爬虫_电影天堂 热映电影(xpath)
Posted mc-curry
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫_电影天堂 热映电影(xpath)相关的知识,希望对你有一定的参考价值。
写了一天才写了不到100行。不过总归是按自己的思路完成了
1 import requests 2 from lxml import etree 3 import time 4 5 BASE = ‘http://www.dytt8.net‘ 6 def get_one_page(url): 7 headers = {‘User-Agent‘: ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/68.0.3440.75 Safari/537.36‘} 8 try: 9 10 response = requests.get(url, headers=headers) 11 response.encoding = response.apparent_encoding 12 return response.text 13 except: 14 return 0 15 16 17 18 def parse_one_page_href(html): 19 str_hrefs = [] 20 html_element = etree.HTML(html) 21 # //div[@class="co_content8"]/ul/table//a/@href 22 hrefs = html_element.xpath(‘//table[@class="tbspan"]//a/@href‘) 23 for href in hrefs: 24 href = BASE + href 25 str_hrefs.append(href) 26 return str_hrefs 27 28 """ 29 return 30 [‘http://www.dytt8.net/html/gndy/dyzz/20180731/57193.html‘, 31 ‘http://www.dytt8.net/html/gndy/dyzz/20180730/57192.html‘, 32 ...... 33 ‘http://www.dytt8.net/html/gndy/dyzz/20180702/57064.html‘, 34 ‘http://www.dytt8.net/html/gndy/dyzz/20180630/57056.html‘] 35 """ 36 37 38 39 def get_all_pages(page_nums): 40 hrefs = [] 41 for index in range(1, page_nums + 1): 42 url = ‘http://www.dytt8.net/html/gndy/dyzz/list_23_‘ + str(index) + ‘.html‘ 43 html = get_one_page(url) 44 while html == 0: 45 time.sleep(3) 46 html = get_one_page(url) 47 hrefs.extend(parse_one_page_href(html)) 48 return hrefs 49 50 51 def get_detail(page_nums): 52 movie = [] 53 hrefs = get_all_pages(page_nums) 54 for href in hrefs: #href: every page url 55 informations = {} 56 57 response = requests.get(href) 58 response.encoding = response.apparent_encoding 59 html = response.text 60 61 html_element = etree.HTML(html) 62 63 title = html_element.xpath(‘//font[@color="#07519a"]/text()‘)[0] 64 informations[‘title‘] = title 65 66 image_src = html_element.xpath(‘//p//img/@src‘) 67 informations[‘image_src‘] = image_src[0] 68 69 download_url = html_element.xpath(‘//td[@bgcolor="#fdfddf"]/a/@href‘) 70 informations[‘download_url‘] = download_url 71 72 texts = html_element.xpath(‘//div[@id="Zoom"]//p/text()‘) 73 for index, text in enumerate(texts): 74 75 if text.startswith(‘◎片 名‘): 76 text = text.replace(‘◎片 名‘, ‘‘).strip() 77 informations[‘english_name‘] = text 78 79 elif text.startswith(‘◎产 地‘): 80 text = text.replace(‘◎产 地‘, ‘‘).strip() 81 informations[‘location‘] = text 82 83 elif text.startswith(‘◎上映日期‘): 84 text = text.replace(‘◎上映日期‘, ‘‘).strip() 85 informations[‘date‘] = text 86 87 elif text.startswith(‘◎片 长‘): 88 text = text.replace(‘◎片 长‘, ‘‘).strip() 89 informations[‘time‘] = text 90 91 elif text.startswith(‘◎导 演‘): 92 text = text.replace(‘◎导 演‘, ‘‘).strip() 93 informations[‘director‘] = text 94 95 elif text.startswith(‘◎主 演‘): 96 text = text.replace(‘◎主 演‘, ‘‘).strip() 97 actors = [] 98 actors.append(text) 99 for x in range(index+1, len(texts)): 100 actor = texts[x].strip() 101 if texts[x].startswith(‘◎简 介‘): 102 break 103 actors.append(actor) 104 informations[‘actors‘] = actors 105 106 elif text.startswith(‘◎简 介 ‘): 107 text = text.replace(‘◎简 介 ‘, ‘‘).strip() 108 intros = [] 109 # intros.append(text) 110 for x in range(index+1, len(texts)): 111 intro = texts[x].strip() 112 if texts[x].startswith(‘◎获奖情况‘): 113 break 114 intros.append(intro) 115 informations[‘intros‘] = intros 116 movie.append(informations) 117 return movie 118 119 120 def main(): 121 page_nums = 1 #176 122 movie = get_detail(page_nums) 123 print(movie) 124 125 126 if __name__ == ‘__main__‘: 127 main()
运行结果:(选中的是一部电影, 一页中有25部电影,网站里一共有176页)
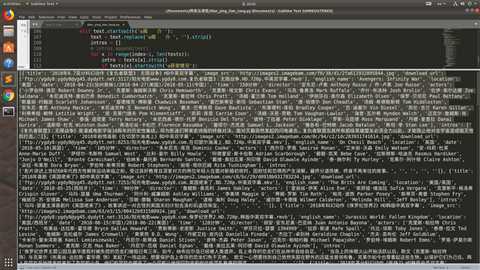
感受到了代码的魅力了吗
以上是关于爬虫_电影天堂 热映电影(xpath)的主要内容,如果未能解决你的问题,请参考以下文章