Java集合总结:Map和Set
Posted jackpn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合总结:Map和Set相关的知识,希望对你有一定的参考价值。
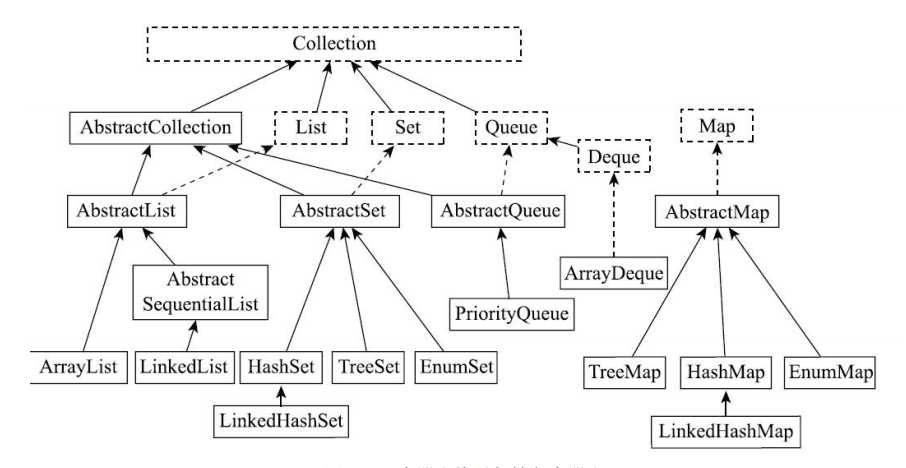
集合类的架构图:
HashMap
- 内部维护一个链表数组做哈希表,默认大小为16,最大值可以为2^30,默认负载因子0.75。
- 可以通过构造方法指定初始大小和负载因子,当键值对个数大于等于临界值threshold(数组当前大小和负载因子的乘积)时对数组进行扩容,扩容策略为当前数组大小乘以2。
- 数组的每一项都是一个链表,链表的每个结点(静态内部类Entry)都是键值对,并缓存了key的hash值。
- key 和value都可以为null,key为null时结点存储在hash表数组下标为0的位置。
put过程:
public V put(K key, V value) { if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }
- 通过key的hashcode计算出一个内部的hash值,然后用这个hash值对哈希表大小取余(算法为h & (length-1),此处可以体现hash表length扩容策略为指数方式的优势)定位到哈希表的位置,然后遍历该位置的链表,当遇到相等的key时,替换原来的value并将原来的value返回
- 如果没找着key相同的记录,就在相应位置添加新的链表结点,并将原来该位置的链表链接到此节点后,此节点作为头结点,当size大于阈值,则扩容到原来数组大小的两倍
HashMap不是线程安全的,多线程环境下可能造成死循环(对hash表扩容后transfer数据时发生)或者丢失数据(hash冲突后添加新节点到链表时发生)。
HashSet
HashSet通过内嵌一个HashMap对象的方式来实现,通过HashMap的key来存储,value都是相同的一个空Object()对象。与HashMap一样,要求需要存储的key实现hashcode和equals方法,且与HashMap具备同样的初始大小和扩容策略。
TreeMap
红黑树:一种大致平衡的二叉查找树,大致平衡是为了在保持较高检索效率的同时还不需要频繁调整,从而保持了统计上的性能。
- TreeMap内部使用了红黑树来实现,维护其根节点,每个key-value都内嵌于其中一个节点(Entry),同时Entry还具有left、right、parent以及color属性用以维持其树形结构。
- 结点之间按key有序,需要key实现comparable接口或者在构造方法中传入一个比较器comparator。
- 迭代时按key排序,保存时会使用key的比较结果对key进行排重,只要比较结果相同就会被认为是同一份,此时保存的key值为第一次put的key,value为第二次put进去的value
- 通过key get时,搜索二叉查找树,找到匹配的返回其value,找不到返回null
- 通过value获取时,遍历所有节点搜索
- TreeMap实现了SortedMap和NavigableMap接口,可以方便的根据键的顺序进行查找,如第一个、最后一个、某一范围的键、邻近键等。
- 根据键保存、查找、删除的效率比较高,为O(h),h为树的高度,在树平衡的情况下,h为log2(N),N为节点数。
- TreeSet
- 内部持有一个TreeMap,类似HashSet,没有重复元素,添加删除判断元素是否存在效率较高,为O(log2N),N为元素个数
- 有序,可以方便的根据顺序进行查找和操作,如第一个,最后一个,某一取值范围,某一值的近邻元素。
LinkedHashMap
- LinkedHashMap是HashMap的子类,内部有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于这个双向链表中。
- 双向链表的结点LinkedHashMap.Entry继承自HashMap.Entry,添加了before和after两个引用参数,同时重写了HashMap.Entry的recordAccess和recordRemoval方法以维护和hash表中节点的关系。
- LinkedHashMap支持两种顺序,一种是插入顺序,另一种是访问顺序,默认情况下按插入有序,构造方法中accessOrder设为true的时候按访问顺序,可以用来实现LRU缓存(最近最少使用)
LinkedHashSet
LinkedHashMap也有一个对应的Set接口的实现类LinkedHashSet。LinkedHashSet是HashSet的子类,但它内部的Map的实现类是LinkedHashMap,所以它也可以保持插入顺序
EnumMap
内部使用数组实现,构造方法需要传入类型信息。允许值为null,为了区分null和没有值,用一个静态全局唯一的new Integer(0)值来作为没有值
EnumSet
内部使用位向量实现,是一个抽象类,不能直接通过new关键字来新建,必须使用类似于noneOf的其他工厂方法方法创建一个指定枚举类型的set,实际创建的对象是EnumSet的子类RegularEnumSet或JumboEnumSet。
具体子类类型根据传入的枚举类型枚举值的数量来决定:
- 小于等于64返回维护一个long变量(long为64位)作为位向量的子类RegularEnumSet
- 大于64返回一个内部维护long数组作为位向量的子类JumboEnumSet
下面是一些工厂方法:
// 初始集合包括指定枚举类型的所有枚举值 <E extends Enum<E>> EnumSet<E> allOf(Class<E> elementType) // 初始集合包括枚举值中指定范围的元素 <E extends Enum<E>> EnumSet<E> range(E from, E to) // 初始集合包括指定集合的补集 <E extends Enum<E>> EnumSet<E> complementOf(EnumSet<E> s) // 初始集合包括参数中的所有元素 <E extends Enum<E>> EnumSet<E> of(E e) <E extends Enum<E>> EnumSet<E> of(E e1, E e2) <E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3) <E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3, E e4) <E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3, E e4, E e5) <E extends Enum<E>> EnumSet<E> of(E first, E... rest) // 初始集合包括参数容器中的所有元素 <E extends Enum<E>> EnumSet<E> copyOf(EnumSet<E> s) <E extends Enum<E>> EnumSet<E> copyOf(Collection<E> c)
以上是关于Java集合总结:Map和Set的主要内容,如果未能解决你的问题,请参考以下文章