爬虫热身——性能相关
Posted gaosy-math
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫热身——性能相关相关的知识,希望对你有一定的参考价值。
单线程串行与多线程(进程)并行
在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢。
1. 单线程串行
# -*- coding: UTF-8 -*- import requests, time def be_async(url): print(url) res = requests.get(url) print(res) url_list = ["https://www.baidu.com", "http://github.com/"] a = time.time() # 起始时间 for url in url_list: be_async(url) b = time.time() # 结束时间 print("cost time: %s s"%(b-a))
2. 多线程
# -*- coding: UTF-8 -*- from concurrent.futures import ThreadPoolExecutor import requests import time def be_async(url): print(url) res = requests.get(url) print(res) url_list = ["https://www.baidu.com", "http://github.com/"] pool = ThreadPoolExecutor(4) a = time.time() # 起始时间 for url in url_list: pool.submit(be_async, url) pool.shutdown(wait=True) b = time.time() # 结束时间 print("cost time: %s s"%(b-a))
+回调函数


# -*- coding: UTF-8 -*- import requests, time from concurrent.futures import ThreadPoolExecutor def be_async(url): print(url) res = requests.get(url) print(res) url_list = ["https://www.baidu.com", "http://github.com/"] def callback(future): print(future.result) pool = ThreadPoolExecutor(4) a = time.time() # 起始时间 for url in url_list: r = pool.submit(be_async, url) r.add_done_callback(callback) pool.shutdown(wait=True) b = time.time() # 结束时间 print("cost time: %s s"%(b-a))
3. 多进程
# -*- coding: UTF-8 -*- from concurrent.futures import ProcessPoolExecutor import requests import time def be_async(url): print(url) res = requests.get(url) print(res) url_list = ["https://www.baidu.com", "http://github.com/"] if __name__ == ‘__main__‘: pool = ProcessPoolExecutor(4) a = time.time() # 起始时间 for url in url_list: pool.submit(be_async, url) pool.shutdown(wait=True) b = time.time() # 结束时间 print("cost time: %s s"%(b-a))
+回调函数
# -*- coding: UTF-8 -*- import requests, time from concurrent.futures import ProcessPoolExecutor def be_async(url): print(url) res = requests.get(url) print(res) url_list = ["https://www.baidu.com", "http://github.com/"] def callback(future): print(future.result) if __name__ == ‘__main__‘: pool = ProcessPoolExecutor(4) a = time.time() # 起始时间 for url in url_list: r = pool.submit(be_async, url) r.add_done_callback(callback) pool.shutdown(wait=True) b = time.time() # 结束时间 print("cost time: %s s"%(b-a))
异步非阻塞IO
通过上述代码均可以完成对请求性能的提高,对于多线程和多进行的缺点是在IO阻塞时会造成了线程和进程的浪费,所以异步会是首选:
1. asyncio 示例,该模块只能处理tcp协议
原理:
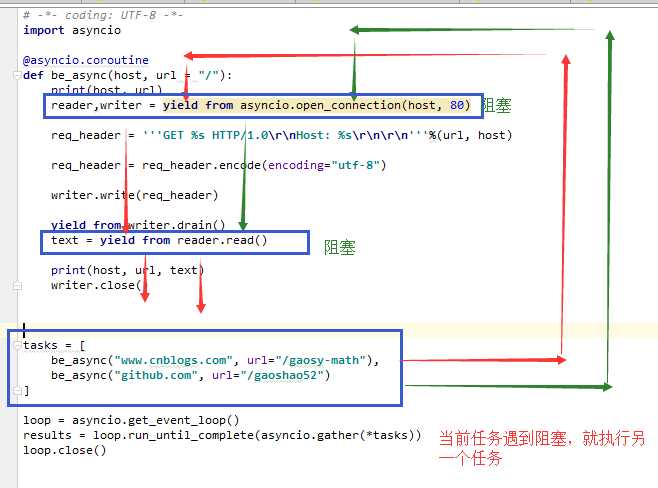
代码:
# -*- coding: UTF-8 -*- import asyncio @asyncio.coroutine def be_async(host, url = "/"): print(host, url) reader,writer = yield from asyncio.open_connection(host, 80) req_header = ‘‘‘GET %s HTTP/1.0 Host: %s ‘‘‘%(url, host) req_header = req_header.encode(encoding="utf-8") writer.write(req_header) yield from writer.drain() text = yield from reader.read() print(host, url, text) writer.close() tasks = [ be_async("www.cnblogs.com", url="/gaosy-math"), be_async("github.com", url="/gaoshao52") ] loop = asyncio.get_event_loop() results = loop.run_until_complete(asyncio.gather(*tasks)) loop.close()
注:python3可以运行,python2没有试过
2. asyncio+aiohttp 示例
原理: 与上面的一致
代码:
# -*- coding: UTF-8 -*- import asyncio import aiohttp @asyncio.coroutine def be_async(url): print(url) res = yield from aiohttp.request(‘GET‘, url) data = yield from res.read() print(url, data) res.close() tasks = [ be_async("https://github.com/gaoshao52"), be_async("https://www.cnblogs.com/gaosy-math") ] loop = asyncio.get_event_loop() results = loop.run_until_complete(asyncio.gather(*tasks)) loop.close()
注:python3运行有问题 ,python2没有试过
3. asyncio+requests 示例
原理:一致
代码:
# -*- coding: UTF-8 -*- import asyncio import requests @asyncio.coroutine def be_async(func, *args): loop = asyncio.get_event_loop() future = loop.run_in_executor(None, func, *args) res = yield from future print(res.url, res.text) tasks = [ be_async(requests.get, "https://github.com/gaoshao52"), be_async(requests.get, "https://www.cnblogs.com/gaosy-math") ] loop = asyncio.get_event_loop() results = loop.run_until_complete(asyncio.gather(*tasks)) loop.close()
注:python3可以运行,python2没有试过
4. gevent+requests 示例
原理:一致
代码:
# -*- coding: UTF-8 -*- import gevent import requests from gevent import monkey monkey.patch_all() def be_async(method, url ,req_kwargs): print(method, url, req_kwargs) res = requests.request(method=method, url=url, **req_kwargs) print(res.url, res.status_code) gevent.joinall([ gevent.spawn(be_async, method=‘GET‘, url="https://github.com/gaoshao52", req_kwargs={}), gevent.spawn(be_async, method=‘GET‘, url="https://www.cnblogs.com/gaosy-math", req_kwargs={}) ]) # ##### 发送请求(协程池控制最大协程数量) ##### # from gevent.pool import Pool # pool = Pool(None) # gevent.joinall([ # pool.spawn(be_async, method=‘GET‘, url="https://github.com/gaoshao52", req_kwargs={}), # pool.spawn(be_async, method=‘GET‘, url="https://www.cnblogs.com/gaosy-math", req_kwargs={}) # ]) # 注: 必须在python2 中运行
注:python3运行有问题, python2可以运行
5. grequests 示例
原理:gevent+requests的封装
代码:
# -*- coding: UTF-8 -*- import grequests request_list = [ grequests.get("http://www.runoob.com/python/python-json.html"), grequests.get("https://www.git-scm.com/download/win") ] ##### 执行并获取响应列表 ##### # response_list = grequests.map(request_list) # print(response_list) # ##### 执行并获取响应列表(处理异常) ##### def exception_handler(request, exception): print(request,exception) print("Request failed") response_list = grequests.map(request_list, exception_handler=exception_handler) print(response_list)
以上是关于爬虫热身——性能相关的主要内容,如果未能解决你的问题,请参考以下文章