noip2011 总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了noip2011 总结相关的知识,希望对你有一定的参考价值。
铺地毯
题目描述
为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形地毯。一共有 n 张地毯,编号从 1 到n 。现在将这些地毯按照编号从小到大的顺序平行于坐标轴先后铺设,后铺的地毯覆盖在前面已经铺好的地毯之上。
地毯铺设完成后,组织者想知道覆盖地面某个点的最上面的那张地毯的编号。注意:在矩形地毯边界和四个顶点上的点也算被地毯覆盖。
输入输出格式
输入格式:
输入文件名为carpet.in 。
输入共n+2 行。
第一行,一个整数n ,表示总共有 n 张地毯。
接下来的n 行中,第 i+1 行表示编号i 的地毯的信息,包含四个正整数 a ,b ,g ,k ,每两个整数之间用一个空格隔开,分别表示铺设地毯的左下角的坐标(a ,b )以及地毯在x轴和y 轴方向的长度。
第n+2 行包含两个正整数 x 和y,表示所求的地面的点的坐标(x ,y)。
输出格式:
输出文件名为carpet.out 。
输出共1 行,一个整数,表示所求的地毯的编号;若此处没有被地毯覆盖则输出-1 。
输入输出样例
输入样例#1:
3
1 0 2 3
0 2 3 3
2 1 3 3
2 2
输出样例#1:
3
输入样例#2:
3
1 0 2 3
0 2 3 3
2 1 3 3
4 5
输出样例#2:
-1
说明
【样例解释1】
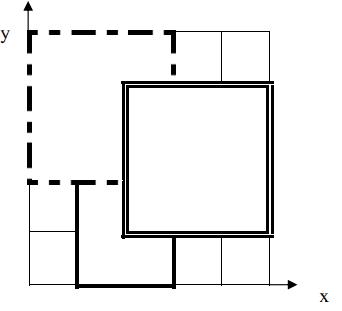
如下图,1 号地毯用实线表示,2 号地毯用虚线表示,3 号用双实线表示,覆盖点(2,2)的最上面一张地毯是 3 号地毯。
【数据范围】
对于30% 的数据,有 n ≤2 ;
对于50% 的数据,0 ≤a, b, g, k≤100;
对于100%的数据,有 0 ≤n ≤10,000 ,0≤a, b, g, k ≤100,000。
思路
先把所有的地毯离线,然后读入所求位置之后将地毯倒着来,当前地毯覆盖目标点,输出即可
代码
#include<cstdio>
#include<cmath>
#include<cstring>
#include<algorithm>
using namespace std;
int n,a[11000],b[11000],g[11000],k[11000],x,y;
int main(){
scanf("%d",&n);
for (int i = 1;i <= n;i++){
scanf("%d%d%d%d",&a[i],&b[i],&g[i],&k[i]);
}
scanf("%d%d",&x,&y);
for (int i = n;i >= 1;i--){
int you = a[i] + g[i];
int shang = b[i] + k[i];
if (x >= a[i] && y >= b[i] && x <= you && y <= shang)
{
printf("%d\\n",i);
return 0;
}
}
printf("-1\\n");
return 0;
}
#
思路
首先弄懂样例,然后从简单数据入手找规律。
(ax+by)^2=(ax)^2+2abxy+(by)^2
(ax+by)^3=(ax)^3+3(a^2)b(x^2)y+3a(b^2)x(y^2)+(by)^3
(ax+by)^4=(ax)^4+4(a^3)b(x^3)y+6(a^2)(b^2)(x^2)(y^2)+4a(b^3)x(y^3)+(by)^3
(ax+by)^5=……
通过这几个简单的公式可以得出(x^n)(y^m)的系数为t(a^n)*(b^m),t值如下所示:
1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
.........
