数据处理
Posted wolykos
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据处理相关的知识,希望对你有一定的参考价值。
数据导入可见:《Python之Pandas知识点》
此文图方便,就直接输入数据了。
import pandas as pd
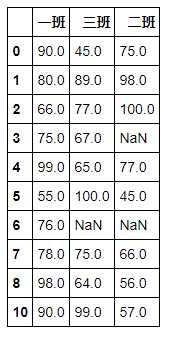
df = pd.DataFrame({‘一班‘:[90,80,66,75,99,55,76,78,98,None,90],
‘二班‘:[75,98,100,None,77,45,None,66,56,80,57],
‘三班‘:[45,89,77,67,65,100,None,75,64,88,99]})
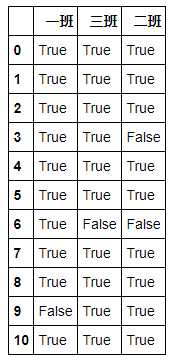
1缺失值处理
# 如何判断缺失值 df.isnull() # isna() df.notnull() # notna()
1.1删除法
DataFrame.dropna(axis=0, how=‘any‘, thresh=None, subset=None, inplace=False)
- axis:表示轴向。默认为0,表示删除所有含有空值的行。
- how:表示删除的方式。默认为any。为any的时候,表示只要存在缺失值就删除。为all的时候,表示全部是缺失值才能删除。
- subset:表示删除的主键,默认为全部。注意,使用任意主键均需要将其放入list中。且主键和axis对应。
- inplace:表示是否对原数据进行操作。默认为False,不对原数据操作。
# 删除第九行 df.fropna(axis=0, how=‘any‘, subset=[‘一班‘])
1.2定值替换法
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
- value:表示传入的定值。可为某一个值,dict,Series,DataFrame。无默认
- method:此参数存在,则不传入value。表示使用前一个非空值或后一个非空值进行缺失值填补。无默认。
- axis:表示轴向。
- inplace:表示是否对原数据进行操作。默认为False,不对原数据操作。
- limit:表示插补多少次。默认全量插补。
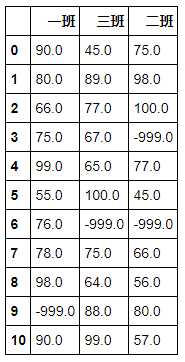
df.fillna(-999)
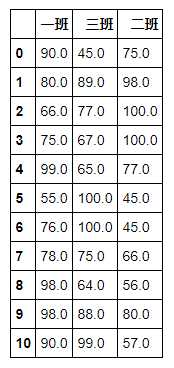
# 分别填补 df.fillna({‘一班‘:-60,‘二班‘:-70,‘三班‘:-80})
# 将每一列的空值插补为该列的均值 df.fillna(df.mean())
# 用上一个数值进行填补 df.fillna(method = ‘ffill‘)
1.3插补法
删除法简单易行,但是会引起数据结构变动,样本减少;而替换法使用难度较低,但是会影响数据的标准差,导致信息量变动。在面对数据缺失问题时,除了这两种方法之外,还有一种常用的方法——插值法。
# 默认是线性插值linear df.interpolate()
常用的插值法有线性插值、多项式插值、样条插值等。
- 线性插值是一种相对来说较为简单的插值方法,它针对已知的值求出线性方程,通过求解线性方程得到缺失值;
from scipy.interpolate import interp1d # 注意这里是数字1,不是l num = df[‘一班‘][df[‘一班‘].notnull()] # 不为空的数据 LinearInsValue1 = interp1d(linear.index, linear.values, kind=‘linear‘) LinearInsValue1(df[‘一班‘][df[‘一班‘].isnull()].index)
- 多项式插值是利用已知的值拟合一个多项式,使得现有的数据满足这个多项式(拉格朗日插值、牛顿插值等),再利用这个多项式求解缺失值;
from scipy.interpolate import lagrange LagInsValue = lagrange(linear.index, linear.values) # 没有kind形参 LagInsValue(df[‘一班‘][df[‘一班‘].isnull()].index)
- 样条插值是以可变样条来作出一条经过一系列点的光滑曲线的插值方法,插值样条由一些多项式组成,每一个多项式都是由相邻两个数据点决定,这样可以保证两个相邻多项式及其导数在连接处连续。
from scipy.interpolate import spline # sp 线 # 代码合为一行了 spline(linear.index, linear.values, xnew=df[‘一班‘][df[‘一班‘].isnull()].index)
以上是关于数据处理的主要内容,如果未能解决你的问题,请参考以下文章