Kafka0.8.2官方文档中文版系列-入门指南
Posted dreamfor123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka0.8.2官方文档中文版系列-入门指南相关的知识,希望对你有一定的参考价值。
写在前面的话
本系列文章仅仅代表个人的观点,结合自己的学习、使用经验,将kafka0.8.2官方文档,进行翻译,目录结构按照官方文档进行排版。
目的:
- 系统梳理下kafka知识点,从整体上重新认识下kafka
- 与广大网友进行交流,内容中难免有不合适的地方,还请大家不吝赐教,我会及时更正
- 尽一点点微薄之力,去帮助一些人,大家共同进步
一、Getting Started
1、1 Introduction(简介)
Kafka是一个分布式、分区的、数据备份的日志收集系统。Kafka使用了一种的独特的方式提供了消息传递的功能。
这意味着什么呢?
首先,我们回顾一下消息系统的基本术语:
- Kafka中划分消息类别(逻辑上的划分),使用主题(Topic)。
- 发布消息到Kafka topic的进程,称为生产者(producer)。
- 从topic订阅并处理消息的进程,称为消费者(consumer)。
- Kafka有一个或者多个服务器组成,每个服务器称为代理(broker)。
因此,从宏观上来看(如下图所示),生产者通过网络向Kafka集群发送消息,而Kafka集群又将这些消息提供给消费者:
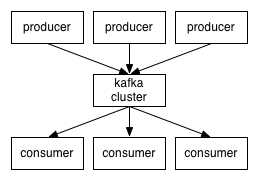
客户端和服务端通过使用简单的、高可用的、语言无关的TCP协议进行通信。我们为kafka提供一个java客户端,但是多种语言实现的客户端可以使用。
Topics and Logs (主题和日志)
Topic是Kafka提供的一种高级抽象。
Topic:是发布消息的类别或订阅源名称。每个Topic包含多个分区的日志文件数据。对于每个topic来说,kafka集群维护这一个分区日志,如下图所示:
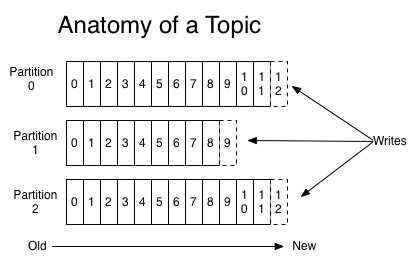
- 每个分区中的数据是有序的,且分区中的数据是不可改变的。每个分区中的数据有一个连续的Id,又称为offset,用来唯一标识一条数据记录。
- Kafka集群在配置的数据过期时间内,保存所有发布的消息,和数据是否被消费过无关。例如,如果将日志保留时间设置为两天,那么在消息发布后的两天内,可以使用它,然后将其丢弃以释放空间。Kafka在数据大小方面的性能实际上是恒定的,因此保留大量数据不是问题。
- consumer只保留offset。仅保存了元数据(消费者消费日志的位置),即offset。offset由consumer控制,通常consumer在读取消息时,会线性增加其偏移量,但是事实上,consumer可以使用任意的顺序来消费消息。比如说,consumer可以设置一个旧的offset重新消费消息。
- 这种特性的组合意味着Kafka消费者非常廉价——他们可以来来去去,不会对kafka集群或其他消费者造成太大影响。换言之,一个topic可以任意多个消费者,这些消费者之间没有关系。
Topic分区的目的:
- 横向扩容,一台机器扩展到多台机器,一个topic有多个分区,这样就可以处理任意数量的数据。
- partitions(分区数量)作为并行度的具体表现形式(这点相对来说更重要)
Distribution(分配)
(本小节的服务器其实就是broker)
日志的分区分布在kafka集群的服务器上,每个服务器处理其内部分区的数据和请求。每个分区可以通过配置一个服务器数量来进行数据的备份,实现容错。
