低版本ie保存文件时,文件名过长被截断
Posted muliang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了低版本ie保存文件时,文件名过长被截断相关的知识,希望对你有一定的参考价值。
在工作中有一个下载文件的功能,遇到一个低版本ie保存文件时,文件名过长被截断的问题。
asp.net MVC下载文件代码:
1 HttpWebRequest request = (HttpWebRequest)WebRequest.Create(downloadFilePath); 2 request.KeepAlive = false; 3 WebResponse response = request.GetResponse(); 4 Stream stream = response.GetResponseStream(); 5 return File(stream, "application/octet-stream" , HttpUtility.UrlEncode(downloadFileName, System.Text.Encoding.UTF8).Replace("+", "%20"));
开始时,将文件名用utf-8编码,通过查看响应标头,可以看到完整的utf-8编码后的文件名。但是在保存时,如果文件名过长,文件名会从前面被截断
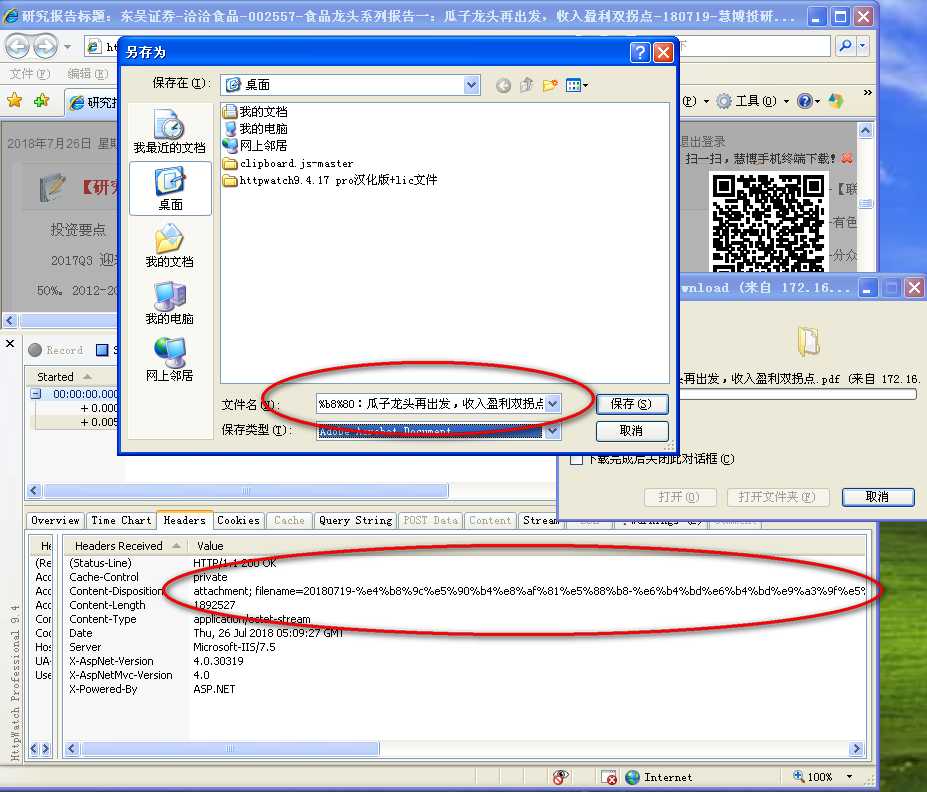
修改后的下载文件代码:
1 HttpWebRequest request = (HttpWebRequest)WebRequest.Create(downloadFilePath); 2 request.KeepAlive = false; 3 WebResponse response = request.GetResponse(); 4 List<byte> bytes = new List<byte>(); 5 using (Stream stream = response.GetResponseStream()) 6 { 7 int temp = stream.ReadByte(); 8 while (temp != -1) 9 { 10 bytes.Add((byte)temp); 11 temp = stream.ReadByte(); 12 } 13 } 14 Response.Clear(); 15 //设置响应头编码为gb2312,如果直接返回UTF-8编码的文件名,低版本ie保存文件时,如果文件名过长,会将文件名前面部分截断 16 //设置响应头编码为gb2312后文件名如果长太多,低版本ie保存文件时,仍会截断 17 Response.HeaderEncoding = System.Text.Encoding.GetEncoding("gb2312"); 18 Response.AddHeader("Content-Disposition", "attachment; filename="" + downloadFileName + """); 19 Response.ContentEncoding = System.Text.Encoding.UTF8; 20 Response.ContentType = "application/octet-stream"; 21 Response.BinaryWrite(bytes.ToArray()); 22 Response.Flush(); 23 Response.End(); 24 return new EmptyResult();
修改后将响应标头的编码设置为gb2312,文件名不进行编码
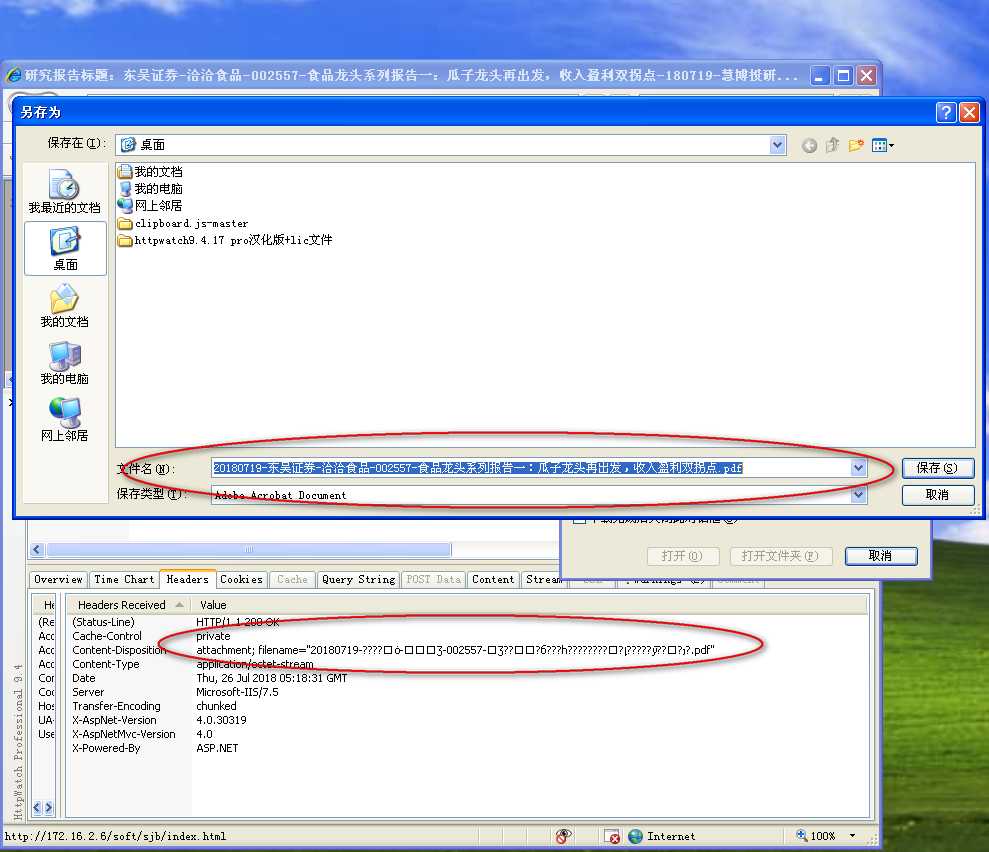
对比可以看到到,这次响应标头中的文件名长度变短了,所以保存时文件名未被截断。这种方式只是相对于utf-8编码方式来说,减少了响应标头中的文件名长度,但是如果文件名长度更长之后,仍可能出现文件名被截断的情况。
以上是关于低版本ie保存文件时,文件名过长被截断的主要内容,如果未能解决你的问题,请参考以下文章