算法导论——用于不相交集合的数据结构
Posted graywind
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法导论——用于不相交集合的数据结构相关的知识,希望对你有一定的参考价值。
不相交集合的操作
一些应用涉及将n个不同元素分成一组不相交的集合,常进行两种操作:寻找包含制定元素的唯一集合以及合并两个集合。操作进行以下定于:
MAKE-SET(x)建立一个新的集合,仅含有x
UNION(x,y)将包含x和y的两个集合合并成一个新的集合,删除原本的集合
FIND-SET(x)返回一个指向包含唯一x的集合的指针
无向图的连通分量就是一个例子。
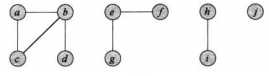
对于如图所示的4个连通分量,先对每一个单独的点建立一个单独的集合,然后依次根据每条边合并对应的集合,最后形成4个不相交的集合

1 CONNECTED-COMPONENTS(E,V){//有E[n]个顶点V[m]条边 2 for(i=0;i<n;i++) 3 MAKE-SET(V[i]); 4 for(i=0;i<m;i++){ 5 if(FIND-SET(V[i].u != FIND-SET(V[i].v)) 6 UNION(V[i].u,V[i].v); 7 } 8 }
不相交集合的链表表示
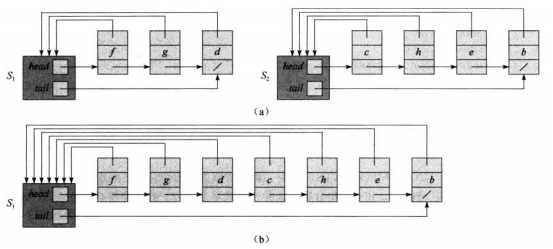
(a)所示的结构通过不相交集合各自形成一个链表,索引头部包含链表的头部和尾部,链表各个结点包含指向索引头部和下个结点两个指针。对于这种结构,MAKE-SET(x)和FIND-SET(x)都可以在O(1)的时间完成。
(b)展示了UNION(x,y)的操作,需要将另一个链表连接到一个链表的末尾,然后修改索引结点的尾部,同时被合并的链表每个结点指向的索引头部都要修改,所以该操作至少要花费O(Y)的时间
为了减少合并的时间,可以在头部额外存储每个链表的大小,这样可以将小的集合合并到大的集合中去。
不相交集合森林
使用有根树来表示集合,书中每个节点包含一个成员,一棵树代表一个集合,每个成员都指向他的父结点,根结点的父结点指向自己。
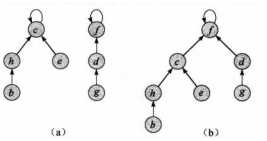
(b)是合并操作,将c的父亲改为f即可。这种不相交集合森林的结构MAKE-SET和UNION的效率很高,但FIND-SET收到树高度的影响,效率较低。因此,有两种改进的启发式算法。
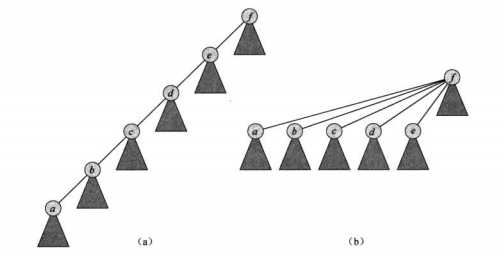
第一种是按秩合并,对于每个结点记录他的高度,将秩较小的结点的父亲改为大的那个。若两边相等,则任选一个作为父亲,根结点的秩加一。
第二种是路径压缩,每次调用FIND-SET的时候,将查找路径上的结点的父亲直接改为根结点。
1 MAKE-SET(x){ 2 x.p = x; 3 x.rank = 0; 4 } 5 6 UNION(x,y){ 7 if(x.rank > y.rank) 8 y.p = x; 9 else{ 10 x.p = y; 11 if(x.rank == y.rank) 12 y.rank++; 13 } 14 } 15 16 FIND-SET(x){ 17 if(x != x.p) 18 x.p = FIND-SET(x,p); 19 return x.p; 20 }
以上是关于算法导论——用于不相交集合的数据结构的主要内容,如果未能解决你的问题,请参考以下文章