其实就是杨辉三角(当然也是所有的组合情况C(k,n))
若f[i,j]表示(a*x+b*y)^i展开后的系数
(a^n)*(b^m)的系数为f[i,i-n+1]
又
f[i,j]:=f[i-1,j-1]+f[i-1,j];
结果: ans=f[k,k-n+1](a^n)(b^m)
由于题目要求输出对10007 取模后的结果,则有:
f[i,j]:=((f[i-1,j-1] mod 10007)+(f[i-1,j]mod 10007))mod 10007;
a^n = ((a^(N-1))mod 10007a)mod 10007
b^m = ((b^(m-1))mod 10007b)mod 10007
(a^n可以边乘边取余数的方法做,也可用快速幂)。
注意:边界条件k=0,k=n等。
代码
#include<iostream>
#include<cstdio>
#define MAXN 1000+10
#define LL long long
using namespace std;
LL aa[MAXN][MAXN];
LL a,b,k,n,m;
LL ans;
void ready()
{
for(int i=1;i<=k+1;i++)
{
for(int j=1;j<=i;j++)
{
if(j==1||i==j)
{
aa[i][j]=1;
continue;
}
aa[i][j]=(aa[i-1][j]+aa[i-1][j-1])%10007;
}
}
}
void readdata()
{
scanf("%lld%lld%lld%lld%lld\\n",&a,&b,&k,&n,&m);
}
int main()
{
readdata();
ready();
int cja=1;
for(int i=1;i<=n;i++)
cja=(cja%10007)*(a%10007)%10007;
int cjb=1;
for(int i=1;i<=m;i++)
cjb=(cjb%10007)*(b%10007)%10007;
ans=(cjb*cja)%10007;
ans=(ans*aa[k+1][n+1])%10007;
printf("%d\\n",ans);
}
选择客栈
题目描述
丽江河边有n 家很有特色的客栈,客栈按照其位置顺序从 1 到n 编号。每家客栈都按照某一种色调进行装饰(总共 k 种,用整数 0 ~ k-1 表示),且每家客栈都设有一家咖啡店,每家咖啡店均有各自的最低消费。
两位游客一起去丽江旅游,他们喜欢相同的色调,又想尝试两个不同的客栈,因此决定分别住在色调相同的两家客栈中。晚上,他们打算选择一家咖啡店喝咖啡,要求咖啡店位于两人住的两家客栈之间(包括他们住的客栈),且咖啡店的最低消费不超过 p 。
他们想知道总共有多少种选择住宿的方案,保证晚上可以找到一家最低消费不超过 p元的咖啡店小聚。
输入输出格式
输入格式:
输入文件hotel.in,共n+1 行。
第一行三个整数n ,k ,p,每两个整数之间用一个空格隔开,分别表示客栈的个数,色调的数目和能接受的最低消费的最高值;
接下来的n 行,第 i+1 行两个整数,之间用一个空格隔开,分别表示 i 号客栈的装饰色调和i 号客栈的咖啡店的最低消费。
输出格式:
输出文件名为hotel.out。
输出只有一行,一个整数,表示可选的住宿方案的总数。
输入输出样例
输入样例#1:
5 2 3
0 5
1 3
0 2
1 4
1 5
输出样例#1:
3
说明
【输入输出样例说明】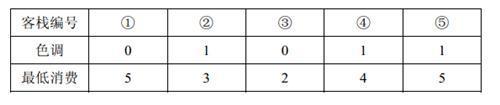
- 2 人要住同样色调的客栈,所有可选的住宿方案包括:住客栈①③,②④,②⑤,④⑤
- 但是若选择住4 、5 号客栈的话,4 、5 号客栈之间的咖啡店的最低消费是4 ,而两人能承受的最低消费是3 元,所以不满足要求。因此只有前 3 种方案可选。
【数据范围】
对于30% 的数据,有 n ≤100;
对于50% 的数据,有 n ≤1,000;
对于100%的数据,有 2 ≤n ≤200,000,0<k ≤50,0≤p ≤100 , 0 ≤最低消费≤100。思路
首先我们看,
- 当找到一个旅店在右边,若是其左边有一个符合要求的咖啡店,那么再往左边看,
- 如果有一个颜色相同的旅店,那么就算是一种住宿方法了,那么如果以这个右边的旅店作为对应点,将所有在左边而且颜色与之相同的旅店数相加,就能得出很多种住宿方法了。
- 那么用这个办法,用所有的对应点对应过去,就能最快的时间内找出所用的酒店了。a数组是记录同一种颜色中的酒店所出现的最后一次的位置;b数组记录同一种颜色的酒店的出现次数,而c数组则是临时记录当前同样颜色的酒店出现的次数,也就是为找对应点而进行的临时记录
代码
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
int n,k,p,m,ans;
int a[200010],b[200010],c[200010];
int main()
{
scanf("%d%d%d",&n,&k,&p);
for (int i = 1; i <= n; i++)
{
int k, q;