每个分区有一个代理作为该分区的leader,有0个或者多个代理作为follower。作为的leader的代理负责处理该分区所有的读写操作,然而follower只能被动的从leader复制数据。如果leader挂掉了,其中的一个follower将会自动的称为新的leader。每个leader作为一部分分区的领导者,同时又是其它分区的follower,因此集群中的负载是很平衡的。
Producers(生产者)
生产者发布数据到指定的Topic。生产者指定将数据发送到特定topic下面的特定分区中。这可以以循环的方式完成,只是为了平衡负载,也可以根据一些语义分区函数(比如基于消息中的某个键)完成。稍后详细介绍分区的使用。
Consumers(消费者)
传统的消息队列应用有两种模式:队列和发布订阅模式。队列模式:多个消费者可能从一个服务端读取数据,一个消息只能被一个消费者消费。发布订阅模式:一个消息被广播到所有的消费者。Kafka提供了一种简单的消费抽象去实现传统的两种模式-消费组。
消费者通过消费者组名称来标注他们自己(每个消费者都应该归属一个消费者组),发布到主题(topic)的每个消息都传递给每个订阅消费者组中的一个消费者实例。消费实例可以运行在不同的进程或者机器上面。
如果所有的消费者实例有相同的消费者组,这就像传统队列那样,队列的负载均衡通过consumers(消费者个数)来实现。
如果所有的消费者实例有不同的消费组,这就像发布订阅模式一样,所有的消息都会被广播到所有的消费者。
更常见的是,我们发现主题有少量的消费者组,每个“逻辑订阅者”对应一个消费者组。每个消费者组都由许多消费者实例组成,以实现可扩展性和容错。这只不过是发布-订阅语义,其中订阅服务器是消费者集群,而不是单个进程。
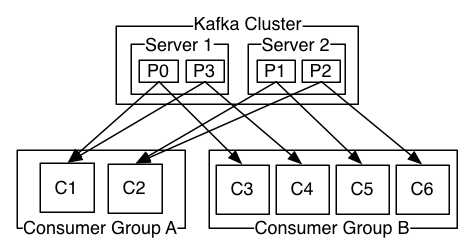
A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
Kafka有一个更加强大的数据序列相比于传统的消息应用系统。(对于数据顺序的处理,kafka做的更好一些,或者说kafka采用不同于传统消息模型的处理方式)
传统队列在服务器上按顺序保留消息,如果多个消费者从队列中消费消息,则服务器按照存储的顺序分发消息。但是,尽管服务器按顺序分发消息,但消息是异步传递给消费者的,因此它们可能在不同的消费者上无序到达。这实际上意味着在存在并行消耗的情况下消息的排序会丢失。消息传递系统通常具有“排他消费者”的概念,只允许一个进程从队列中消耗,但这当然意味着处理中没有并行性。
Kafka在这方面做的更好,通过Topics里面的partition来实现并行机制。Kafka通过一个进程消费池来保证消息有序和负载平衡。这是通过将主题中的分区分配给消费者组中的消费者来实现的,以便每个分区仅由组中的一位消费者使用。 通过这样做,我们确保消费者是该分区的唯一读者并按顺序使用数据。 由于有很多分区,这仍然可以平衡许多消费者实例的负载。
注意:
- 消费者实例不能多于分区数量。
- kafka仅仅只能保证消息在一个分区中的序列,不能保证同一个topic下面的不同分区。
- 如果你要求一个分区下面的所有消息整体有序,那么你只能有一个分区,这也意味着你只能有一个消费实例。
Guarantees(保证)
- Kafka给出了系列保证:由制作者发送到特定主题分区的消息将按照它们发送的顺序附加。 也就是说,如果消息M1由同一个生产者作为消息M2发送,并且M1被首先发送,则M1将具有比M2更低的偏移量并且出现在日志中较早的地方。
- 消费者实例按照它们存储在日志中的顺序查看消息。
- 对于复制因子为N的主题,我们将容忍多达N-1个服务器故障,而不会丢失任何提交给日志的消息。
1、2 Use Cases(用例)
下面是Apache Kafka的一些流行用例的描述。要了解这些领域中的一些活动,请参阅本博客(this blog post)。
Messaging(消息应用)
