es学习-索引配置
Posted anxbb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了es学习-索引配置相关的知识,希望对你有一定的参考价值。
1.创建一个新的索引并且添加一个配置
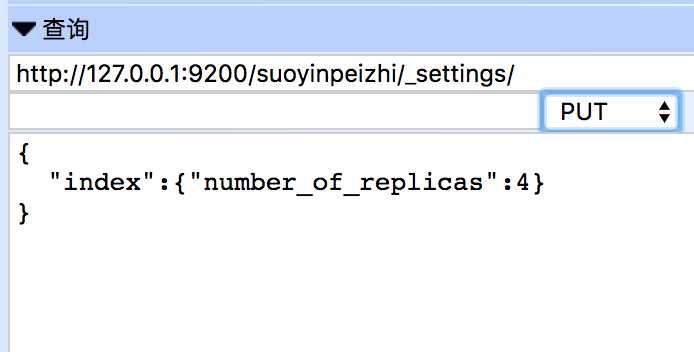
2.更新索引配置:(更新分词器为例子)
更新分词器前,一定要关闭索引,然后更新,最后再次开启索引
url:PUT http://127.0.0.1:9200/suoyinpeizhi/_settings/
参数:
{
"analysis": {
"analyzea": {
"content": {
"type": "custom",
"tokenizer": "whitespace"
}
}
}
}
如果不关闭会提示以下错误
{
"error": {
"root_cause": [{
"type": "illegal_argument_exception",
"reason": "Can‘t update non dynamic settings[[index.analysis.analyzea.content.tokenizer, index.analysis.analyzea.content.type]] for open indices [[suoyinpeizhi]]"
}],
"type": "illegal_argument_exception",
"reason": "Can‘t update non dynamic settings[[index.analysis.analyzea.content.tokenizer, index.analysis.analyzea.content.type]] for open indices [[suoyinpeizhi]]"
},
"status": 400
}
所以 先运行: POST http://127.0.0.1:9200/suoyinpeizhi/_close
然后在运行上面的参数
最后运行: POST http://127.0.0.1:9200/suoyinpeizhi/_open
获取索引配置:
第一种:http://127.0.0.1:9200/suoyinpeizhi/_settings/获取所有
第二种:http://127.0.0.1:9200/suoyinpeizhi/_settings/index.number_*/
索引分析:将一个文本分析成一个个单独的词,为了后面的倒排索引做准备。这个过程是由分词器(analyzers)完成的
一个分词器是一个组合,它包括(字符过滤器,分词器,标记过滤器)
字符过滤器:在标记化之前处理字符串(比如去除html 标记,或者将 &转化为 and)
分词器:分词器被标记化成独立的词,一个简单的分词器(tokenizer)可以根据逗号或者空格将单词分开。
标记过滤器:它可以修改词,去掉词,增加词
以上是关于es学习-索引配置的主要内容,如果未能解决你的问题,请参考以下文章