KVM详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KVM详解相关的知识,希望对你有一定的参考价值。
KVM 介绍(1):简介及安装
http://www.cnblogs.com/sammyliu/p/4543110.html
学习 KVM 的系列文章:
- (1)介绍和安装
- (2)CPU 和 内存虚拟化
- (3)I/O QEMU 全虚拟化和准虚拟化(Para-virtulizaiton)
- (4)I/O PCI/PCIe设备直接分配和 SR-IOV
- (5)libvirt 介绍
- (6)Nova 通过 libvirt 管理 QEMU/KVM 虚机
- (7)快照 (snapshot)
- (8)迁移 (migration)
1. KVM 介绍
1.0 虚拟化简史
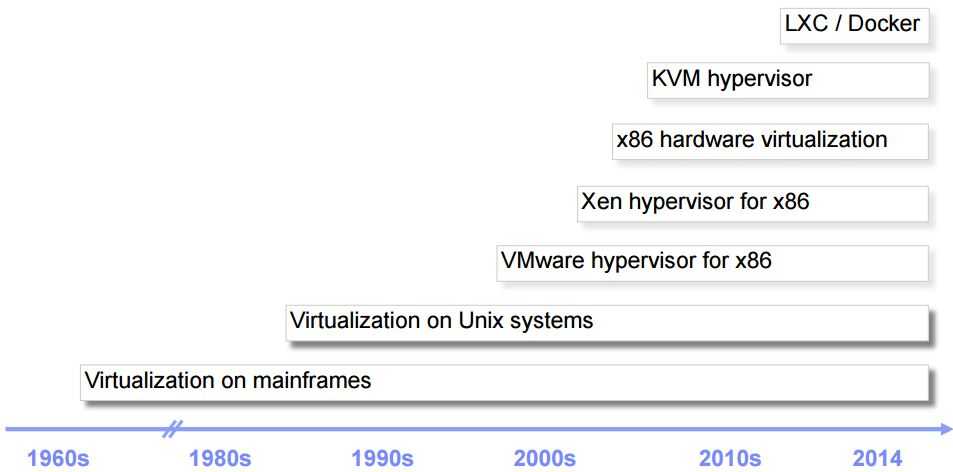
其中,KVM 全称是 基于内核的虚拟机(Kernel-based Virtual Machine),它是一个 Linux 的一个内核模块,该内核模块使得 Linux 变成了一个 Hypervisor:
- 它由 Quramnet 开发,该公司于 2008年被 Red Hat 收购。
- 它支持 x86 (32 and 64 位), s390, Powerpc 等 CPU。
- 它从 Linux 2.6.20 起就作为一模块被包含在 Linux 内核中。
- 它需要支持虚拟化扩展的 CPU。
- 它是完全开源的。官网。
本文介绍的是基于 X86 CPU 的 KVM。
1.1 KVM 架构
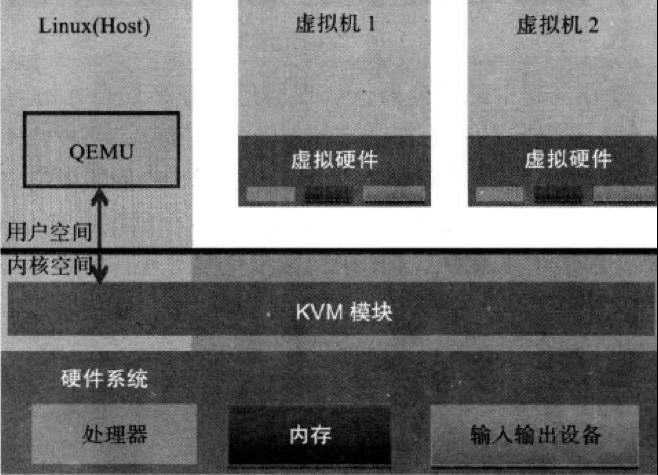
- Guest:客户机系统,包括CPU(vCPU)、内存、驱动(Console、网卡、I/O 设备驱动等),被 KVM 置于一种受限制的 CPU 模式下运行。
- KVM:运行在内核空间,提供CPU 和内存的虚级化,以及客户机的 I/O 拦截。Guest 的 I/O 被 KVM 拦截后,交给 QEMU 处理。
- QEMU:修改过的为 KVM 虚机使用的 QEMU 代码,运行在用户空间,提供硬件 I/O 虚拟化,通过 IOCTL /dev/kvm 设备和 KVM 交互。
KVM 是实现拦截虚机的 I/O 请求的原理:
QEMU-KVM:
KVM:
- 首先初始化内部的数据结构;
- 做好准备后,KVM 模块检测当前的 CPU,然后打开 CPU 控制及存取 CR4 的虚拟化模式开关,并通过执行 VMXON 指令将宿主操作系统置于虚拟化模式的根模式;
- 最后,KVM 模块创建特殊设备文件 /dev/kvm 并等待来自用户空间的指令。
2. KVM 的功能列表
KVM 所支持的功能包括:
- 支持CPU 和 memory 超分(Overcommit)
- 支持半虚拟化I/O (virtio)
- 支持热插拔 (cpu,块设备、网络设备等)
- 支持对称多处理(Symmetric Multi-Processing,缩写为 SMP )
- 支持实时迁移(Live Migration)
- 支持 PCI 设备直接分配和 单根I/O 虚拟化 (SR-IOV)
- 支持 内核同页合并 (KSM )
- 支持 NUMA (Non-Uniform Memory Access,非一致存储访问结构 )
3. KVM 工具集合
- libvirt:操作和管理KVM虚机的虚拟化 API,使用 C 语言编写,可以由 Python,Ruby, Perl, php, Java 等语言调用。可以操作包括 KVM,vmware,XEN,Hyper-v, LXC 等 Hypervisor。
- Virsh:基于 libvirt 的 命令行工具 (CLI)
- Virt-Manager:基于 libvirt 的 GUI 工具
