大端BigEndian小端LittleEndian与字符集编码
Posted williamjie
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大端BigEndian小端LittleEndian与字符集编码相关的知识,希望对你有一定的参考价值。
BigEndian(大端):低字节在高内存地址
LittleEndian(小端):低字节在低内存地址
也就是看低字节在高内存地址还是低内存地址,也就是看低字节在前还是高字节在前,低字节在前自然是小端,高字节在前就是大端。
所谓大小端,是指字节存储或传输时的顺序。
注:最小寻址单位是指特定的计算机硬件机构所支持的最小数据访问块大小。以
个人电脑为例,内存机构的最小寻址单位为1个字节(1 Byte)即8个bit。也就
是说,你无法单独访问1 bit的信息或者任意小于1字节的信息。个人电脑中的硬
盘部分最小访问单位为4KB(依厂商不同而有所区别,较早的硬盘该单位比较
小),这就是通常所讲的“硬盘按块寻址”,一块既指4KB的数据。
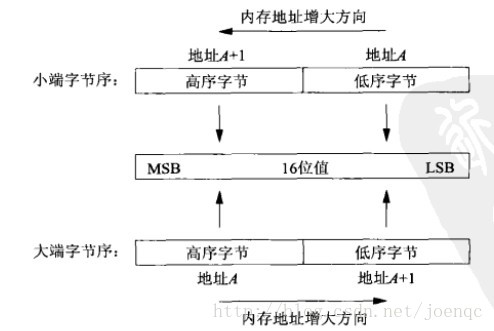
例如:
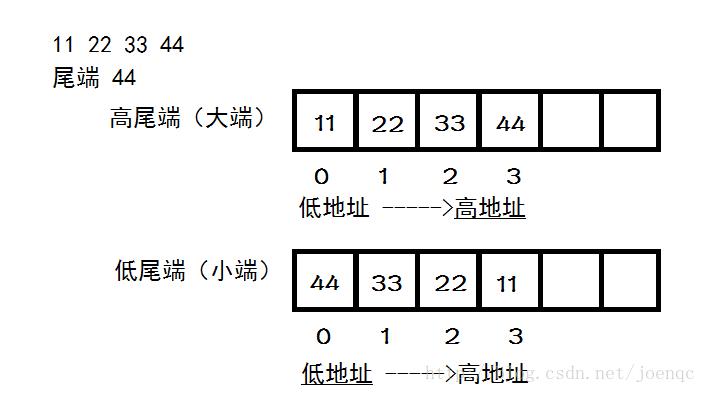
大小端字节序与字符集编码之间的联系就是BOM,即 Byte Order Mark,字节顺序标记。例如可以以utf16编码将数据存储到文件中,在文件头部,会存入BOM,以表示在读取数据的时候是按照大端读取还是小端读取。FEFF表示大端,FFFE表示小端。而utf-8由于其特殊的变长编码规则,导致它是可以自解释的,所以以utf-8编码存储、传输数据时可以选择不加入BOM,同时这也是推荐的方式。
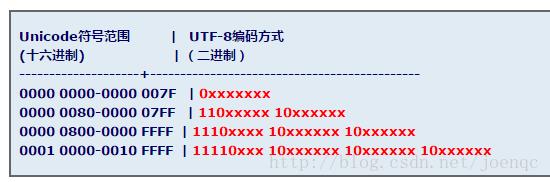
因为utf-8代码单元为1字节,每个字节高位都有标识,每当读到一个字节时,可以根据其高位进行判断。如上图,如果读到0开头的字节,则此字节单独编码;如果读到110、1110、11110开头的字节,则接着读取对应个数的字节;如果读到10开头的字节,则继续读取,读到110、1110、11110开头的字节为止。
由此看来,无需BOM并且可以无视字节序。只是utf-8解码程序稍稍麻烦一些。
而utf-16编码方式的代码单元为2字节,则一个代码单元内的两个字节的先后顺序对读取会产生影响,必须指定字节序,否则只能靠猜。
参考:
http://blog.csdn.net/joenqc/article/details/54891731
http://www.cnblogs.com/skywang12345/p/3360348.html
http://www.360doc.com/content/15/0915/14/26654031_499295872.shtml
在网络传输中,tcp协议采用大端字节序,也就是先接收到的字节为数据的高位。在不同的操作系统平台中,内存采用的字节序可能不同,x86和一般的OS(如windows,FreeBSD,Linux)使用的是小端模式。但比如Mac OS是大端模式。在不同平台之间进行网络传输时,需要进行特殊的转换,详见
在java中,通过 ByteOrder.nativeOrder() 方法可以判断当前平台采用的时大端字节序还是小端字节序。
public static ByteOrder nativeOrder() {
return Bits.byteOrder();
}
static ByteOrder byteOrder() {
if (byteOrder == null)
throw new Error("Unknown byte order");
return byteOrder;
}
static {
long a = unsafe.allocateMemory(8);
try {
unsafe.putLong(a, 0x0102030405060708L);
byte b = unsafe.getByte(a);
switch (b) {
case 0x01: byteOrder = ByteOrder.BIG_ENDIAN; break;
case 0x08: byteOrder = ByteOrder.LITTLE_ENDIAN; break;
default:
assert false;
byteOrder = null;
}
} finally {
unsafe.freeMemory(a);
}
}
主要实现为static静态方法,首先为long分配了8个字节内存,然后为long分配了值,之后拿出long的第一个字节,如果为数据的高位,那么平台采用的是大端字节序,如果为数据的低位,那么平台采用的时小端字节序。
以上是关于大端BigEndian小端LittleEndian与字符集编码的主要内容,如果未能解决你的问题,请参考以下文章