小小总结,写得有些乱
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小小总结,写得有些乱相关的知识,希望对你有一定的参考价值。
字符串:
字符串常用方法:
# -*- coding:utf-8 -*-
# author:ke_T\\
name = "ke_T"
print(name.capitalize()) #首字母大写,但是不改变name值
print(name.count("k")) #寻找这个字符串中k这个字符串出现的次数
print(name.center(3,"*")) #这个10时一种占的长度,不够的话,用*补充,够的话则不用
print(name.endswith("T")) #判断是否以某字符串结尾
print(name.find("k")) #找到这个字符串的索引,这里k,返回0
print(name.isalnum()) #判断是否为阿拉伯字母或者数字
print(name.isalpha()) #判断是否为英文
print(name.isidentifier()) #判断是否是合法的标识符,中文也是合法的但是想*这些就不是的,下划线合法哦
print(name.islower())
print(name.strip()) #忽略空格还有换行符
# s随机密码的生成模式
p = str.maketrans("abcd","1903")
print("asdjsd".translate(p)) #生成结果1s3js3
print("kekkq".replace(‘ke‘,‘q‘,2)) #第一个参数,要替换的字符,第二个参数,替换成什么字符,第三个参数,替换几个,不写默认全部替换.
#当然,也可以替换字符串
print("kksad aa".rfind(‘a‘)) #找到该字符串最后出现的位置
print("bbq qc".title()) #变成标题的形式,就是首字母大写
列表:
列表是python中最常见的数据类型,它可以作为一个方括号内的都好分隔值出现,列表中的值不需要是同一个类型。
import copy
names = ["kejinxun","keteng","huangchunxiao","xieyuanyi","liuchenggong","mahuateng"]
print(names[1])#根据下标去数据
print(names[1:2])#根据范围取出数据,取出的是个列表,这里取出的列表为[‘keteng‘],因为这种方式的特点是,取头不取尾
print(names[1:3][1])#根据范围取出的列表,再拿数据的方式也就是列表拿数据的方式结果为huangchunxiao
print(copy.copy(names))#列表的复制,引入copy模块,调用copy函数,浅copy,就是不会独立的列表,指向同一个内存地址,深copy,则是用copy模块的copy函数,这样子会重新开辟一个内存,存放另一个列表
print(names[-3:-1])#负数,从列表右边往左数起,因此结果为[‘xieyuanyi‘, ‘liuchenggong‘]
print(names[names.index("keteng")]) #keteng,根据元素内容找到下标,然后在通过下标,返回元素
#列表元素的插入
names.append("chenxiaomei")#直接在列表后边添加元素
print(names)#打印结果为[‘kejinxun‘, ‘keteng‘, ‘huangchunxiao‘, ‘xieyuanyi‘, ‘liuchenggong‘, ‘mahuateng‘, ‘chenxiaomei‘]
names.insert(1,"ke") #按照下标插入
print(names) #打印结果为[‘kejinxun‘, ‘ke‘, ‘keteng‘, ‘huangchunxiao‘, ‘xieyuanyi‘, ‘liuchenggong‘, ‘mahuateng‘, ‘chenxiaomei‘]
#列表元素的删除
names.remove("ke")#根据名字删除
print(names) #[‘kejinxun‘, ‘keteng‘, ‘huangchunxiao‘, ‘xieyuanyi‘, ‘liuchenggong‘, ‘mahuateng‘, ‘chenxiaomei‘]
names.pop() #直接移除最后的那个元素
print(names) #[‘kejinxun‘, ‘keteng‘, ‘huangchunxiao‘, ‘xieyuanyi‘, ‘liuchenggong‘, ‘mahuateng‘]
names.pop(1) #移除下标为1的元素
print(names) #打印结果为[‘kejinxun‘, ‘huangchunxiao‘, ‘xieyuanyi‘, ‘liuchenggong‘, ‘mahuateng‘]
#列表常用功能
names.reverse() #反转
print(names) #[‘mahuateng‘, ‘liuchenggong‘, ‘xieyuanyi‘, ‘huangchunxiao‘, ‘kejinxun‘]
names.sort() #排序,根据Ascii排序
print(names) #[‘huangchunxiao‘, ‘kejinxun‘, ‘liuchenggong‘, ‘mahuateng‘, ‘xieyuanyi‘]
name = [1,2,3]
names.extend(name) #继承
print(names) #[‘huangchunxiao‘, ‘kejinxun‘, ‘liuchenggong‘, ‘mahuateng‘, ‘xieyuanyi‘, 1, 2, 3]
name.extend(name)
print(name) #[1, 2, 3, 1, 2, 3]
name.append("bbc")