- virt-v2v:虚机格式迁移工具
- virt-* 工具:包括 Virt-install (创建KVM虚机的命令行工具), Virt-viewer (连接到虚机屏幕的工具),Virt-clone(虚机克隆工具),virt-top 等
- sVirt:安全工具
4. RedHat Linux KVM 安装
- KVM 由 libvirt API 和基于该 API的一组工具进行管理和控制。
- KVM 支持系统资源超分,包括内存和CPU的超分。RedHat Linux 最多支持物理 CPU 内核总数的10倍数目的虚拟CPU,但是不支持在一个虚机上分配超过物理CPU内核总数的虚拟CPU。
- 支持 KSM (Kenerl Same-page Merging 内核同页合并)
RedHat Linux KVM 有如下两种安装方式:
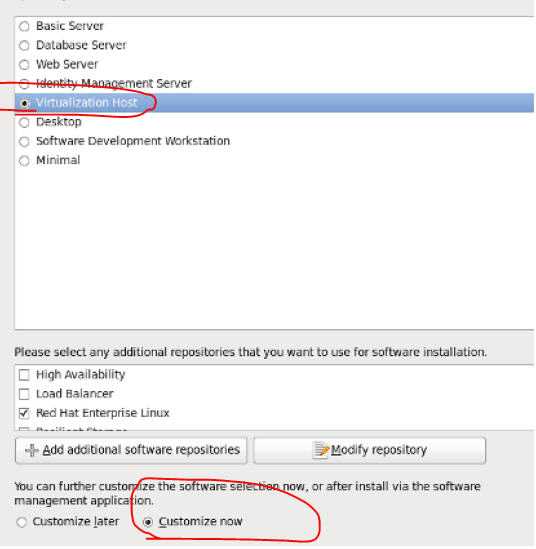
4.1 在安装 RedHat Linux 时安装 KVM
选择安装类型为 Virtualizaiton Host :
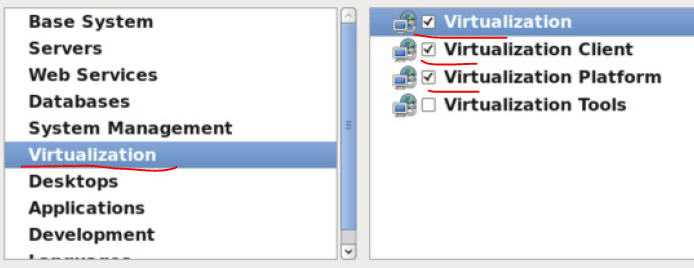
可以选择具体的 KVM 客户端、平台和工具:
4.2 在已有的 RedHat Linux 中安装 KVM
这种安装方式要求该系统已经被注册,否则会报错:
[[email protected] ~]# yum install qemu-kvm qemu-img Loaded plugins: product-id, refresh-packagekit, security, subscription-manager This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register. Setting up Install Process Nothing to do
你至少需要安装 qemu-kvm qemu-img 这两个包。
# yum install qemu-kvm qemu-img
你还可以安装其它工具包:
# yum install virt-manager libvirt libvirt-python python-virtinst libvirt-client
4.3 QEMU/KVM 代码下载编译安装
4.3.1 QEMU/KVM 的代码结构
QEMU/KVM 的代码包括几个部分:
(1)KVM 内核模块是 Linux 内核的一部分。通常 Linux 比较新的发行版(2.6.20+)都包含了 KVM 内核,也可以从这里得到。比如在我的RedHat 6.5 上:
[[email protected] isoimages]# uname -r 2.6.32-431.el6.x86_64 [[email protected] isoimages]# modprobe -l | grep kvm kernel/arch/x86/kvm/kvm.ko kernel/arch/x86/kvm/kvm-intel.ko kernel/arch/x86/kvm/kvm-amd.ko
(2)用户空间的工具即 qemu-kvm。qemu-kvm 是 KVM 项目从 QEMU 新拉出的一个分支(看这篇文章)。在 QEMU 1.3 版本之前,QEMU 和 QEMU-KVM 是有区别的,但是从 2012 年底 GA 的 QEMU 1.3 版本开始,两者就完全一样了。
(3)Linux Guest OS virtio 驱动,也是较新的Linux 内核的一部分了。
(4)Windows Guest OS virtio 驱动,可以从这里下载。
4.3.2 安装 QEMU
RedHat 6.5 上自带的 QEMU 太老,0.12.0 版本,最新版本都到了 2.* 了。
(1). 参考 这篇文章,将 RedHat 6.5 的 ISO 文件当作本地源