Kafka可以很好地替代传统的消息代理。消息代理被用于各种原因(将数据处理与数据生成器分离,缓冲未处理的消息等)。与大多数消息传递系统相比,Kafka具有更好的吞吐量,内置的分区,复制和容错能力,这使其成为大型消息处理应用的理想解决方案。
根据我们的经验,消息传递使用通常相对较低,但可能需要较低的端到端延迟,并且通常取决于Kafka提供的强大的耐用性保证。
在这个领域,Kafka与传统的消息系统如ActiveMQ或RabbitMQ相当。
Website Activity Tracking(网站活动跟踪)
Kafka最初的用例是能够将用户活动跟踪管道重新构建为一组实时发布订阅源。这意味着站点活动(页面视图、搜索或用户可能采取的其他操作)被发布到中心主题,每个活动类型有一个主题。这些提要可用于订阅一系列的用例,包括实时处理、实时监控和加载到Hadoop或离线数据仓库系统进行离线处理和报告。
网站活动跟踪通常是非常高的数据量,因为每个用户页面视图都会生成许多活动消息。
Metrics
Kafka通常用于操作监控数据。这包括从分布式应用程序收集统计数据,以生成操作数据的集中提要。
Log Aggregation(日志聚合)
许多人使用Kafka作为日志聚合解决方案的替代。日志聚合通常从服务器收集物理日志文件,并将它们放在中央位置(可能是文件服务器或HDFS)进行处理。Kafka将文件的细节抽象出来,并将日志或事件数据抽象为消息流。这允许更低的延迟处理,更容易支持多个数据源和分布式数据消耗。与以日志为中心的系统(如Scribe或Flume)相比,Kafka提供了同样好的性能、更强的持久性保证,以及更低的端到端延迟。
Stream Processing(流式处理)
许多用户最终会对数据进行阶段性处理,其中数据从原始数据的主题中消费,然后聚合、充实或转换为新的Kafka主题以供进一步使用。例如,文章推荐的处理流程可以从RSS提要中抓取文章内容并将其发布到“文章”主题;进一步的处理可能有助于将该内容规范化或反复制到清理过的文章内容的主题;最后一个阶段可能尝试将此内容与用户匹配。这将创建一个从各个主题中流出的实时数据流图。Storm和Samza是实现这些转换的流行框架。
Event Sourcing(事件溯源)
事件溯源是一种应用程序设计风格,其中状态更改记录为时间顺序的记录。Kafka对非常大的存储日志数据的支持使它成为这种风格的应用程序的优秀后端。
Commit Log(日志提交)
Kafka可以作为一种分布式系统的外部提交日志。日志帮助在节点之间复制数据,并充当失败节点的重新同步机制,以恢复它们的数据。Kafka中的日志压缩特性有助于支持这种用法。在这个用法中,Kafka类似于Apache BookKeeper项目。
1、3 Quick Start
本教程假设您正在从头开始,并且没有任何Kafka或ZooKeeper数据。
Step 1: Download the code(第一步:下载源码)
> tar -xzf kafka_2.10-0.8.2.0.tgz
> cd kafka_2.10-0.8.2.0
Step 2: Start the server(第二步:启动Server)
Kafka使用ZooKeeper,所以如果没有的话,你需要先启动一个ZooKeeper服务器。您可以使用与kafka打包的便利脚本来获得一个快速而肮脏的单节点ZooKeeper实例。
> bin/zookeeper-server-start.sh config/zookeeper.properties
[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
...
现在启动Kafka服务器:
> bin/kafka-server-start.sh config/server.properties
[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
...