name.append("bbc")
print(name)
print(name.index("bbc")) #只要找到最开始出现的那一次,就退出,并返回该下标
#循环
for i in name: #i指向了name,打印了相当于name[下标的东西]
print(i)
print(name[::1]) #[1, 2, 3, 1, 2, 3, ‘bbc‘, ‘bbc‘]
print(name[1::]) #[2, 3, 1, 2, 3, ‘bbc‘, ‘bbc‘],这样子的形式,name[i:j:k],
# i表示开始的下标,即表示结束的下标,k表示隔着几个遍历,i默认为0,j默认为列表的长度,k默认为1
#列表删除某个元素
del name[1]
print(3 in [1,2,3]) #查询某个元素是否在这个列表
字典:
字典是key-value的形式,是Python中的唯一的映射类型,它是无序的,因此像列表那样不能通过下标来访问,字典中的键是唯一的,值不唯一。特点:
- 键与值用冒号:分开;
- 2.项与项用逗号,分开
- 字典的键必须唯一
访问字典的值:
Addict[key],存在则返回值,不存在则返回keyError错误。
修改字典的值:
Addict[key] = 内容,如果存在该key,则会修改该key的值,如果不存在,则会增加这个键
删除字典的值:
和列表一样,用del addict[key]
更新字典:
info = {
‘001‘: "keteng",
‘002‘: "wuzetian",
‘003‘: "liuchenggong"
}
info2 = {"bbc":[1,2],
‘002‘:{‘c‘:‘cvd‘}}
info.update(info2) #同key的,则改变原字典的,不同的则加入
print(info)
字典的遍历:
for i in info: #遍历字典,i指向了key
print(i,info[i])
for k,v in info.items(): #遍历字典,k指向key,v指向了value
print(k,v)
元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
访问元组
元组可以使用下标索引来访问元组中的值
修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下
yuzu1 = (1,2,3)
yuzu2 = (2,3,4)
yuanzu3 = yuzu1 + yuzu2
print(yuanzu3)
不过我总觉得没有多大的意义。
删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
yuzu1 = (1,2,3)
yuzu2 = (2,3,4)
del yuzu1
print(yuzu1)
输出之后会报错哦NameError: name ‘yuzu1‘ is not defined
元组运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
|
Python 表达式 |
结果 |
描述 |
|
len((1, 2, 3)) |
3 |
计算元素个数 |
|
(1, 2, 3) + (4, 5, 6) |
(1, 2, 3, 4, 5, 6) |
连接 |
|
(‘Hi!‘,) * 4 |
(‘Hi!‘, ‘Hi!‘, ‘Hi!‘, ‘Hi!‘) |
复制 |
|
3 in (1, 2, 3) |
True |
元素是否存在 |
|
for x in (1, 2, 3): print x, |
1 2 3 |
迭代 |
函数
函数就很重要的啦,函数的形式为def 函数名(),函数还分为无参函数,有参函数,还有缺省函数,匿名函数
无参函数:
def tes1():
这个就是无参函数的表现形式啦
有参函数
def test(a,b):
缺省函数
def test(a,d,b=22,c=33):
print(a)
print(b)
print(c)
print(d)
test(d=11,a=22,c=44)
这个就是缺省函数例子,一定例子要至少输入两个参数,因为a,d没有赋值。
还有传进的是元组和字典时,需要字符标识
def test(a,b,c=33,*args,**kwargs):#在定义的时候 *,**用来表示后面的变量有特殊功能
print(a)
print(b)
print(c)
print(args)
print(kwargs)
#test(11,22,33,44,55,66,77,task=99,done=89)
def test1(**a):
print(a["name"])
A = (44,55,66)
B = {"name":"laowang","age":18}
test(11,22,33,*A,**B)#在实参中*,**表示对元祖/字典进行拆包
test1(**B)
匿名函数
lambda,匿名函数的声明
应用实例
infors = [{"name":"laowang","age":10},{"name":"xiaoming","age":20},{"name":"banzhang","age":10}]
infors.sort(key=lambda x:x[‘age‘])
print(infors)
我来解释下这个例子吧。首先因为列表正常来说是可以用sort直接排序的,但是由于列表中的元素是字典类型,它不知道按照什么来排序,所以我们需要告诉列表以什么来排,因此这里调用匿名函数,lambda x:x[‘age’]返回age的大小,这样子,就完成了排序。
拓展:
a = [100]
b=[200]
def test2(num,num2):
num +=num
num2 = num2 + num2
print(num,num2)
test2(a,b)
print(a,b)
你觉得输出结果是什么呢?
