十原生爬虫实战
Posted loveapple
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十原生爬虫实战相关的知识,希望对你有一定的参考价值。
一、简单实例
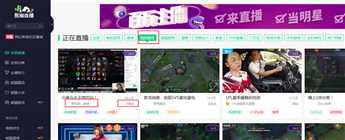
1、需求:爬取熊猫直播某类主播人气排行
2、了解网站结构
分类——英雄联盟——"观看人数"
3、找到有用的信息
二、整理爬虫常规思路
1、使用工具chrome——F12——element——箭头——定位目标元素
目标元素:主播名字,人气(观看人数)
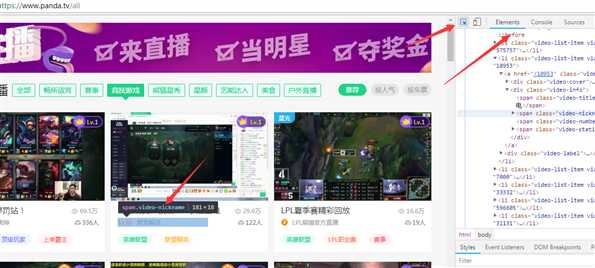
2、方法:使用正则表达式提取有用的信息
主播名字,人气(观看人数)
总结
- 爬虫前奏
1)明确目的
2)找到数据对应的网页
3)分析网页的结构找到数据所在的标签位置
- 步骤
1)模拟HTTP请求,向服务器发送这个请求,获取到服务器返回给我们的html
2)用正则表达式提取我们要的数据(名字,人气)
三、HTML结构分析基本原则
1、爬虫分析,最重要的一步,找到标签(即左右边界)
原则:
1)尽量选择有唯一标识性的标签
2)尽量选择离目标信息最近的标签
不同人选择的标签可能不同。
四、数据提取层级及原则
1、找到最近的定位标签(肉眼可见)
有关联的信息作为一组,找离这一组最近的定位标签
如:示例中的“主播姓名”和“人数”是有关联的,作为一组
2、判断选择的标签是否是唯一的(需代码验证)
3、尽量选择可闭合的定位标签
可闭合,是指可将目标信息包裹起来的定位标签。如:<... />
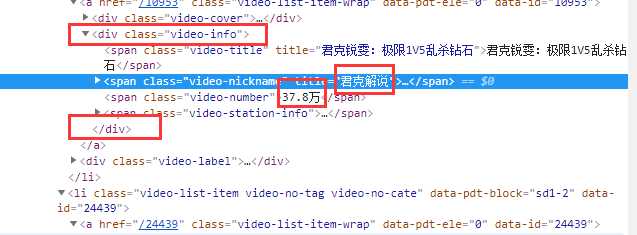

4、代码实战
1 # coding=utf-8
2 import re
3 from urllib import request
4
5 url = ‘https://www.panda.tv/all‘
6 r = request.urlopen(url)
7 htmls = r.read()
8
9 print(type(htmls)) # 打印type,结果是bytes类型
10 htmls = str(htmls, encoding=‘utf-8‘) # 将bytes转成utf-8
11 print(htmls)
运行结果
Traceback (most recent call last):
File "E:/pyClass/thirtheen/spider.py", line 12, in <module>
print(htmls)
UnicodeEncodeError: ‘gbk‘ codec can‘t encode character ‘xa0‘ in position 62321: illegal multibyte sequence
原因是使用的print()是win7系统的编码,但是win7系统的默认编码是GBK,解决方式,增加如下代码
1 import io
2 import sys
3 sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘)
优化后代码
# coding=utf-8 import re from urllib import request import io import sys sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘) class Spider(): url = ‘https://www.panda.tv/all‘ def __fetch_content(self): r = request.urlopen(Spider.url) htmls = r.read() htmls = str(htmls, encoding=‘utf-8‘) # 将bytes转成utf-8 print(htmls) return htmls def go(self): self.__fetch_content() spider=Spider() spider.go()
五、正则分析HTML
1、获取root_html
正则表达式匹配<div class="video-info">和</div>之间的所有字符,有哪些方式?

匹配所有字符的方式
1)[sS]*?
2)[wW]*?
* 表示任意次
?表示贪婪
2、代码实战
以上是关于十原生爬虫实战的主要内容,如果未能解决你的问题,请参考以下文章