scanf("%d%d",&k,&q);
if (q <= p) m = i; //如果咖啡店的最低消费地于标准,那么记录其位置
if (m >= a[k]) c[k] = b[k]; //如果在当前颜色的酒店之前有出现过同样颜色的酒店那么记录当前同种颜色的酒店的出现次数
a[k] = i; //记录同样颜色的酒店最后一次的出现位置
ans+=c[k]; //每一个酒店都可以作为对应点,所以不需要再去加上任何的判断,记录住宿的方法
b[k]++; //记录出现次数的总数
}
printf("%d",ans);
return 0;
}
聪明的质检员
题目描述 Description
小 T 是一名质量监督员,最近负责检验一批矿产的质量。这批矿产共有n 个矿石,从1到n 逐一编号,每个矿石都有自己的重量wi 以及价值vi。检验矿产的流程是:见图
若这批矿产的检验结果与所给标准值S 相差太多,就需要再去检验另一批矿产。小T不想费时间去检验另一批矿产,所以他想通过调整参数W 的值,让检验结果尽可能的靠近标准值S,即使得S-Y 的绝对值最小。请你帮忙求出这个最小值。
输入输出
输入描述 Input Description
第一行包含3个整数 n,m,S,分别表示矿石的个数、区间的个数和标准值。接下来的 n 行,每行2 个整数,中间用空格隔开,第i+1 行表示i 号矿石的重量wi 和价值vi 。接下来的 m 行,表示区间,每行2 个整数,中间用空格隔开,第i+n+1 行表示区间[Li,Ri]的两个端点Li 和Ri。注意:不同区间可能重合或相互重叠。
输出描述 Output Description
输出只有一行,包含一个整数,表示所求的最小值。
样例输入 Sample Input
5 3 15
1 5
2 5
3 5
4 5
5 5
1 5
2 4
3 3
## 样例
样例输出 Sample Output
10
数据范围及提示 Data Size & Hint
解释
当 W 选4 的时候,三个区间上检验值分别为20、5、0,这批矿产的检验结果为25,此时与标准值S 相差最小为10。
数据范围
对于 10%的数据,有1≤n,m≤10;
对于 30%的数据,有1≤n,m≤500;
对于 50%的数据,有1≤n,m≤5,000;
对于 70%的数据,有1≤n,m≤10,000;
对于 100%的数据,有1≤n,m≤200,000,0 < wi, vi≤10^6,0 < S≤10^12,1≤Li≤Ri≤n。
思路
首先,我们可以知道每一个区间的价值都是递减的:随着W的增加,满足条件的矿石数量减少,价值和减少,所以总的价值和也减少。
那么我们可以二分W(矿石最低重量),然后统计满足条件的矿石的数量、价值的前缀和。
总时间复杂度O(mlogn)
代码
#include<iostream>
#include<cstring>
#include<cstdio>
#include<cstdlib>
#include<cmath>
#include<algorithm>
#define mod 1000000007
#define ll long long
#define inf (1LL<<60)
using namespace std;
ll read()
{
ll x=0,f=1;char ch=getchar();
while(ch<‘0‘||ch>‘9‘){if(ch==‘-‘)f=-1;ch=getchar();}
while(ch>=‘0‘&&ch<=‘9‘){x=x*10+ch-‘0‘;ch=getchar();}
return x*f;
}
int n,m,mx;
ll S,ans=inf;
int l[200005],r[200005];
int w[200005],v[200005];
ll sum[200005],cnt[200005];
ll cal(int W)
{
ll tmp=0;
for(int i=1;i<=n;i++)
{
sum[i]=sum[i-1];
cnt[i]=cnt[i-1];
if(w[i]>=W)
{
sum[i]+=v[i];
cnt[i]++;
}
}
for(int i=1;i<=m;i++)
{
tmp+=(cnt[r[i]]-cnt[l[i]-1])*(sum[r[i]]-sum[l[i]-1]);
}
return tmp;
}
int main()
{
n=read();m=read();S=read();
for(int i=1;i<=n;i++)
w[i]=read(),v[i]=read();
for(int i=1;i<=n;i++)
mx=max(mx,w[i]);
for(int i=1;i<=m;i++)
l[i]=read(),r[i]=read();
int l=0,r=mx+1;
while(l<=r)
{
int mid=(l+r)>>1;
ll t=cal(mid);
ans=min(ans,abs(t-S));
if(t<S)r=mid-1;
else l=mid+1;
}
printf("%lld\\n",ans);
return 0;
}
以上是关于noip2011 总结的主要内容,如果未能解决你的问题,请参考以下文章