mount -o loop soft/rhel-server-6.4-x86_64-dvd.iso /mnt/rhel6/
vim /etc/fstab
=> /root/isoimages/soft/RHEL6.5-20131111.0-Server-x86_64-DVD1.iso /mnt/rhel6 iso9660 ro,loop
[[email protected] qemu-2.3.0]# cat /etc/yum.repos.d/local.repo
[local]
name=local
baseurl=file:///mnt/rhel6/
enabled=1
gpgcjeck=0
|
1
|
yum clean all
yum update |
(2). 安装依赖包包
yum install gcc
yum install autoconf
yum install autoconf automake libtool
yum install -y glib* yum install zlib*
(3). 从 http://wiki.qemu.org/Download 下载代码,上传到我的编译环境 RedHat 6.5.
tar -jzvf qemu-2.3.0.tar.bz2
cd qemu-2.3.0 ./configure
make -j 4 make install
(4). 安装完成
[[email protected] qemu-2.3.0]# /usr/local/bin/qemu-x86_64 -version qemu-x86_64 version 2.3.0, Copyright (c) 2003-2008 Fabrice Bellard
(5). 为方便起见,创建一个link
ln -s /usr/bin/qemu-system-x86_64 /usr/bin/qemu-kvm
4.3.3 安装 libvirt
可以从 libvirt 官网下载安装包。最新的版本是 0.10.2.
5. 创建 KVM 虚机的几种方式
5.1 使用 virt-install 命令
virt-install \\ --name=guest1-rhel5-64 \\ --file=/var/lib/libvirt/images/guest1-rhel5-64.dsk \\ --file-size=8 \\ --nonsparse --graphics spice \\ --vcpus=2 --ram=2048 \\ --location=http://example1.com/installation_tree/RHEL5.6-Serverx86_64/os \\ --network bridge=br0 \\ --os-type=linux \\ --os-variant=rhel5.4
5.2 使用 virt-manager 工具
使用 VMM GUI 创建的虚机的xml 定义文件在 /etc/libvirt/qemu/ 目录中。
5.3 使用 qemu-img 和 qemu-kvm 命令行方式安装
(1)创建一个空的qcow2格式的镜像文件
qemu-img create -f qcow2 windows-master.qcow2 10G
(2)启动一个虚机,将系统安装盘挂到 cdrom,安装操作系统
qemu-kvm -hda windows-master.qcow2 -m 512 -boot d -cdrom /home/user/isos/en_winxp_pro_with_sp2.iso
(3)现在你就拥有了一个带操作系统的镜像文件。你可以以它为模板创建新的镜像文件。使用模板的好处是,它会被设置为只读所以可以免于破坏。
qemu-img create -b windows-master.qcow2 -f qcow2 windows-clone.qcow2