在不了解之前,我想着是输出
[100, 100] [200, 200]
[100, 100] [200, 200]
但是实际上不是,num+=num并不等于num = num +num,b并没有改变,因为num2 = num2+num2中,num2+num2是开辟了一个新内存,然后,num2指向了这个新内存。
对象
什么是对象,车,人,电脑都是对象,应该说一切皆对象。而对象会有属性,比如人,身高就是他的属性之一。对象还有方法,这个方法又是什么呢?比如有的人会游泳,这个游泳就是方法,有了游泳这个方法,这个人的这个对象就会游泳,会谈吉他,则他有会谈吉他的方法。
对象的构造方法,构造方法则是对于一个对象的初始化,比如一辆车,制造出来之前是否应该有模型呢?照着这个模型的参数不就可以做出车子。因此通过构造方法初始化对象就是这么一回事。而构造方法有参数的时候,就是定制不一样的车子,宝马和桑塔纳能一样吗?它们之间因为构造参数的不同,因此造出来的对象不同。好了,我感觉自己扯犊子了,嘻嘻。还是正经点首先说下对象的构造方法,在Python中,一般构造方法的命名有规范,一般在构造函数前后使用两个下划线,__init__()。
觉得对象这里好像没有什么特别要说的,对象添加属性就是实例化的对象.属性名 = 什么,如果存在该属性名,则更改该属性的值,如果不存在,则添加新属性。我觉得有个很需要注意得就是,对象中的函数,都有个self参数,这个代表对象本身,如果修改对象本身的值,则需要self.属性名 = xxx,以此完成赋值。
忘记了,对象的私有变量也是很重要的。 首先一定要双下划线开始,这就代表着定义了一个私有变量,self.__age = 0#定义了一个私有的属性,属性的名字是__age
私有方法,则和私有属性定义一样,也是双下划线开头,才会被认定为是私有方法。
对象的继承
继承是什么样的概念?还是以车为例子,是不是所有的车都应该有基础的属性,比如车轮子,车身等基础属性。而车是不是又会有宝马,法拉利。我们可以吧宝马,法拉利看成是普通车子的继承,宝马法拉利有基本的车的属性,但是它又扩展了新的功能。我们可以这么想,继承是为了完善。
class Animal:
def eat(self):
print("-----吃----")
def drink(self):
print("-----喝----")
class Dog(Animal):
def bark(self):
print("----汪汪叫---")
这个就是对象的继承,Animal对象被Dog对象继承,狗是不是属于动物类,你要是说动物都会汪汪汪叫,这肯定不对,但是你说动物都会吃,都会喝,这不是动物的基本功能吗?而继承,则Dog对象自动继承了吃喝的功能,它自己又有个新的功能就是汪汪汪叫。随意要给他增加新的功能。
对象方法的重写
重写,只有继承了对象的对象,然后又定义了它的父类已经拥有的方法,才叫重写。
这里举不出什么好例子,我就不举了,嘻嘻。
私有属性与私有方法的在继承中的调用
私有的方法,继承的对象无法继承。而私有的属性,也无法直接访问,只能通过父类的方法调用来访问私有的对象属性
# -*- coding:utf-8 -*-
# author:ke_T
class A:
def __init__(self):
self.num1 = 100
self.__num2 = 200
def test1(self):
print("-----test1----")
def __test2(self):
print("-----test2----")
def test3(self):
self.__test2()
print(self.__num2)
def get_num2(self):
return self.__num2
class B(A):
def test4(self):
##self.__test2()
print(self.__num2)
b = B()
b.test4()
比如这个例子,当我想通过继承的对象调用父类的私有属性时,就报了错误。
多继承
多继承则是有多个父类,它有个很需要注意的点,看下面的案例
# -*- coding:utf-8 -*-
# author:ke_T
class Base(object):
def test(self):
print("----Base")
class A(Base):
def test(self):
print("-----A")
class B(Base):
def test(self):
print("-----B")
class C(A,B):
pass
#def test(self):
#
print("-----C")
c = C()
c.test()
print(C.__mro__)
打印结果:
-----A
(<class ‘__main__.C‘>, <class ‘__main__.A‘>, <class ‘__main__.B‘>, <class ‘__main__.Base‘>, <class ‘object‘>).
__mro函数,打印一个元组,是继承对象方法调用的层次结构,,而这个顺序,就是看继承的时候的顺序,C(A,B),则如果C中没有重写的方法调用,则会顺着先到A,再到B,再到Base,最后到Object。当然,如果在C(B,A)则从B再到A。当然,在设计类的时候,要尽可能保证这些类中没有相同的方法。像这样子的形式,就是要调用B的test方法,那该怎么办?想想方法的重写的调用,就要在A中的test函数写上B.test(self),这样就实现调用了
类属性

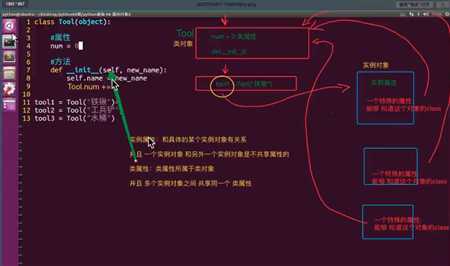
类方法
类方法的格式,就需要写@classmethod,声明是类的方法,然后传参的命名是cls,这个是规范命名,当然,你也可以不这样子命名,不过会觉得你不专业。

静态方法,也需要标识,@staticmethod 另外,它可以不用传参。

总结,这次总结得挺乱的,因为知识的多,有点赶,就显得凌乱。当然,也是学到很多,同时心里有些浮躁,稳住,加油啦!
以上是关于小小总结,写得有些乱的主要内容,如果未能解决你的问题,请参考以下文章