Step 3: Create a topic(第三步:创建topic)
让我们用一个分区和一个副本创建一个名为“test”的主题:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
运行下面的命令,可以看到刚才创建的topic:
> bin/kafka-topics.sh --list --zookeeper localhost:2181
test
另外,您也可以将代理配置为在发布不存在的主题时自动创建主题,而不是手工创建主题。
Step 4: Send some messages(发送消息)
Kafka附带一个命令行客户端,该客户端可以从文件或标准输入接收输入数据,并将其作为消息发送到Kafka集群。默认情况下,每一行将作为单独的消息发送。
运行producer,然后向控制台输入一些消息,以发送到服务器。
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
Step 5: Start a consumer(开启一个消费者)
kafka也提供了一个消费者客户端工具,可以将消息发送到控制台。
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
This is a message
This is another message
如果你执行了上面所用的命令,你可以在producer的控制台输入消息,并在producer控制台看到对应的输出消息。
所有的命令行工具都有其它额外的参数,运行这些命令不指定参数,你将会看到更多详细的信息。
Step 6: Setting up a multi-broker cluster(设置一个多代理集群)
到目前为止,我们已经可以基于一个broker来运行kafka了,但是这是没有意思的。对kafka来说,单个broker,仅仅只是有一个节点的集群;因此更大规模的集群只是启动多个broker实例而已。为了去感受一下它,我们把我们的集群扩展到三个节点(仍然是在我们的本地机器上)。
首先,我们为每个代理创建一个配置文件:
> cp config/server.properties config/server-1.properties
> cp config/server.properties config/server-2.properties
现在修改配置文件,设置如下属性
config/server-1.properties:
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
port=9094
log.dir=/tmp/kafka-logs-2
broker.id是节点在集群中唯一的,不变的名称。由于我们运行这些broker在同一台机器上,为了保证这些尝试去注册相同的端口号,互相重写数据,我们不得不修改端口号和日志目录。
我们的zookeeper和一个节点已经启动了,因此我们只需要启动两个新的节点即可:
> bin/kafka-server-start.sh config/server-1.properties & ... > bin/kafka-server-start.sh config/server-2.properties & ...
现在我们创建一个新的,副本因子为3的topic:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
好了,我们已经创建了一个集群,但是我们如何查看集群中的broker都在做什么呢?运行describe topics命令
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
对上面输出的参数做一个解释。第一行给出所有分区的摘要,每个附加行给出关于一个分区的信息。因为这个主题只有一个分区,所以只有一行。
- leader:leader负责管辖分区的所有读和写。通过分区的随机的选择,每个节点都会是leader。
- replicas:是为这个分区复制日志的节点列表,无论它们是否为leader,或者即使它们现在还活着。
- isr:isr是“同步”副本的集合。这是复制列表的一个子集,该列表当前是活动的,并被链接到leader。
注意,在我的示例中,节点1是主题惟一分区的领导者。
我们也可以运行相同的命令去查看我们最初创建的topic:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test Topic:test PartitionCount:1 ReplicationFactor:1 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
这并没有什么奇怪的,最初的topic没有副本,只在Server0上,当时我们的集群上只有一个Server。
让我们发布一些消息到我们的新主题上:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic ... my test message 1 my test message 2 ^C
现在我们来消费这些消息:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic ... my test message 1 my test message 2 ^C
现在我们来测试容错性,broker1扮演了领导者(leader)角色,我们kill掉它
> ps | grep server-1.properties
7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home/bin/java...
> kill -9 7564
新的leader已经切换到之前slave节点中的一个上了,节点1已经不在同步副本的集合中了
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
尽管原本负责写操作的leader已经挂掉了,但是消息还是可以继续消费的
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
1、4 Ecosystem
有许多工具在主要发行版之外集成了Kafka。生态系统页面列出了其中的许多,包括流处理系统、Hadoop集成、监视和部署工具。
1、5 Upgrading From Previous Versions
Upgrading from 0.8.1 to 0.8.2.0
0.8.2.0与0.8.1完全兼容。只需将其关闭、更新代码并重新启动,就可以一次只对一个代理进行升级。
Upgrading from 0.8.0 to 0.8.1
0.8.1与0.8完全兼容。只需将其关闭、更新代码并重新启动,就可以一次只对一个代理进行升级。
Upgrading from 0.7
0.8,添加了复制的版本,是我们第一个向后不兼容的版本:对API、ZooKeeper数据结构、协议和配置进行了重大更改。从0.7升级到0.8.x需要一个特殊的迁移工具。这种迁移可以在不停机的情况下完成。
以上是关于Kafka0.8.2官方文档中文版系列-入门指南的主要内容,如果未能解决你的问题,请参考以下文章
Swift入门系列--Swift官方文档(2.2)--中文翻译--About Swift 关于Swift
一起学微软Power BI系列-官方文档-入门指南Power BI建模