(4)你可以在新的镜像文件上启动虚机了
qemu-kvm -hda windows-clone.qcow2 -m 400
5.4 通过 OpenStack Nova 使用 libvirt API 通过编程方式来创建虚机 (后面会介绍)
KVM 介绍(2):CPU 和内存虚拟化
学习 KVM 的系列文章:
- (1)介绍和安装
- (2)CPU 和 内存虚拟化
- (3)I/O QEMU 全虚拟化和准虚拟化(Para-virtulizaiton)
- (4)I/O PCI/PCIe设备直接分配和 SR-IOV
- (5)libvirt 介绍
- (6)Nova 通过 libvirt 管理 QEMU/KVM 虚机
- (7)快照 (snapshot)
- (8)迁移 (migration)
1. 为什么需要 CPU 虚拟化
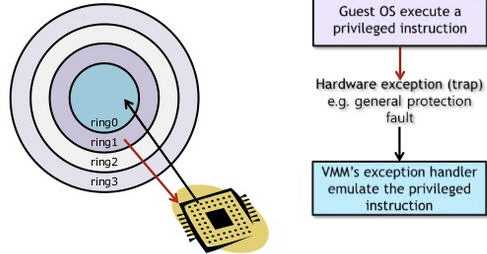
- 操作系统(内核)需要直接访问硬件和内存,因此它的代码需要运行在最高运行级别 Ring0上,这样它可以使用特权指令,控制中断、修改页表、访问设备等等。
- 应用程序的代码运行在最低运行级别上ring3上,不能做受控操作。如果要做,比如要访问磁盘,写文件,那就要通过执行系统调用(函数),执行系统调用的时候,CPU的运行级别会发生从ring3到ring0的切换,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备访问,完成之后再从ring0返回ring3。这个过程也称作用户态和内核态的切换。
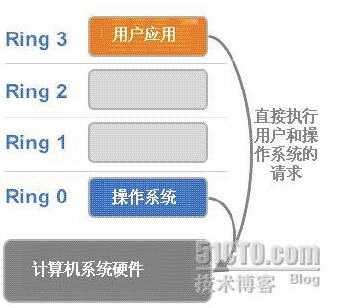
1.1 基于二进制翻译的全虚拟化(Full Virtualization with Binary Translation)
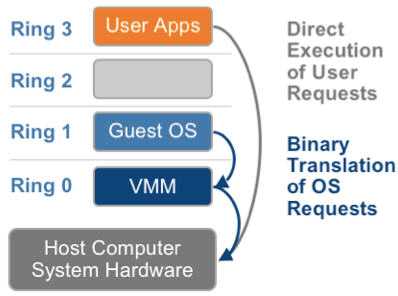
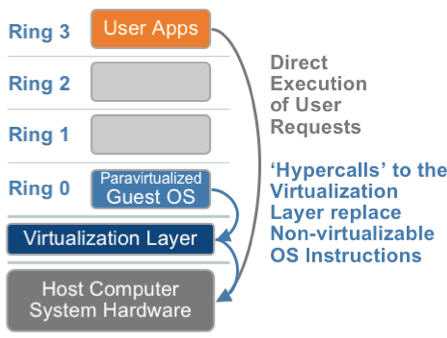
1.2. 超虚拟化(或者半虚拟化/操作系统辅助虚拟化 Paravirtualization)
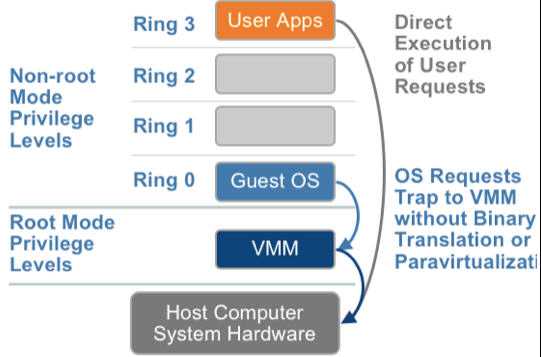
1.3. 硬件辅助的全虚拟化
|
|
利用二进制翻译的全虚拟化
|
硬件辅助虚拟化
|
操作系统协助/半虚拟化
|
| 实现技术 |
BT和直接执行
|
遇到特权指令转到root模式执行
|
Hypercall
|
| 客户操作系统修改/兼容性 |
无需修改客户操作系统,最佳兼容性
|
无需修改客户操作系统,最佳兼容性
|
客户操作系统需要修改来支持hypercall,因此它不能运行在物理硬件本身或其他的hypervisor上,兼容性差,不支持Windows
|
| 性能 |
差
|
全虚拟化下,CPU需要在两种模式之间切换,带来性能开销;但是,其性能在逐渐逼近半虚拟化。
|
好。半虚拟化下CPU性能开销几乎为0,虚机的性能接近于物理机。
|
| 应用厂商 |
VMware Workstation/QEMU/Virtual PC
|
VMware ESXi/Microsoft Hyper-V/Xen 3.0/KVM
|
Xen
|
2. KVM CPU 虚拟化
KVM 是基于CPU 辅助的全虚拟化方案,它需要CPU虚拟化特性的支持。
2.1. CPU 物理特性
这个命令查看主机上的CPU 物理情况:
[[email protected] ~]$ numactl --hardware available: 2 nodes (0-1) //2颗CPU node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17 //这颗 CPU 有8个内核 node 0 size: 12276 MB node 0 free: 7060 MB node 1 cpus: 6 7 8