhamer, E., & Darrell, T. (2014). Fully Convolutional Networks for Semantic Segmentation. Retrieved from http://arxiv.org/abs/1411.4038v1
[2] Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. (2014). Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Iclr, 1–14. Retrieved from http://arxiv.org/abs/1412.7062
[3] Yu, F., & Koltun, V. (2016). Multi-Scale Context Aggregation by Dilated Convolutions. Iclr, 1–9. http://doi.org/10.16373/j.cnki.ahr.150049
[4] Oord, A. van den, Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., ... Kavukcuoglu, K. (2016). WaveNet: A Generative Model for Raw Audio, 1–15. Retrieved from http://arxiv.org/abs/1609.03499
[5] Kalchbrenner, N., Espeholt, L., Simonyan, K., Oord, A. van den, Graves, A., & Kavukcuoglu, K. (2016). Neural Machine Translation in Linear Time. Arxiv, 1–11. Retrieved from http://arxiv.org/abs/1610.10099
以上是关于[翻译] 扩张卷积 (Dilated Convolution)的主要内容,如果未能解决你的问题,请参考以下文章